LSTM BASICS
understand the benefits and problems it solves, and its inner workings and calculations.
1.The Problem to be Solved
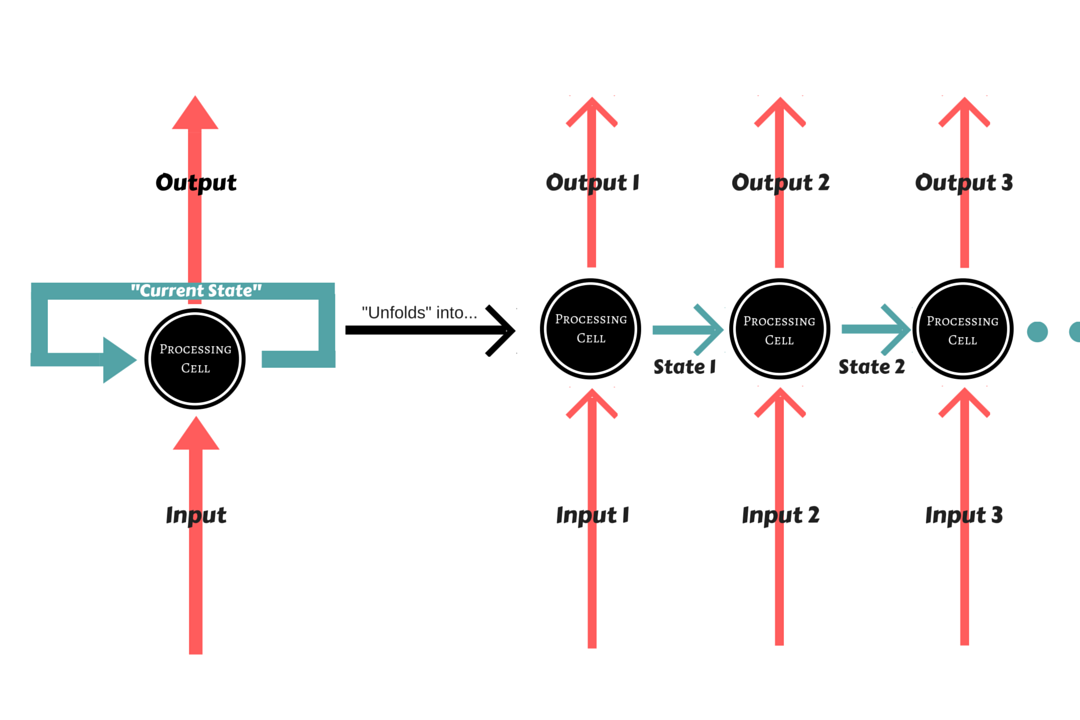
RNN’s Problem
computationally expensive to maintain the state for a large amount of units;
very sensitive to changes in their parameters;
Exploding Gradient and Vanishing Gradient;
2.Long Short-Term Memory
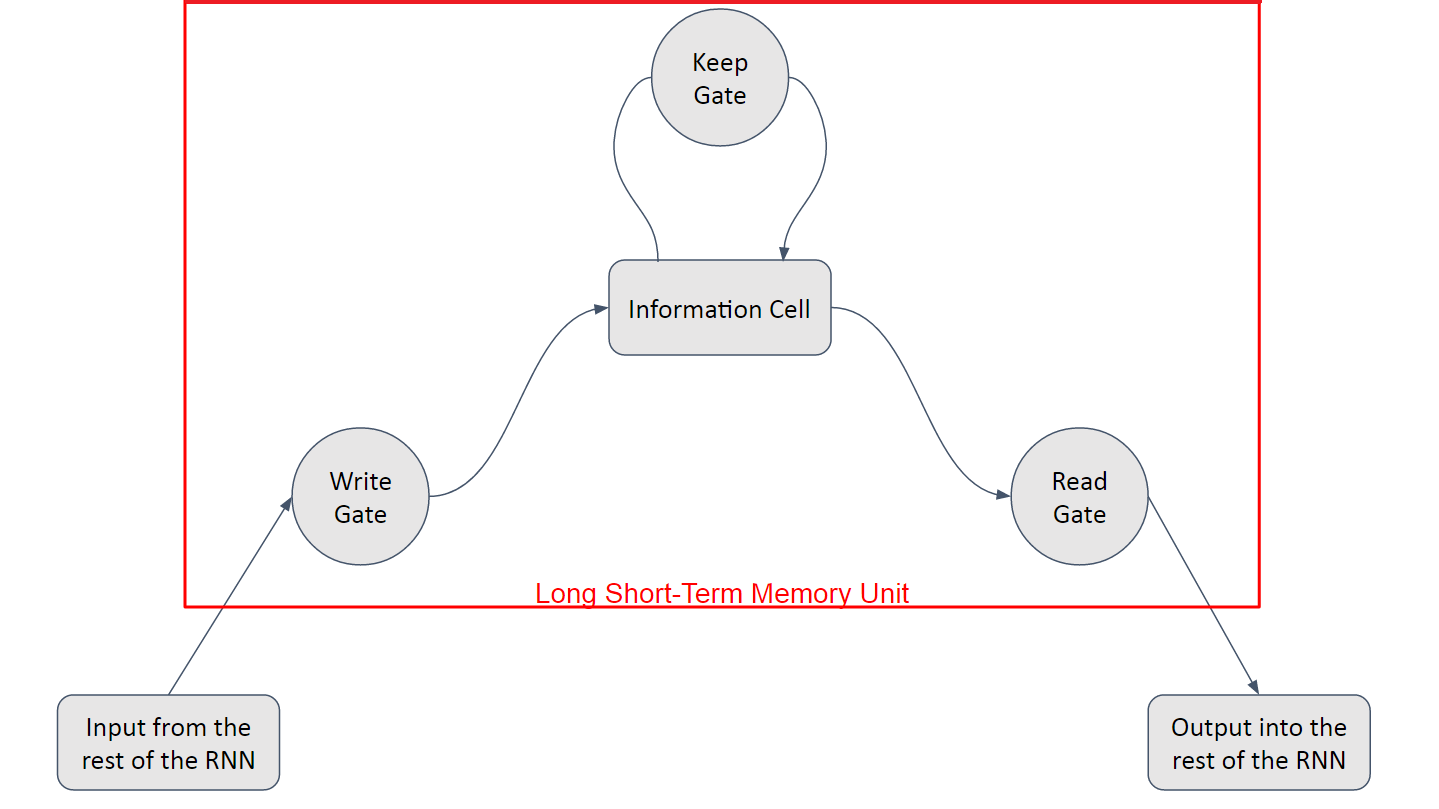
you have a linear unit, which is the information cell itself, surrounded by three logistic gates responsible for maintaining the data.the “Input” or “Write” Gate, which handles the writing of data into the information cell, the “Output” or “Read” Gate, which handles the sending of data back onto the Recurrent Network, and the “Keep” or “Forget” Gate, which handles the maintaining and modification of the data stored in the information cell.
3.RNN with LSTM

4.an usual flow of operations for the LSTM unit

First off, the Keep Gate has to decide whether to keep or forget the data currently stored in memory. It receives both the input and the state of the Recurrent Network, and passes it through its Sigmoid activation. A value of 1 means that the LSTM unit should keep the data stored perfectly and a value of 0 means that it should forget it entirely.
Consider
as the incoming (previous) state,
as the incoming input, and
,
as the weight and bias for the Keep Gate. consider
as the data previously in memory.

Then, the input and state are passed on to the Input Gate, in which there is another Sigmoid activation applied. Concurrently, the input is processed as normal by whatever processing unit is implemented in the network, and then multiplied by the Sigmoid activation’s result, much like the Keep Gate. Consider and as the weight and bias for the Input Gate, and the result of the processing of the inputs by the Recurrent Network.

is the new data to be input into the memory cell. This is then added to whatever value is still stored in memory.
is the candidate data which is to be kept in the memory cell.what would happen if the keep Gate was set to 0 and the Input Gate was set to 1:
The old data would be totally forgotten and the new data would overwrite it completely.
For the output gate,To decide what we should output, we take the input data and state and pass it through a Sigmoid function as usual. The contents of our memory cell, however, are pushed onto a Tanh function to bind them between a value of -1 to 1. Consider and as the weight and bias for the Output Gate.

And that is what is output into the Recurrent Network.
5.why all three gates are logistic?
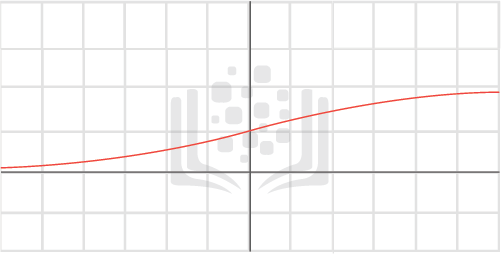
(1)it is very easy to backpropagate through them.
(2)solves the gradient problems by being able to manipulate values through the gates themselves – by passing the inputs and outputs through the gates, we have now a easily derivable function modifying our inputs.
(3)In regards to the problem of storing many states over a long period of time, LSTM handles this perfectly by only keeping whatever information is necessary and forgetting it whenever it is not needed anymore.

Deep Learning with TensorFlow IBM Cognitive Class ML0120EN
ML0120EN-3.1-Review-LSTM-MNIST-Database.ipynb