版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/NovaSliver/article/details/79449973
个人见解,大家看看,问题有则改之,共同进步,学习过程中参考的文章均超链接到原文了
RNN的应用场景主要是用来处理大量的输入序列集数据的,传统神经网络采用输入层-隐含层-输出层(InputLayer-Hidden Layer-Output Layer)各层之间全连接,层内节点无连接;而在RNN中,隐含层之间是存在一定的连接的,这意味着每一个输出和上一个输出之间是存在一定联系的,具体的表现就是网络会对前面的信息进行记忆并应用于当前输出的计算中。这个操作理论上是可以对任意长度的序列进行处理,但实际上我们为了降低复杂度往往只选择前面的几个状态。
当然RNN的问题也是存在的:梯度消失和梯度爆炸;我对梯度消失的理解是:过去的不能影响将来,将来的也不能影响过去;也就是说,先前的时间步往往并不能到足够远的时间步来影响网络。而梯度爆炸则是一开始过去的时间步对后面时间步影响过大,导致权值越来越大使得网络变得不稳定。在极端情况下,权重的值变得非常大,以至于溢出,导致 NaN 值。
而相对RNN来说,
LSTM
则是在RNN的基础上加入了门的概念,使得整个过程和人的思维过程更为相近:LSTM将RNN中隐藏层中加入了一个对信息处理的单元——这个单元除了RNN原先简单的tanh函数以外还有几个sigmoid函数共同作用来完成LSTM的功能。对于RNN来说,每个隐藏层单元之间的状态是连续的,LSTM也不例外;而为了让这些插入的sigmoid函数作用于状态,我们需要将生成的权值与状态之间进行pointwise乘法运算。第一个sigmoid函数的作用是遗忘,用来舍弃部分不需要的信息(即通过ht-1与xt输出一个0到1的数值给隐藏层单元状态ft,0是完全舍弃,1是完全保留);
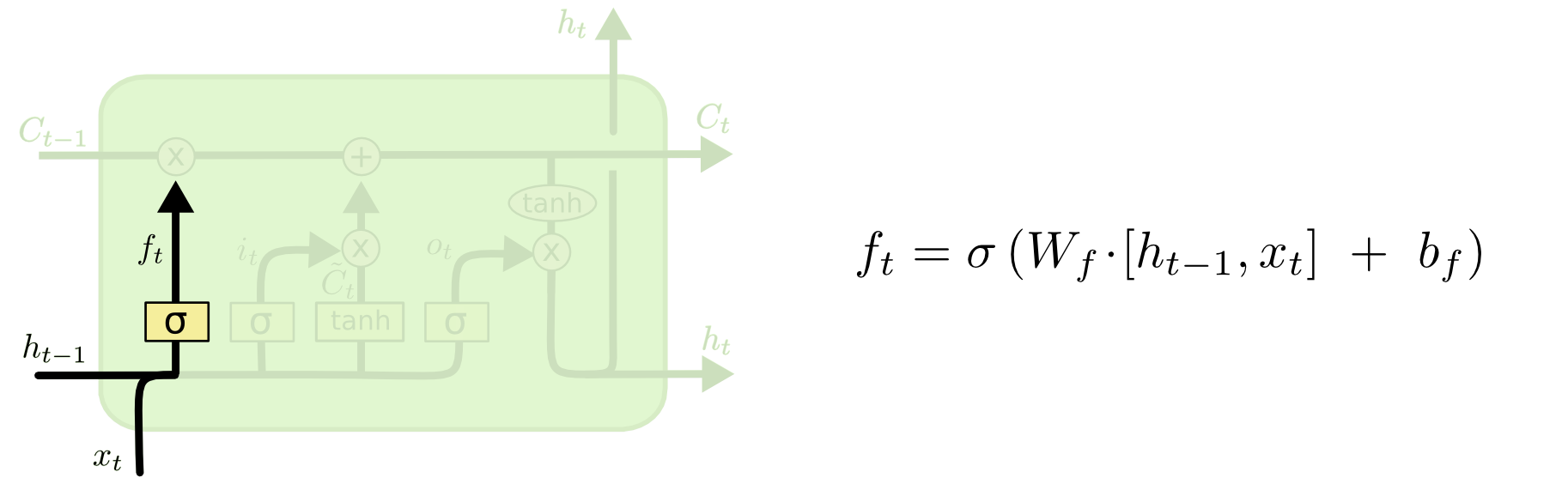 接着是更新门,这里由两部分组成,一个是sigmoid函数用来决定什么致我们要更新,另一个则是tanh函数创建一个新的候选值向量~Ct
;
接着是更新门,这里由两部分组成,一个是sigmoid函数用来决定什么致我们要更新,另一个则是tanh函数创建一个新的候选值向量~Ct
;
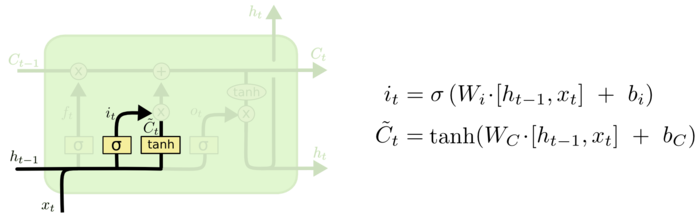
这时我们进行更新,我们将两者进行乘法后,再将从遗忘门出来状态与我们新的候选值向量相加来完成对Ct-1更新至Ct这一过程;最后的时候,我们需要确定输出什么值,这个相当于我们对这个隐藏层单元的状态做一个处理之后进行复制一份传给下一个隐藏层单元,具体操作就是将状态通过tanh进行处理,并将处理后的数据和先前ht-1与xt两项进行sigmoid处理所生成的ot相乘以获得我们想要输出的那部分,即ht并输出给下一个隐藏层单元。
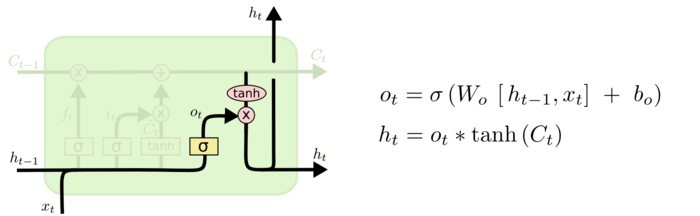
这样就算是一个LSTM中一个隐藏层单元所需要进行的操作了。当然宏观上来讲,其实说白了就是单元状态与上一个输出的同时传导,有选择的(避免梯度爆炸)将我们需要传递的信息传达到后面的隐藏层单元(避免梯度消失),可以说这样算是解决了RNN上两个令人头疼的问题了。