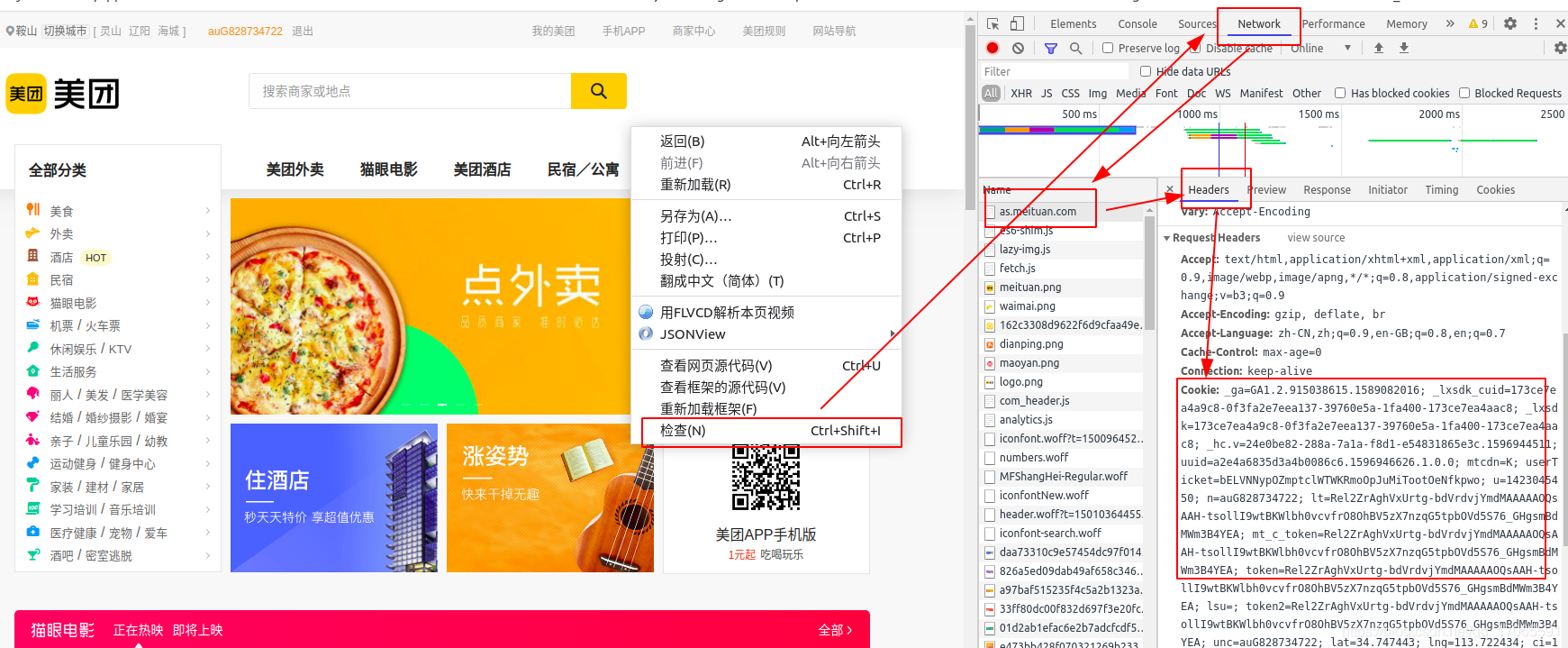
注意: 运行前先将send_request函数中的cookie替换掉, 过期cookie是不能用的
替换方法: 登录https://as.meituan.com/,右键 → \rightarrow →检查 → \rightarrow →Network → \rightarrow →xxx.meituan.com → \rightarrow →Headers → \rightarrow →Request Headers → \rightarrow →Cookie,把函数中的cookie替换掉
代码
# -*- coding: utf-8 -*-
import re
import csv
import time
import requests
def get_stores(url, referer=""):
response = send_request(url, referer=referer)
avgScore = re.findall(r'"avgScore":(.*?),', response.text)
shopname = re.findall(r'"frontImg".*?title":(.*?),', response.text)
allCommentNum = re.findall(r'"allCommentNum":(\d+),', response.text)
address = re.findall(r'"address":(.*?),', response.text)
avgPrice = re.findall(r'"avgPrice":(\d+),', response.text)
urlid = re.findall(r'"poiId":(\d+),', response.text)
end = True if not shopname else False # 没有商家列表表示终止
store_urls = []
for k in urlid:
a = 'https://www.meituan.com/meishi/' + str(k) + '/'
store_urls.append(a)
food_lists = []
for i in range(len(shopname)):
food_list = [shopname[i], avgScore[i], allCommentNum[i], address[i], avgPrice[i], store_urls[i]]
food_lists.append(food_list)
return food_lists, end
def get_score_detail(food_lists, referer):
for food_list in food_lists:
new_url = food_list[5]
response = send_request(new_url, referer=referer)
phone = re.findall(r'"phone":(.*?),', str(response.text))
food_list.append(phone)
return food_lists
def writer_to_file(food_lists, city_abbr):
csv_name = "{}.csv".format(city_abbr)
with open(csv_name, 'a', newline='', encoding='utf-8')as f:
write = csv.writer(f)
write.writerows(food_lists)
def get_cities():
cities_url = "https://www.meituan.com/changecity/"
response = send_request(cities_url, referer="")
'<a href="//tj.meituan.com" class="link city">天津</a>'
cities = re.findall(r'<a href=\"(.*?)\" class=\"link city\">', response.text)
return cities
def send_request(url, referer):
cookie = 'xxx'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
"Cookie": cookie}
if referer:
headers["Referer"] = referer
print(url)
r = requests.get(url, headers=headers)
print(r.status_code)
return r
def main():
cities = get_cities() # 所有城市的url
city_url_format = 'https:{}/meishi/'
for city in cities:
city_abbr = re.match(r"//(.+)\.meituan", city).group(1)
print(city, city_abbr)
main_url = city_url_format.format(city)
referer = main_url
i = 1 # 从第一页开始
end = False
while not end:
url = '{}pn{}/'.format(main_url, i)
food_lists, end = get_stores(url, referer=referer) # 获取每页的店铺列表, referer是上一页
food_lists = get_score_detail(food_lists, referer=url) # 对当前页的店铺列表分别请求,referer是列表页url
writer_to_file(food_lists, city_abbr) # 每页保存一次
i += 1 # 更新页码
referer = url # 更新referer
time.sleep(3)
if __name__ == '__main__':
main()
正则解析原理
相比xpath和bs4相对于文档树路径定位html元素的方式,re解析相当直接,在html字符串response.text中直接寻找正则模式,直捣黄龙,毫不拐弯抹角。
正则模式的寻找,个人认为相比xpath和bs4寻找路径其实时间和复杂度差不太多。哪个用的顺手用哪个。