Conceptos de análisis de conglomerados
El análisis de conglomerados es el proceso de agrupar objetos de datos en función de la información que se encuentra en los datos dados que describen los objetos y las relaciones.
La agrupación en clústeres es una técnica para encontrar la estructura inherente entre los datos. La agrupación en clústeres organiza todas las instancias de datos en algunos grupos similares. Estos grupos similares se denominan clústeres. Las instancias de datos en el mismo clúster son idénticas (relacionadas) entre sí y están en diferentes clústeres. Las instancias en son diferentes entre sí (no relacionadas).
El análisis de conglomerados es un tipo de aprendizaje no supervisado. A diferencia del aprendizaje supervisado, no hay clasificación o información que indique la categoría de datos en el conglomerado, sino que las muestras de la categoría de ubicación se dividen en varios conglomerados de acuerdo con ciertas reglas para revelar Hay leyes en esto.
En el modelado matemático, el análisis de conglomerados se puede aplicar en el proceso de preprocesamiento de datos. Para datos multidimensionales con estructuras complejas, el análisis de conglomerados se puede utilizar para agregar los datos y estandarizar los datos de estructura compleja. El análisis de conglomerados también se puede utilizar para descubrir dependencias entre elementos de datos, eliminando o fusionando así elementos de datos estrechamente dependientes. El análisis de conglomerados también puede proporcionar funciones de preprocesamiento para ciertos métodos de extracción de datos (como reglas de asociación y métodos de conjunto aproximado). En temas empresariales, el análisis de clusters es una herramienta eficaz para la segmentación del mercado y se utiliza para descubrir diferentes grupos de clientes, también se utiliza para estudiar el comportamiento de los consumidores y encontrar nuevos clientes caracterizando las características de los diferentes grupos de clientes, mercado potencial, etc.
Algoritmo de análisis de conglomerados
Los algoritmos de análisis de conglomerados se dividen principalmente en cinco categorías: métodos de agrupamiento basados en particiones, métodos de agrupamiento basados en jerarquías, métodos de agrupamiento basados en densidad, métodos de agrupamiento basados en cuadrículas y métodos de agrupamiento basados en modelos.
- Agrupación basada en particiones (algoritmo k-medias, algoritmo k-medoides, algoritmo k-prototipo)
- Agrupación basada en jerarquías
- Agrupación basada en densidad (algoritmo DBSCAN, algoritmo OPTICS, algoritmo DENCLUE)
- agrupación basada en red
- Agrupación basada en modelos (agrupación difusa, agrupación de redes neuronales Kohonen)
Algoritmos comunes para modelado matemático.
Hay muchos tipos de algoritmos de análisis de conglomerados. El método de agrupamiento basado en particiones es el más utilizado en el modelado matemático. Este artículo presenta principalmente el agrupamiento de K-medias.
El algoritmo de agrupamiento de k-medias divide los puntos de muestra con centroides de grupo similares en el mismo grupo calculando la distancia entre los puntos de muestra y los centroides de grupo. La distancia entre muestras se utiliza para medir la similitud entre ellas, cuanto más lejos estén las dos muestras, menor será la similitud y viceversa.
algoritmo k-medias:
- Seleccione K centroides iniciales (K debe ser especificado por el usuario). Los centroides iniciales se pueden seleccionar aleatoriamente. Cada centroide es una clase.
- Para cada punto de muestra restante, calcule la distancia euclidiana entre ellos y cada centroide, y clasifíquelos en el grupo con el centroide con la distancia más pequeña entre ellos. Calcule el centroide de cada nuevo grupo.
- Después de dividir todos los puntos de muestra, la ubicación del centroide de cada grupo se vuelve a calcular de acuerdo con la situación de división, y luego se calcula iterativamente la distancia desde cada punto de muestra al centroide de cada grupo para volver a dividir todos los puntos de muestra.
- Repita 2. y 3. hasta que el centro de masa ya no cambie o se alcance el número máximo de iteraciones.
Ventajas y desventajas del algoritmo k-medias
- El algoritmo k-means tiene un principio simple, es fácil de implementar y tiene una eficiencia operativa relativamente alta (ventajas)
- Los resultados de agrupación del algoritmo k-means son fáciles de interpretar y adecuados para agrupar datos de alta dimensión (ventajas)
- El algoritmo k-means utiliza una estrategia codiciosa, lo que resulta en una fácil convergencia local y una solución lenta en conjuntos de datos a gran escala (desventajas)
- El algoritmo k-means es muy sensible a los valores atípicos y los puntos de ruido. Un pequeño número de valores atípicos y puntos de ruido puede tener un gran impacto en el promedio del algoritmo, afectando así los resultados de agrupación (desventajas)
- La selección del centro de agrupamiento inicial en el algoritmo k-means también tiene un gran impacto en los resultados del algoritmo: diferentes centros iniciales pueden conducir a diferentes resultados de agrupamiento. En este sentido, los investigadores propusieron el algoritmo k-means++ , cuya idea es alejar lo más posible los centros del cluster inicial entre sí.
Algoritmo k-medias++:
- Seleccione aleatoriamente un punto de muestra τx1 de la muestra como el primer centro del conglomerado
- Calcule la distancia d(x) desde otros puntos de muestra x hasta el centro del grupo más cercano
- Seleccione un nuevo punto de muestra x2 para unirse al centro del grupo establecido con probabilidad
Cuanto mayor sea el valor de la distancia, mayor será la probabilidad de ser seleccionado.
- Repita 2 y 3 para seleccionar k centros de clúster
- Realice una operación de k-medias basada en estos k centros de clúster
Ventajas y desventajas del algoritmo k-means ++
- Mejorar la calidad de los puntos óptimos locales y converger más rápido (ventajas)
- En comparación con la selección aleatoria del punto central, el cálculo es mayor (desventaja)
Evaluación del análisis de conglomerados
La evaluación del análisis de conglomerados es el paso final en el proceso de agrupación.
proceso de agrupamiento
- Preparación de datos: incluida la estandarización de características y la reducción de dimensionalidad;
- Selección de características: seleccione las características más efectivas de las características iniciales y guárdelas en el vector;
- Extracción de características: formar nuevas características destacadas transformando características seleccionadas;
- Agrupación (o agrupación): primero seleccione una determinada función de distancia del tipo de característica apropiado (o construya una nueva función de distancia) para medir la proximidad y luego realice una agrupación o agrupación;
- Evaluación de resultados de agrupamiento: se refiere a la evaluación de resultados de agrupamiento. Hay tres tipos principales de evaluación: evaluación de validez externa, evaluación de validez interna y evaluación de prueba de correlación.
Un buen algoritmo de agrupamiento debe tener buena escalabilidad, capacidad para manejar diferentes tipos de datos, capacidad para manejar datos ruidosos, insensibilidad al orden de los datos de muestra, buen rendimiento bajo restricciones, facilidad de interpretación y facilidad de uso.
La calidad de los resultados del análisis de conglomerados se puede juzgar a partir de indicadores internos e indicadores externos:
- Los indicadores externos se refieren al uso de un modelo de agrupación preespecificado como referencia para juzgar la calidad de los resultados de la agrupación.
- Los indicadores internos se refieren a utilizar únicamente las muestras que participan en el agrupamiento para juzgar la calidad de los resultados del agrupamiento sin recurrir a ninguna referencia externa.
Caso
Se agrupan cinco variedades y ocho atributos:
% 五个品种八个属性进行聚类
%Matlab程序如下:
X=[7.90 39.77 8.49 12.94 19.27 11.05 2.04 13.29
7.68 50.37 11.35 13.30 19.25 14.59 2.75 14.87
9.42 27.93 8.20 8.14 16.17 9.42 1055 9.76
9.16 27.98 9.01 9.32 15.99 9.10 1.82 11.35
10.06 28.64 10.52 10.05 16.18 8.39 1.96 10.81 ]';
Y=pdist(X);
SF=squareform(Y);
Z=linkage(Y,'average');
dendrogram(Z);
T=cluster(Z,'maxclust',3)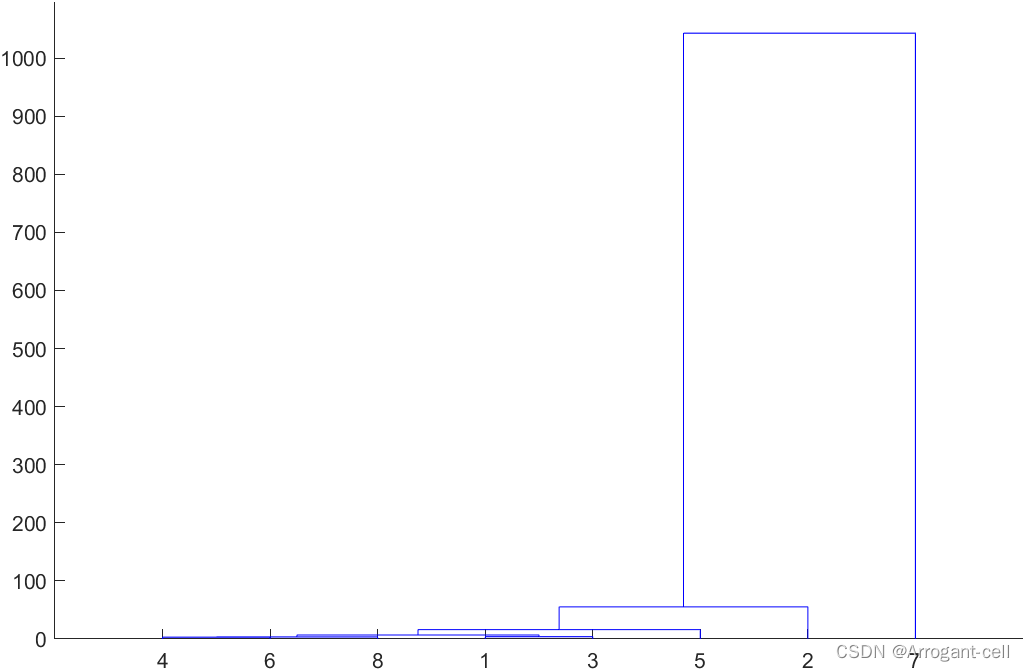
K-significa agrupación de código matlab
function [Idx, Center] = K_means(X, xstart)
% K-means聚类
% Idx是数据点属于哪个类的标记,Center是每个类的中心位置
% X是全部二维数据点,xstart是类的初始中心位置
len = length(X); %X中的数据点个数
Idx = zeros(len, 1); %每个数据点的Id,即属于哪个类
C1 = xstart(1,:); %第1类的中心位置
C2 = xstart(2,:); %第2类的中心位置
C3 = xstart(3,:); %第3类的中心位置
for i_for = 1:100
%为避免循环运行时间过长,通常设置一个循环次数
%或相邻两次聚类中心位置调整幅度小于某阈值则停止
%更新数据点属于哪个类
for i = 1:len
x_temp = X(i,:); %提取出单个数据点
d1 = norm(x_temp - C1); %与第1个类的距离
d2 = norm(x_temp - C2); %与第2个类的距离
d3 = norm(x_temp - C3); %与第3个类的距离
d = [d1;d2;d3];
[~, id] = min(d); %离哪个类最近则属于那个类
Idx(i) = id;
end
%更新类的中心位置
L1 = X(Idx == 1,:); %属于第1类的数据点
L2 = X(Idx == 2,:); %属于第2类的数据点
L3 = X(Idx == 3,:); %属于第3类的数据点
C1 = mean(L1); %更新第1类的中心位置
C2 = mean(L2); %更新第2类的中心位置
C3 = mean(L3); %更新第3类的中心位置
end
Center = [C1; C2; C3]; %类的中心位置
%演示数据
%% 1 random sample
%随机生成三组数据
a = rand(30,2) * 2;
b = rand(30,2) * 5;
c = rand(30,2) * 10;
figure(1);
subplot(2,2,1);
plot(a(:,1), a(:,2), 'r.'); hold on
plot(b(:,1), b(:,2), 'g*');
plot(c(:,1), c(:,2), 'bx'); hold off
grid on;
title('raw data');
%% 2 K-means cluster
X = [a; b; c]; %需要聚类的数据点
xstart = [2 2; 5 5; 8 8]; %初始聚类中心
subplot(2,2,2);
plot(X(:,1), X(:,2), 'kx'); hold on
plot(xstart(:,1), xstart(:,2), 'r*'); hold off
grid on;
title('raw data center');
[Idx, Center] = K_means(X, xstart);
subplot(2,2,4);
plot(X(Idx==1,1), X(Idx==1,2), 'kx'); hold on
plot(X(Idx==2,1), X(Idx==2,2), 'gx');
plot(X(Idx==3,1), X(Idx==3,2), 'bx');
plot(Center(:,1), Center(:,2), 'r*'); hold off
grid on;
title('K-means cluster result');
disp('xstart = ');
disp(xstart);
disp('Center = ');
disp(Center);referencias
https://blog.csdn.net/weixin_43584807/article/details/105539675
https://zhuanlan.zhihu.com/p/139924042
https://www.bilibili.com/video/BV1kC4y1a7Ee?p=19&vd_source=08ffbcb9832d41b9a520bccfe1600cc9