最近在学习cs224n: Natural Language Processing with Deep Learning课程时,对RNN、LSTM和GRU的原理有了更深一层的理解,对LSTM和GRU如何解决RNN中梯度消失(Gradient Vanishing)的问题也有了新的认识,于是写下本文。
RNN
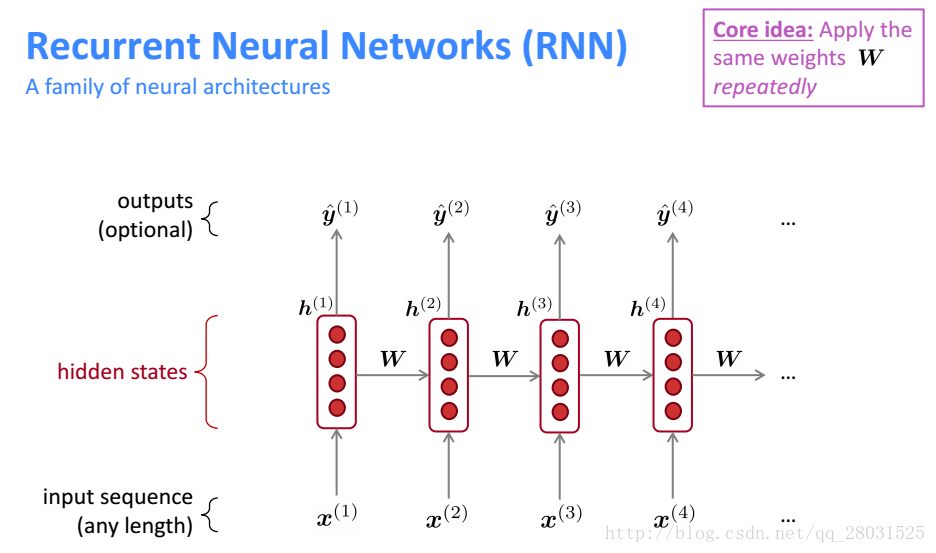
Gradient Vanishing
RNN中容易出现Gradient Vanishing是因为在梯度在向后传递的时候,由于相同的矩阵相乘次数太多,梯度倾向于逐渐消失,导致后面的结点无法更新参数,整个学习过程无法正常进行。
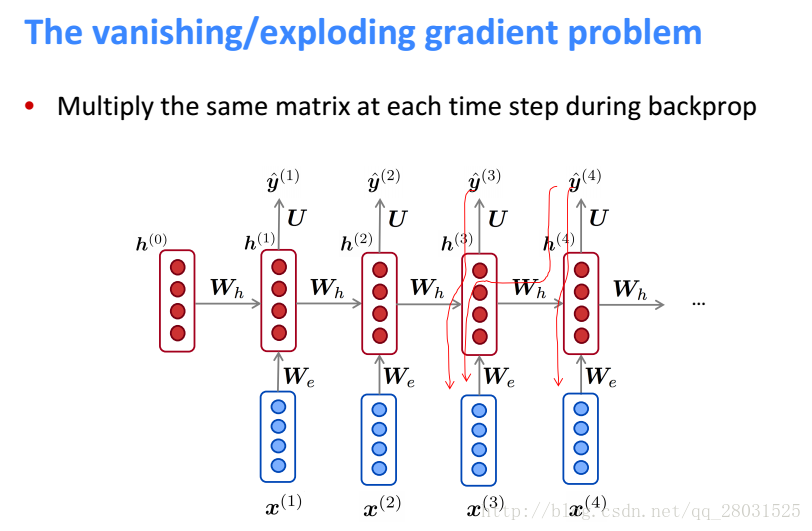
Gradient Vanishing的推导如下
整个序列的预测是之前每个时刻的误差之和,而每个时刻t的预测误差又是之前每个时刻的误差之和(损失函数的一种定义方式,也可在每个时刻计算交叉熵损失函数并在序列上平均)。

此时
是在
的时间域上应用链式法则,是一个连乘的形式,长度为时间区域的长度。

记
和
分别为矩阵和向量的范数(L2),由于使用了sigmoid激活函数,所以
的矩阵范数最大为1,因此得到下面更松弛的上界。指数项
在显著的小于1或者大于1的时候,经过
次乘法之后将于倾向于0或者无限大,也即梯度消失和梯度爆炸。

减缓梯度消失
For vanishing gradients: Initialization + ReLus!(减缓梯度消失的方法:初始化 + ReLu)
Initialize W to identity matrix I(Rather than random initialization matrix) and f(z) = rect(z) = max(z,0)(初始化参数矩阵为单位矩阵,以语言模型为例这样的初始化效果就是上下文向量和词向量的平均)
防止梯度爆炸
一种暴力的方法就是,当梯度的大小超过某个阈值的时候,将其缩放到某个阈值。虽然在数学书缺乏严谨的推导,但是实践效果挺好。
其直观解释是,在一个只有一个隐藏节点的网络中,损失函数和权值w偏值b构成error surface,其中如下图表示有一张图:
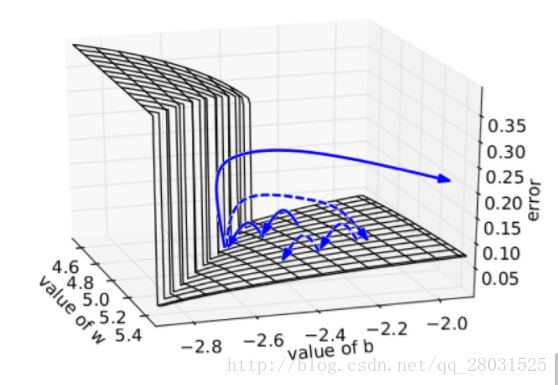
每次迭代梯度本来是正常的,一次一小步,但遇到这堵墙之后可能突然梯度爆炸到非常大,可能指向一个莫名其妙的地方(实线长箭头)。但缩放之后,能够把这种误导控制在可接受的范围内(虚线短箭头)。
但这种trick无法推广到梯度消失,因为你不想设置一个最低值硬性规定之前的信息都相同重要地影响当前的输出。
GRU
GRU分为Reset gate(重置门)和Update gate(更新门)
由: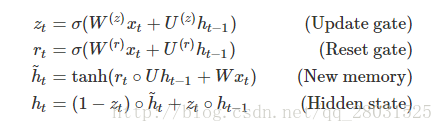
Reset Gate(重置门):控制是否遗忘之前的记忆。当reset gate = 0时,遗忘之前的信息
。
Update Gate(更新门):控制之前记忆留存的比例。通过
进行调节。
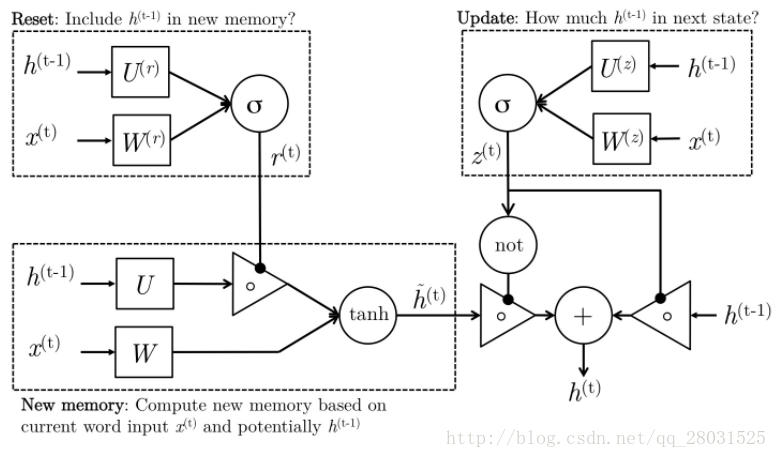

Question: How do GRU fix vanishing gradient problem?(GRU如何解决梯度消失的问题?)
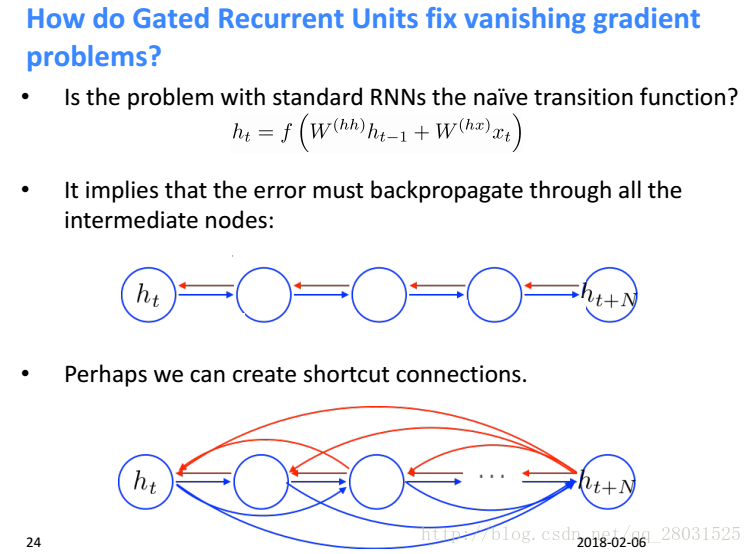
1. 在标准的RNN中,梯度是严格的按照所有的中间节点流动的,而GRU在网络中创造了适应性的短连接(create adaptive shortcut connection)。在GRU中,可以选择性的遗忘和记忆此前的信息,在梯度的流动中做了短连接,避免梯度计算中的大量累积。
2. 通过GRU公式,
,其中
是update gate的值,
是当前时刻的新信息。为了方便可做简化:
,可以看到
和
此时是线性关系,不再是RNN中
的乘积关系,因此梯度在计算的时候不再是连乘关系。梯度在中间节点线性流动,就会保持很长时间的记忆。
LSTM
LSTM分为input gate(输入门),forget gate(遗忘门),和output gate(输出门)
由:
Input Gate(输入门):表示当前的词语是否值得保留下来。在上述公式5中Final memory cell中体现。
Forget Gate(遗忘门):表示过去的记忆是否忘记。当forget gate=0时,遗忘过去的记忆。
Output Gate(输出门):表示当前的记忆应该被放大的倍数,用于将最终的记忆与隐状态分离,因为记忆c(t)中的信息不是都需要放到隐状态中,隐状态是个很重要且使用很频繁的东西。
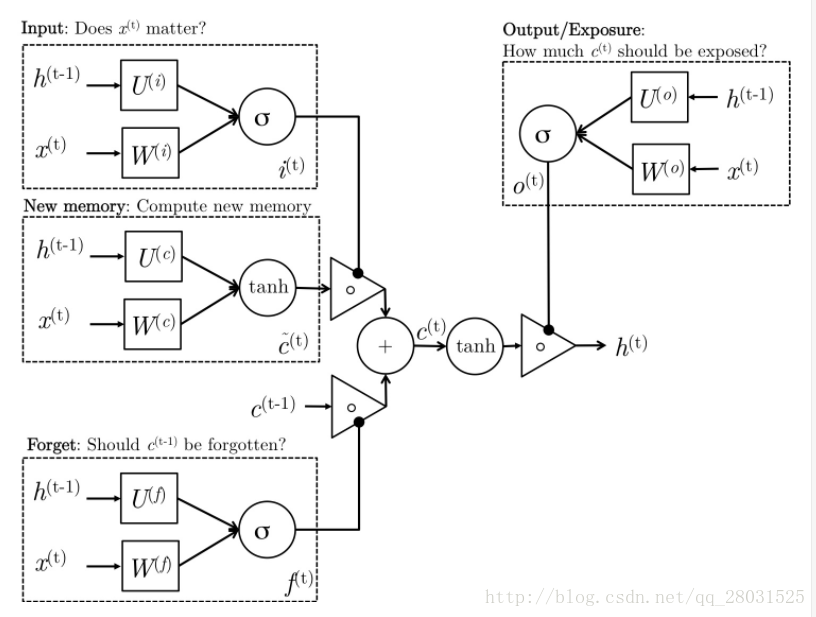
Question1: How do LSTM fix vanishing gradient problem?(LSTM如何解决梯度弥散的问题?)
1. 在标准的RNN中,梯度是严格的按照所有的中间节点流动的,而LSTM在网络中创造了适应性的短连接(create adaptive shortcut connection)。在LSTM中,可以选择性的遗忘和记忆此前的信息,在梯度的流动中做了短连接,避免梯度计算中的累积。
2. 通过公式也可以看出,在LSTM中,
,其中
是此前的信息,
是当前时刻的新信息,
是最终的信息。可以看到
和
此时是线性关系,不再是RNN中的乘积关系,因此梯度在计算的时候不再是连乘关系,梯度以线性在中间节点流动,因此就会保证很长时间的记忆。
Question2: why tanh in
?
课程中,Manning也没给出很具体的原理,但是Richard认为因为
为线性运算,为了增加系统的非线性于是采用了tanh。