1. Introducción
Este artículo explica principalmente la implementación en Python del análisis de componentes principales (PCA) y realizará un seguimiento del análisis de ejemplo más adelante.
2 Principio - Implementación del Código
2.1 Pasos de implementación
El análisis de componentes principales PCA es un método de reducción de dimensionalidad ampliamente utilizado, y su realización se resume a continuación
2.2 Implementación del código
paquete de importación
import numpy as np
- Defina la función de matriz de covarianza de cálculo
X como datos de entrada, m es el número de datos de muestra, es decir, el número de filas de X.
Para estandarizar X, el método es: restar la media y dividir por la varianza. Si no comprende el principio de esta parte, puede hacerlo con Baidu.
Los datos estandarizados son una distribución normal estándar con una media de 0 y una varianza de 1.
# 计算协方差矩阵
def calc_cov(X):
m = X.shape[0] # 样本的数量,行数
# 数据标准化
X = (X - np.mean(X, axis=0)) / np.var(X, axis=0) # 标准化之后均值为0,方差为1
return 1 / m * np.matmul(X.T, X) # matmul为两个矩阵的乘积
- El proceso de definición de PCA
primero calcula la covarianza de los datos de entrada X, y luego calcula sus valores propios como: valores propios, calcula sus vectores propios como: vectores propios calcula
los valores propios y vectores propios usando la función np.linalg.eig (), usar Es muy conveniente
y luego el siguiente paso es calcular la matriz P y usar Y = XP para calcular los datos dimensionalmente reducidos Y
def pca(X, n_components):
# 计算协方差矩阵
cov_matrix = calc_cov(X)
# 计算协方差矩阵的特征值和对应特征向量
eigenvalues, eigenvectors = np.linalg.eig(cov_matrix) # eigenvalues特征值,eigenvectors特征向量
# 对特征值排序
idx = eigenvalues.argsort()[::-1]
# 取最大的前n_component组
eigenvectors = eigenvectors[:, idx]
eigenvectors = eigenvectors[:, :n_components]
# Y=XP转换
return np.matmul(X, eigenvectors)
2.3 Ejemplo de conjunto de datos de iris
Datos de importacion
from sklearn import datasets
import matplotlib.pyplot as plt
# 导入鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
Mirando la forma de los datos, el resultado es (150, 4)
X.shape
# (150, 4)
Calcular la matriz de covarianza
cov_matrix = calc_cov(X) # 计算特征值
cov_matrix
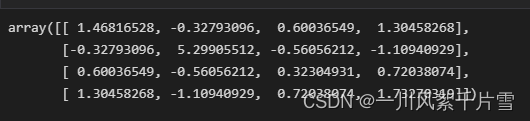
Puede ver que la matriz de covarianza es una matriz de 4 * 4, y luego calculamos los valores propios y vectores propios de la matriz.
eigenvalues, eigenvectors = np.linalg.eig(cov_matrix) # eigenvalues特征值,eigenvectors特征向量
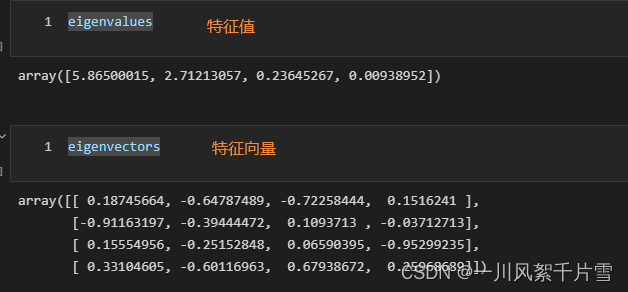
Luego calcula la P que necesitamos, aquí mantenemos 3 componentes principales.
idx = eigenvalues.argsort()[::-1]
# 取最大的前n_component组
eigenvectors = eigenvectors[:, idx]
eigenvectors = eigenvectors[:, :3]
Se obtiene una matriz con 4 filas y 3 columnas
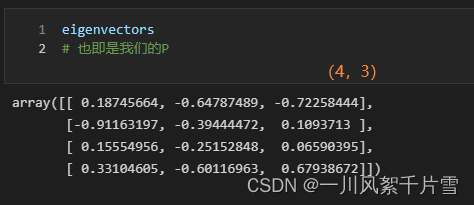
, y luego se utiliza P para obtener los datos reducidos dimensionalmente
# Y=PX转换
np.matmul(X, eigenvectors)
Los datos después de la reducción de dimensionalidad son (150, 4) * (4, 3) = (150, 3),
es decir, 150 datos en 3 columnas, y los datos se reducen de las 4 dimensiones originales a 3 dimensiones.
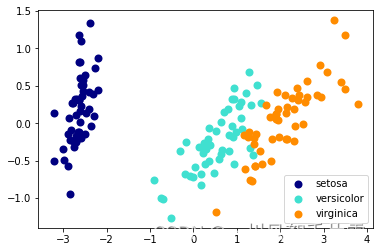
3 Implementación basada en Sklearn
# 导入sklearn降维模块
from sklearn import decomposition
# 创建pca模型实例,主成分个数为3个
pca = decomposition.PCA(n_components=3) # 写我们需要几个主成分
# 模型拟合
pca.fit(X)
# 拟合模型并将模型应用于数据X
X_trans = pca.transform(X)
# 颜色列表
colors = ['navy', 'turquoise', 'darkorange']
# 绘制不同类别
for c, i, target_name in zip(colors, [0,1,2], iris.target_names):
plt.scatter(X_trans[y == i, 0], X_trans[y == i, 1],
color=c, lw=2, label=target_name)
# 添加图例
plt.legend()
plt.show()