一、前言
之前使用原生的 Python 库去爬取网页信息,经常要使用正则表达式,笔者记性不是很好,经常经常忘记相关符号及其作用。
后来使用著名的 Scrapy 框架去爬取信息,感觉太笨重了,特别是一个项目开发到一半,要引入爬虫功能,再使用 Scrapy,就不是那么友好了,其本身就是一个 Web Project。
近来使用一个和之前 Java 爬虫特别简单好使的 Jsoup 框架极其类似的 Beautiful Soup
引入也很简单:
# Python 2+
pip install beautifulsoup4
# Python 3+
pip3 install beautifulsoup4使用 Python 爬虫体验当然是比 Java 要好,java开发有点 “做作” —— 每一步都极其格式化(面向对象),Python 则运用自如。
二、需求
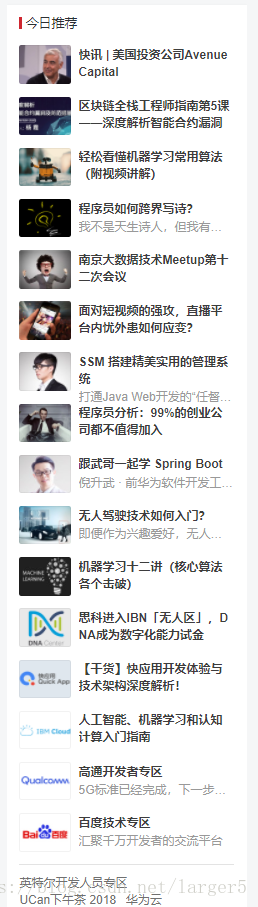
现在要爬取 CSDN首页 的今日推荐的 文章 标题 及其 链接,
2.1.这是网页目标内容
2.2.这是网页目标内容对应的源码

三、实践
你猜需要多少行代码,没错,就这几行,就是这么牛逼
3.1.代码
from bs4 import BeautifulSoup
from urllib.request import urlopen
html = urlopen("https://www.csdn.net/").read().decode('utf-8')
soup = BeautifulSoup(html,"html.parser")
titles=soup.select("h3[class='company_name'] a") # CSS 选择器
for title in titles:
print(title.get_text(),title.get('href'))# 标签体、标签属性