1.爬取京东信息
2.爬取网页的信息
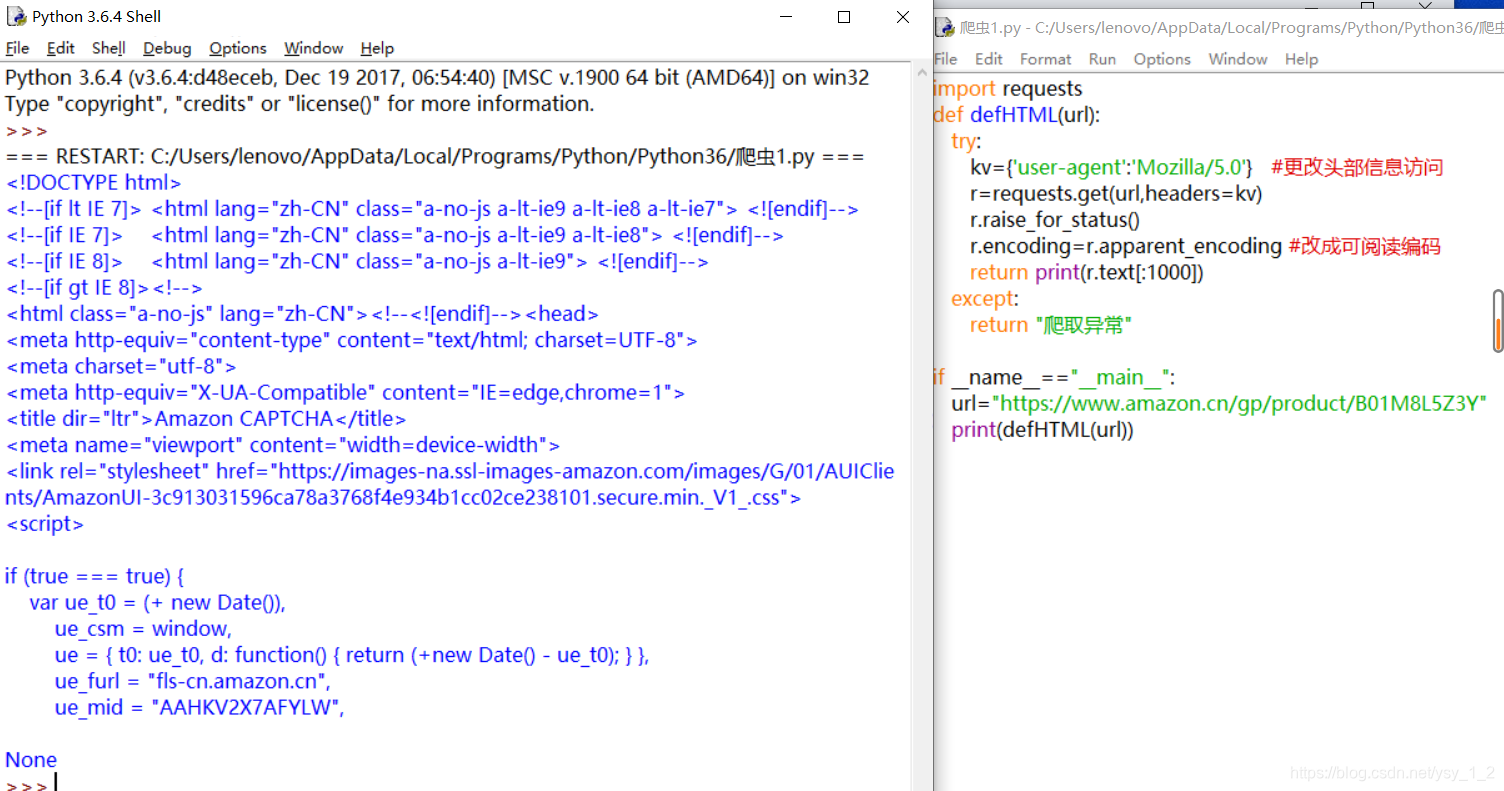
很多网站对爬取有限制,比较隐形,查看网络头,是不是爬虫请求的,是可以拒绝的.

查看头部信息,可以看到头部访问,是可以拒绝的

所以我们构建键值对的,在更改头部信息.在放在url中.
kv={‘user-agent’:‘Mozilla/5.0’}
3.百度/360搜索关键字提交
百度的关键字词接口:
http://www.baidu.com/s?wd=keyword
360关键词接口:
http://www.so.com/s?q=keyword
所以我们可以构造url就可以对关键词提取