转自:http://deeplearning.net/tutorial/lstm.html
在传统的递归神经网络中,在梯度反向传播阶段,梯度信号可以被与经常隐藏层的神经元之间的连接相关联的权重矩阵相乘,从而得到大量的时间(如时间步数)。这意味着,转换矩阵中权重的大小对学习过程有很大的影响。
如果这个矩阵中的权重很小(或者,更正式地说,如果权重矩阵的主要特征值小于1.0),它就会导致一个称为消失梯度的情况,梯度信号变得非常小,学习要么变得非常慢,要么完全停止工作。它还可以使学习数据中长期依赖关系的任务变得更加困难。相反,如果这个矩阵中的权值很大(或者,如果权重矩阵的主特征值大于1.0),那么它就会导致梯度信号太大,从而导致学习偏离。这通常被称为爆炸梯度。
这些问题是LSTM模型背后的主要动机,它引入了一个称为内存单元的新结构(见下图1)。一个内存单元由四个主要元素组成:一个输入门,一个具有自循环连接的神经元(一个连接),一个forget gate和一个output gate。自循环连接的权重为1.0,并确保了,除了任何外部干扰外,内存单元的状态可以从一个时间步骤持续到另一个时间。这些gate可以调节存储单元(memory cell)自身与环境之间的相互作用。input gate可以允许传入信号改变memory cell的状态或阻止它。另一方面,input gate可以允许memory cell的状态对其他神经元产生影响或阻止它。最后,forget gate可以调节内存单元的自循环连接,允许单元格在需要时记住或忘记它的前一个状态。
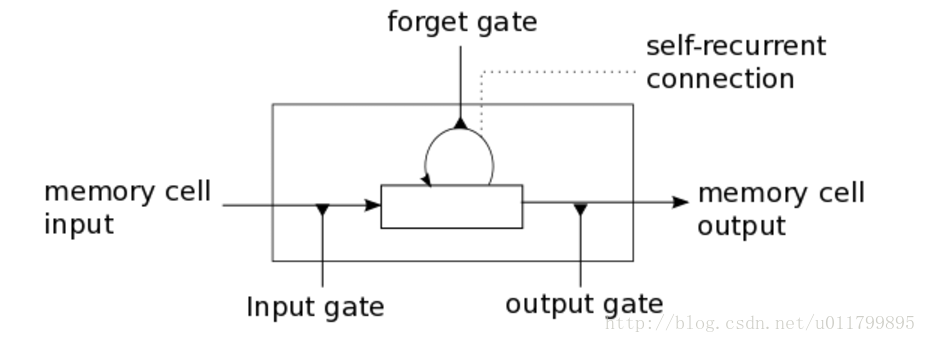
下面的方程式描述了在每一个时间t步骤中如何更新一层存储单元。
- x_t is the input to the memory cell layer at time t
- W_i, W_f, W_c, W_o, U_i, U_f, U_c, U_o and V_o are weight matrices
- b_i, b_f, b_c and b_o are bias vectors
首先,我们计算i_t、输入门、t时刻存储单元状态的候选值:
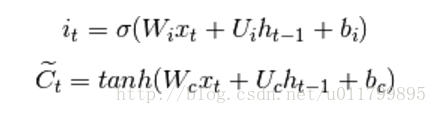
然后计算t时刻激活函数值:
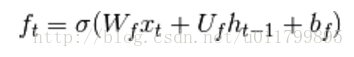
计算存储单元新状态:
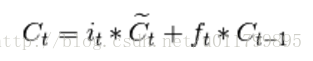
我们可以计算出它们的output gates的值:
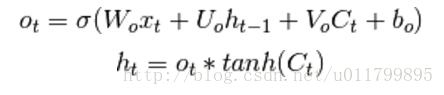
理解 LSTM 网络:
http://www.jianshu.com/p/9dc9f41f0b29
Keras中文文档—LSTM:
https://keras-cn.readthedocs.io/en/latest/layers/recurrent_layer/#lstm