本篇文章所包含的主要内容:
-
使用requests模块实现对网页以字符串的形式存储
-
使用open()、write()、close()函数实现文件的打开与写入
-
使用if() 条件语句对所需要的文字信息进行过滤以形成一个专用提取函数
★文章将直接以实战引入,
一步一步介绍如何从单个页面中爬取相应的文本信息,并对这些文本信息进行过滤后保存,只要你不是绝对地小白绝对可以 很容易看懂并掌握。
* 文章爬取网站:www.365essay.com
* 该网站主要收录了各类美文~
当然爬取这样一个页面的文本倒不如直接复制粘贴来的快,
但是因为这些文章的URL都是按照一定的规律存储的,后期可以通过循环操作一键抓取所有页面的指定文本并保存,
那个时候就会节去大量的时间。
而本篇文章的前半部分主要介绍如何对单个页面进行上述操作:
****************************************************************************************************************************************
★第一步:初步探索
手动打开网页,右键->检查元素(Google Chrome右键选择“检查”),然后可以看到主页的网页源码,
但这并不是我们这里要爬的网页;
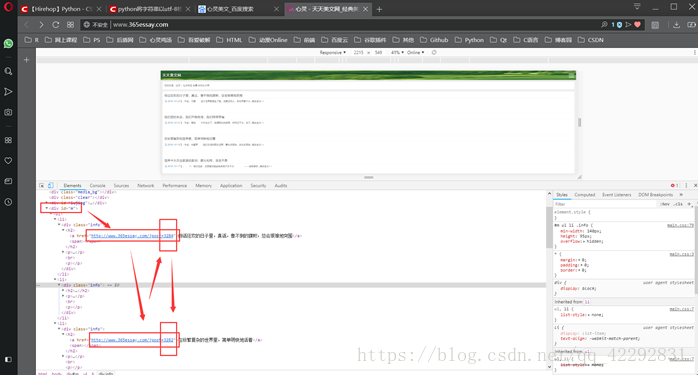
*啊~多么有规律的排版~~
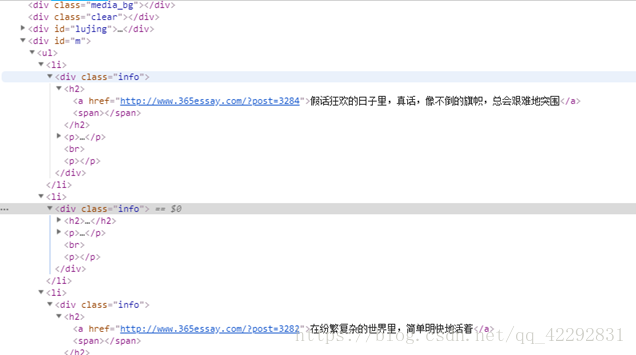
因为这里只是主页,接下来点击代码中的一个目录链接进入相应文章页面:
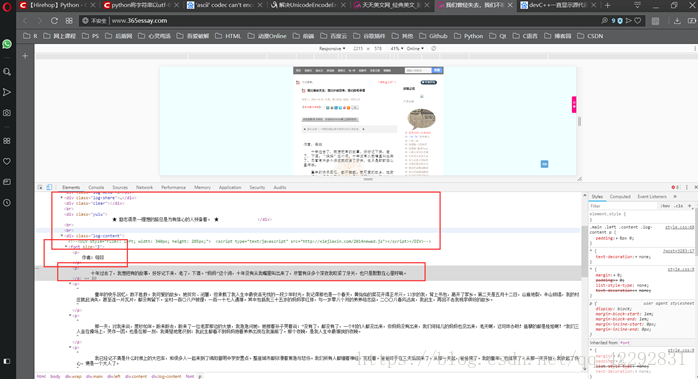
然后找到显示文本所对应的源码区域,分析这些源码的特点并尝试总结出正则表达式:
( 对于大小写的问题可以在后面查找的时候添加特定的参数进行处理 ".I" )
Regex = '<FONT size=3><p>(.*?)</FONT><br/>'
★第二步:实际代码
import re,requests
def write_essay(url):
r_text = requests.get(url).text
save_file = []
save_file = str(re.findall('<FONT size=3><p>(.*?)</FONT><br/>',r_text,re.S))
# print(save_file)
i = 0
j = 0 #仅仅作为显示额外输出文本的计数器变量
name = input("请输入需要保存的文件名(需要输入后缀):")
Save_file_name = "E:\\Essays\\"+name
while(1):
#print("111-Successful!\n")
f = open(Save_file_name, 'a+', encoding='utf-8')
if(save_file[i:i+8]=="['\\r\\n\\t"):
f.write("\n\n")
i = i+8
elif(save_file[i:i+33]=="\\r\\n</p>\\r\\n<p>\\r\\n\\t\\u3000\\u3000"):
i = i+33
f.write("\n")
elif(save_file[i]=="。"):
#print("222-Successful!\n")
f.write("。\n")
i = i+1
elif(save_file[i:i+10]=="\\r\\n</p>']"):
#print("Break!!!")
break
else:
# print("333-Successful!\n")
f.write(save_file[i])
f.close()
i = i+1
if(j%250==0):
print("正在进行数据清洗与写入文件,请等待……")
j = j+1
print("Write","Successful!")
print("示例URL: http://www.365essay.com/?post=3279")
url = input("请输入URL:")
write_essay(url)★ 这里代码没有实现对文章标题的抓取并存进文件的功能,但是可以在设置文件名的时候通过手动输入文章标题。
★ 虽然代码简陋,但是可以很直观的解却释和展现抓取与文本保存的基本原理;
★三:效果展示
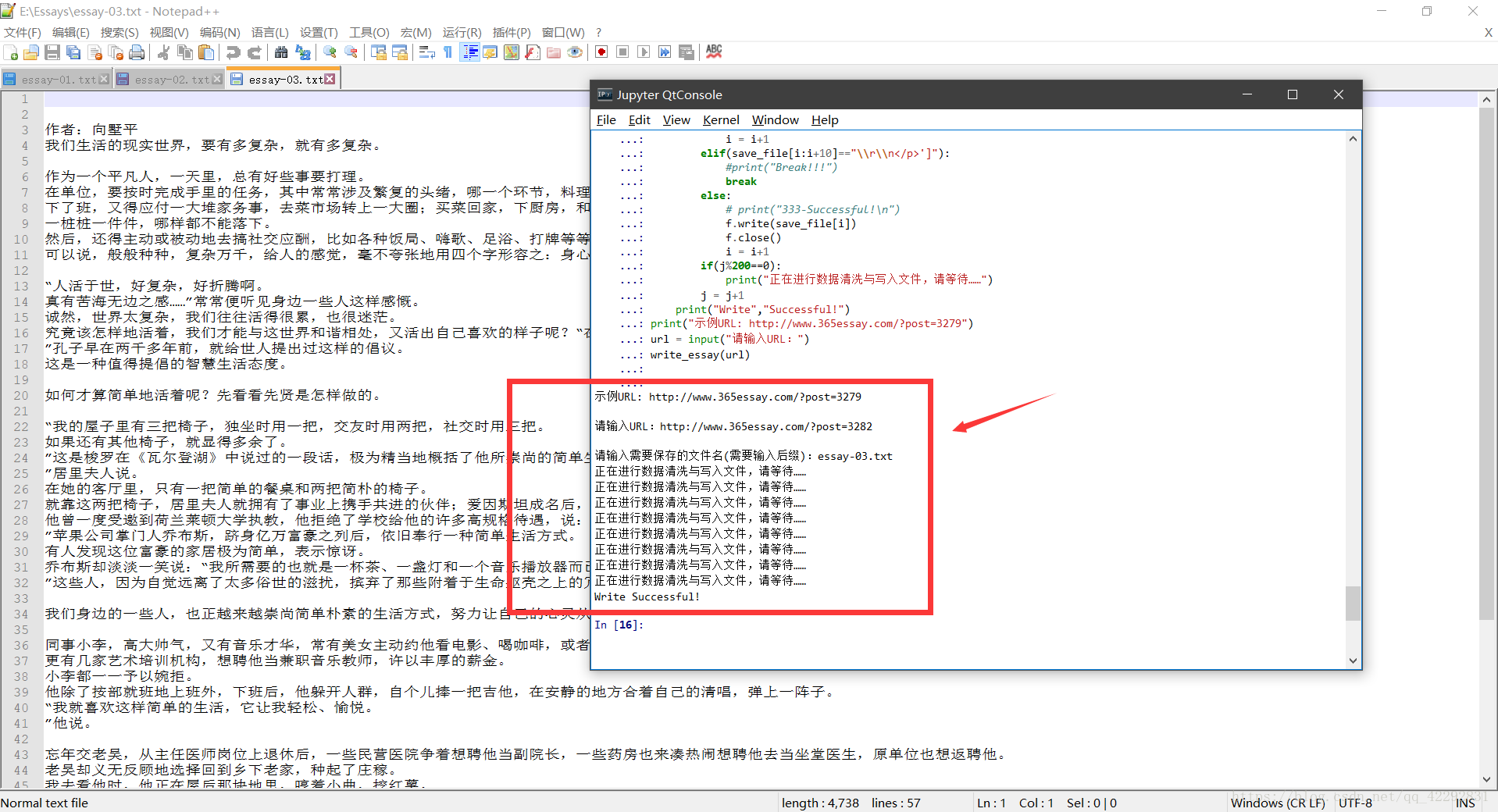
****************************************************************************************************************************************
****************************************************************************************************************************************
****************************************************************************************************************************************
2018.10.27追加:
( 本教程仅仅供学习使用,当您使用爬取到的文章以及转载的过程中请注明所使用的文章的作者及文章出处,尊重作者版权)
完善上面的代码,
并实现通过在函数中更改源地址来循环爬取各个网页文本的功能;
下面直接附上代码:
(注意:可能有的页面写进文本的过程中会掺杂部分没有被完全过滤掉的HTML标签;但是大部分文章均可以爬取)
def main():
import requests,re,random,os
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0",
"Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)",
"UCWEB7.0.2.37/28/999",
"NOKIA5700/ UCWEB7.0.2.37/28/999",
"Openwave/ UCWEB7.0.2.37/28/999",
"Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999",
# iPhone 6:
"Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25"]
def get_user_agent():
return random.choice(user_agent)
headers = {'User-Agent': random.choice(user_agent)}
essay_index = 120
while(essay_index<=120):
url = "http://www.365essay.com/?post="+str(essay_index)
html_text = requests.get(url,headers=headers).text
regex = "<h3 class=\"log-title\">(.*?)</h3>"
file_name = str(re.findall(regex,html_text,re.S))[16:-10]
file_name_len = len(file_name)
j = 0
while(j<file_name_len): #这里防止标题中有图片链接
if(file_name[j]=='<'):
file_name = file_name[0:j]
break
else:
j+=1
save_file = str(re.findall('<FONT size=3><p>(.*?)</FONT><br/>',html_text,re.S))[2:-2]
save_file = save_file+"stop_poisition"
save_path = "E:\\Essay"
if(not os.path.exists(save_path)):
os.mkdir(save_path)
print(">>> 开始下载:"+"《"+file_name+"》")
save_file_name = "E:\\Essay\\"+file_name+".txt"
f = open(save_file_name, 'a+', encoding='utf-8')
f.write("《"+file_name+"》\n\n")
i = 0
while(1):
f = open(save_file_name, 'a+', encoding='utf-8')
if(save_file[i:i+6]=="\\r\\n\\t"):
f.write("\n\n")
i = i+6
elif(save_file[i:i+23]=="</p>\\r\\n<p>\\u3000\\u3000"):
i = i+23
f.write("\n")
elif(save_file[i:i+15]=="\\r\\n</p>\\r\\n<p>"):
i = i+15
elif(save_file[i:i+12]=="\\u3000\\u3000"):
i = i+12
elif(save_file[i]=="。"):
f.write("。\n")
i = i+1
elif(save_file[i:i+4]=="\\r\\n"):
i = i+4
elif(save_file[i:i+18]=="</p>stop_poisition"):
f.write("\n\n-END-")
f.close()
break
else:
f.write(save_file[i])
f.close()
i = i+1
print(">>> 下载:《"+file_name+"》成功!\n")
essay_index+=1
main()代码中默认essay_index = 120,
当使用的时候可以自行修改该值并修改对应的循环条件。
* 附加:文章中随机请求头的使用参考了文章:https://blog.csdn.net/mouday/article/details/80182397
☆运行效果截图:

****************************************************************************************************************************************
最快的脚步不是跨越,而是继续,最慢的步伐不是小步,而是徘徊。
****************************************************************************************************************************************