一、前言
GRU是LSTM的一种变体,综合来看:
1、两者的性能在很多任务上不分伯仲。
2、GRU 参数相对少更容易收敛,但是在数据集较大的情况下,LSTM性能更好。
3、GRU只有两个门(update和reset),LSTM有三个门(forget,input,output)
LSTM还有许多变体,但不管是何种变体,都是对输入和隐层状态做一个线性映射后加非线性激活函数,重点在于额外的门控机制是如何设计,用以控制梯度信息传播从而缓解梯度消失现象。
二、结构
1、LSTM
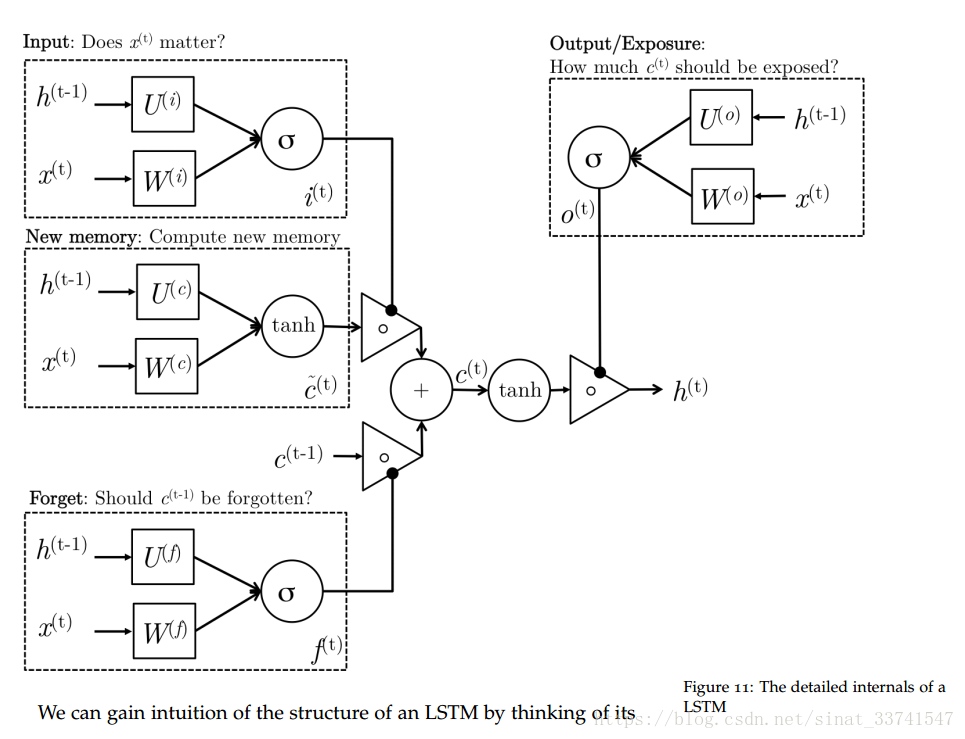
关于LSTM的网络上有许多介绍,这里贴一下网络结构图作为对比说明:
LSTM作为RNN的变体,设计了input gate、forget gate和output gate对长期信息与当期信息的进行处理,以达到维持长期依赖信息的作用,公式如下:
从结构上来看,input gate负责控制new memory,即输入信息,forget gate负责控制上一轮的memory,即长期信息,output gate对前两者的激活信息进行控制,输出h,即当前隐藏层信息。

2、GRU
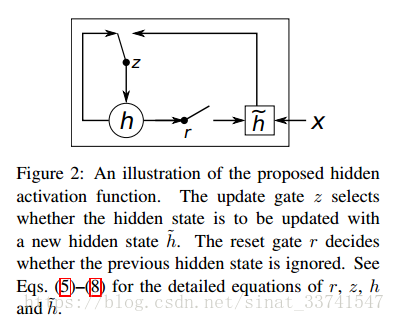
GRU最早由:Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation,这篇论文提出,论文中对GRU的结构图描述如下:
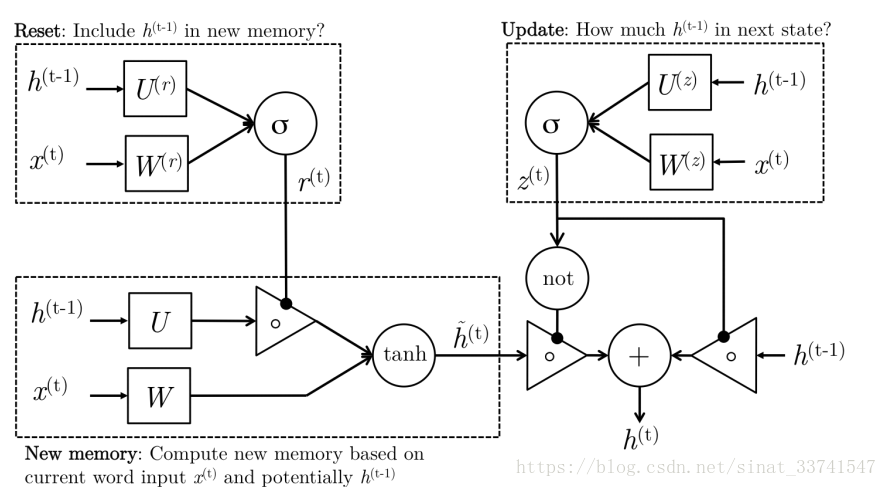
简单描述是将LSTM的三个门控进行改变,将input与forget gate合并为update gate,而output gate变为reset gate,用下边的结构图作为比较:
从结构看,reset gate直接在new memory处对上一层的隐层信息进行处理,控制h(t-1)的信息存在,所以这里update gate是对输入信息的控制得到当前层隐层状态,详细公式如下:
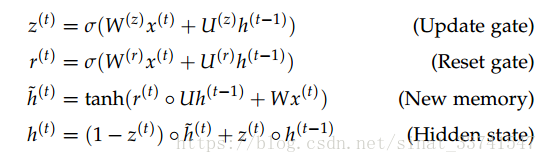
(1)符号
z:update gate
r:reset gate
h~:候选隐藏状态
h:隐藏状态
t:时间
(2)重置门和更新门
σ 是 sigmoid 激活函数,取值范围会在 0 到 1 之间。W 和 U 是需要学习的权重矩阵,X是输入,h(t-1)是上一刻的隐藏状态。所以每个门的最后结果也是 0 到 1 之间。
(3)候选隐藏状态
候选隐藏状态只跟输入、上一刻的隐藏状态 h(t-1)有关。这里的重点是,h(t-1)是与 r 重置门相关的。r 的取值是在 0 到 1 之间,如果趋近于 0,那上一刻的信息就被遗忘掉了。
(4)当前隐藏状态
当前隐藏状态取决于 h(t-1) 和 h~。如果 z 趋近于 0,那表示上一时刻的信息被遗忘;如果 z 趋换于 1,那表示当前的输入信息被遗忘;其他则表示不同的重要程度。
综上,GRU 主要是用来解决遗忘问题的,也就是在反向传播中的梯度消失问题。
三、引用
1、Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
2、https://cs224d.stanford.edu/lecture_notes/LectureNotes4.pdf