&论文概述
论文题目:FCOS:Fully Convolutional One-Stage Object Detection
作者&出处:Zhi Tian, Chunhua Shen, Hao Chen, Tong He|| The University of Adelaide, Australia
获取地址:https://arxiv.org/abs/1904.01355
&总结与个人观点
提出anchor-free以及proposal-free的one-stage检测器FCOS。且FCOS于流行的基于anchor的one-stage检测器,如RetinaNet,YOLO和SSD有着可媲美的结果,同时有着更低的设计复杂度。FCOS完全避免了于anchor相关的计算以及超参数,以及实现了per-pixel prediction fashion的目标检测应用,于其他的密集预测任务如语义分割相似。在one-stage检测器中,FCOS达到了最优的性能。同时在two-stage检测器中FCOS可以被用作RPN使用。
这篇论文提出的FCOS的网络架构并不新颖,几乎是FPN的变种,同时center-ness仅相当于一个注意力机制或者说是对loss的加权。容易理解。
&贡献
1) Proposal-free以及anchor-free,减少了参数,避免了与anchor相关的复杂计算如IoU及anhcor与ground truth的匹配,使得速度更快、内存消耗更少、训练更简单;
2) 在无额外添加的情况下,在one-stage检测器中取得最好的结果;可以在two-stage检测器中将FCOS作为RPNs使用,性能由于原先的RPN模块。
&拟解决的问题
问题:使用anchor出现的问题、将FCN应用到目标检测中
分析:
1) 基于anchor的方法的缺点:
l 检测性能与anchor的size、aspect ratios及数量密切相关,因此这些超参数需要根据基于anchor的检测器细心调节;
l 即便细心调整,由于尺度、aspect ratios均是固定的,检测器在处理大的形状多样性,尤其是小目标的目标候选时会很困难;同时,预设定的anchor boxes也阻碍了检测器的泛化性能,在处理不同的目标size和aspect ratio的检测任务时,需要重新设计;
l 为了获得高召回率,基于anchor的检测器需要在输入图片中紧密地放置anchor,而其中大部分为negtive anchor,导致positive anchor与negative anchor间的不平衡;
l Anchor需要进行复杂的计算,如IoU以及anchor与ground truth的匹配。
2) FCN应用到目标检测:
基于FCN的框架直接在特征图的一层中预测4D的而向量(到bbox四边的距离)外加类别,然而,为了解决不同size的bbox,DenseBox裁剪且在统一的尺度上训练图片,因此不得不使用图像金字塔,违背了FCN所有卷积只计算一次的原则。
此外,这些方法大多应用于特殊的目标检测,如场景文本检测或人脸检测,因此,当应用于普通的带有高度重叠的目标检测时不会有好的性能。而且高度重叠的目标也会导致intractable ambiguity,即不清楚应当用哪个bbox来对重叠的部分进行回归。
| YOLOv1 |
CornerNet |
DenseBox |
FCOS |
| 通过目标中心附近的点来预测bbox。只有目标中心附近的点被认为能够生成更高质量的检测结果,而导致YOLOv1的低召回率 |
|
|
FCOS利用真实bbox中的所有点来预测bbox,且低质量的检测bbox通过“center-ness”分支处理。因此,FCOS能够有可与基于anchoe的检测器相比的召回率 |
|
|
要求更多复杂的后处理过程来对corners进行分组,为了分组还学习额外的距离度量标准(embedding) |
|
|
|
|
|
由于其在处理遮挡的bbox上的困难以及低recall,不适合用于普通的目标检测 |
在使用多层FPN预测时可解决大部分问题 |
3) 方法本身产生的问题:
此方法可能在原理target object的location上生成一些低质量检测的bbox。
为消除这些低质量的检测结果,引入center-ness分支。
&框架及主要方法
1、网络的主要框架

此方法与FPN类似,前面一部分采用了FPN的结构,与之略有不同的是,从P5进行下采样操作得到P6,P7,同时在预测时在分类分支上添加一个并行的center-ness分支。
2、FCOS的流程
1) 定义Fi(【H,W,C】)是骨干CNN中的第i层特征图,s是到当前层为止的总的stride,{Bi}是ground truth的bboxes,Bi=(x0(i), y0(i), x1(i), y1(i), c(i)),将特征图Fi中的每个location(x,y)映射回输入图像中为,作为其感受野的中心。不同于基于anchor的检测器,将输入图像的位置作为anchor的中心,同时参考这些anchor来回归目标的bbox;直接回归在当前location的bbox,即将locations视为训练样本而不是基于anchor检测器的anchor boxes。
2) 如果(x, y)在任一ground truth box中,将其视为正样本,同时c*为该box的类别,否则视为负样本,c*=0即视为背景。对每个location回归其l*,t*,r*,b*,即到bbox四边的距离,如下图所示。若一个location在多个bbox中,则认为其是有歧义的样本(对此部分的处理可见第3部分)。若location在Bi中,相应的计算如下图右所示。


FCOS利用尽可能多的前景样本来训练回归器。这也与基于anchor的检测器不同,其仅考虑与ground truth由足够高的IoU的anchor。这可能是FCOS优于其基于anchor的部分的原因之一。
3) 响应训练目标,最终的层预测分类标签的80维向量p以及4维的t=(l, t, r, b) bbox坐标。此外训练C个二分类分类器替换多类别分类器。由于回归目标总是正的,在最上面的回归分支中使用exp(x)来映射到任意实数(0, ∞)。FCOS相对于每个location使用9个anchor的检测器来说减少到1/9的输出变量。
4) Loss function定义如下:

Lcls是focal loss,Lreg是IoU loss。Npos表示正样本的数量。
3、Mutiple-level prediction FPN的使用
使用PFN的多层预测主要解决两个问题:
1) CNN中的最后的特征图的大的stride(如16)造成相对较低的best possible recall(BPR)。
在基于anchor的检测器中,由较大的stride导致的低召回率可通过降低positive anchor的IoU得分处理;在FCOS中,最初可能认为BPR低于基于anchor的检测器是因为不能召回由于大的stride导致在最终的特征图中没有location的目标。
然而,经过实验表明,即便时使用较大的stride,基于FCN的FCOS仍然能够生成一个甚至优于基于anchor的检测器RetinaNet的BPR,因此BPR在FCOS中不是问题。具体如下表所示:

2) 在ground truth boxes中的遮挡导致的intractable ambiguity(难解的歧义),即不知道应该由哪个bbox对重叠的位置进行回归。
如框架中的结构图所示,在不同层级的特征图中检测不同size的目标。使用了5层特征图{P3, P4, P5, P6, P7}。其中P3, P4, P5是由C3, C4, C5通过1×1卷积外加自上而下的连接生成。P6, P7分别由P5, P6以stride为2的卷积生成,因此这些特征层的stride分别为8,16,32,64,128。
不像基于anchor的检测器,在不同的特征层中使用不同size的anchor,直接限制每个层级中bbox回归的范围。首先在每个特征层中的location上计算回归的目标l*,t*,r*,b*;如果max(l*,t*,r*,b*)>mi,或者min(l*,t*,r*,b*)<mi-1,则被视为负样本。其中mi是特征层级i能够回归的最大的距离。在此,设定m2,m3,m4,m5,m6,m7分别为0,64,128,256,512及∞。因此不同size的目标被分配到不同的特征层级中,而大多遮挡发生在不同size的目标中。如果在使用多层级预测后,一个location仍在多个ground truth boxes中,直接选取最小的ground truth作为其回归目标。下表显示了使用FPN后,有歧义样本的数量的变化情况:

Tricks:
根据论文,在不同的特征层中共享head,不仅使得检测器的参数更有效,同时提升了检测性能。不同的特征层级要求回归不同的size范围,因此在不同的特征层中使用相同的head是不合理的,因此使用exp(six)替换原先的exp(x),si是一个可训练的标量,不同的层级中可以自动调整,最终提高一点性能。
4、Center-ness Branch
在使用多层级预测FPN后,FCOS与基于anchor的检测器仍有较大差距,根据分析,是由于由原理目标中心的location生成的大量低质量检测到的bbox。

添加一个与分类分支并列的分支(实验表明,center-ness分支与回归分支并列的性能会更好),来预测location的center ness。Center ness表示该location与其响应的bbox中心的归一化的距离。令l*,t*,r*,b*表示一个location,则center ness计算如下:
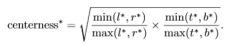
在此处使用sqrt为了减缓center ness的衰减。使用二值交叉熵定义其loss,将loss添加到损失函数中,在计算时将center ness的loss作为分类损失的权重。
下表显示了使用center-ness以及在不同地方使用产生的结果对比:

5、实验结果
下表为FCOS相比于以ResNet-50-FPN为backbone的RetinaNet的结果以及对应的采用不同的改进策略的结果对比:

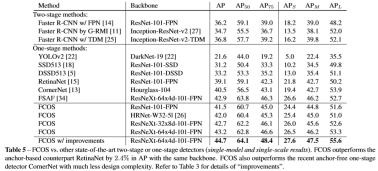
下表比较了FCOS与其他one-stage检测器的结果对比,以及Faster R-CNN在RPN部分使用不同的网络的对比结果:
下表为相对于RetinaNet以及使用不同的tricks的FCOS的结果对比:

&遇到的问题
1、为什么使用center-ness可以减少低质量的bbox?
本人理解:离得越近也就是整体的bbox越小,相应的对应于检测小目标,此时在分类loss上的给与较多的关注,而对于较大的bbox,值越小,表示在该分类loss上给与较少的关注。因此bbox相当于一个权重矩阵或者是对分类loss的注意力机制。此处所说的低质量的bbox应当是指较大的bbox,与分类损失一起,可以平衡较大的bbox与较小的bbox。
&思考与启发
从FCOS的介绍及对相关问题的处理中,可以发现FCOS并不适合低空行人检测或者密集人群检测,因为在这些问题中需要考虑的有很多都是相同尺度的目标的遮挡问题,而FCOS使用多层级的FPN预测仅可以解决不同size间的目标遮挡,在相同的特征层级处理中,仍会出现intractable ambiguity。所以使用FCOS需要视数据集而定。