前言
之前是使用request库爬取网页,但是大型的网络爬虫使用框架爬取会事半功倍,今天实战爬取这个网页讲师的信息:https://www.itcast.cn/channel/teacher.shtml#ac
网页分析
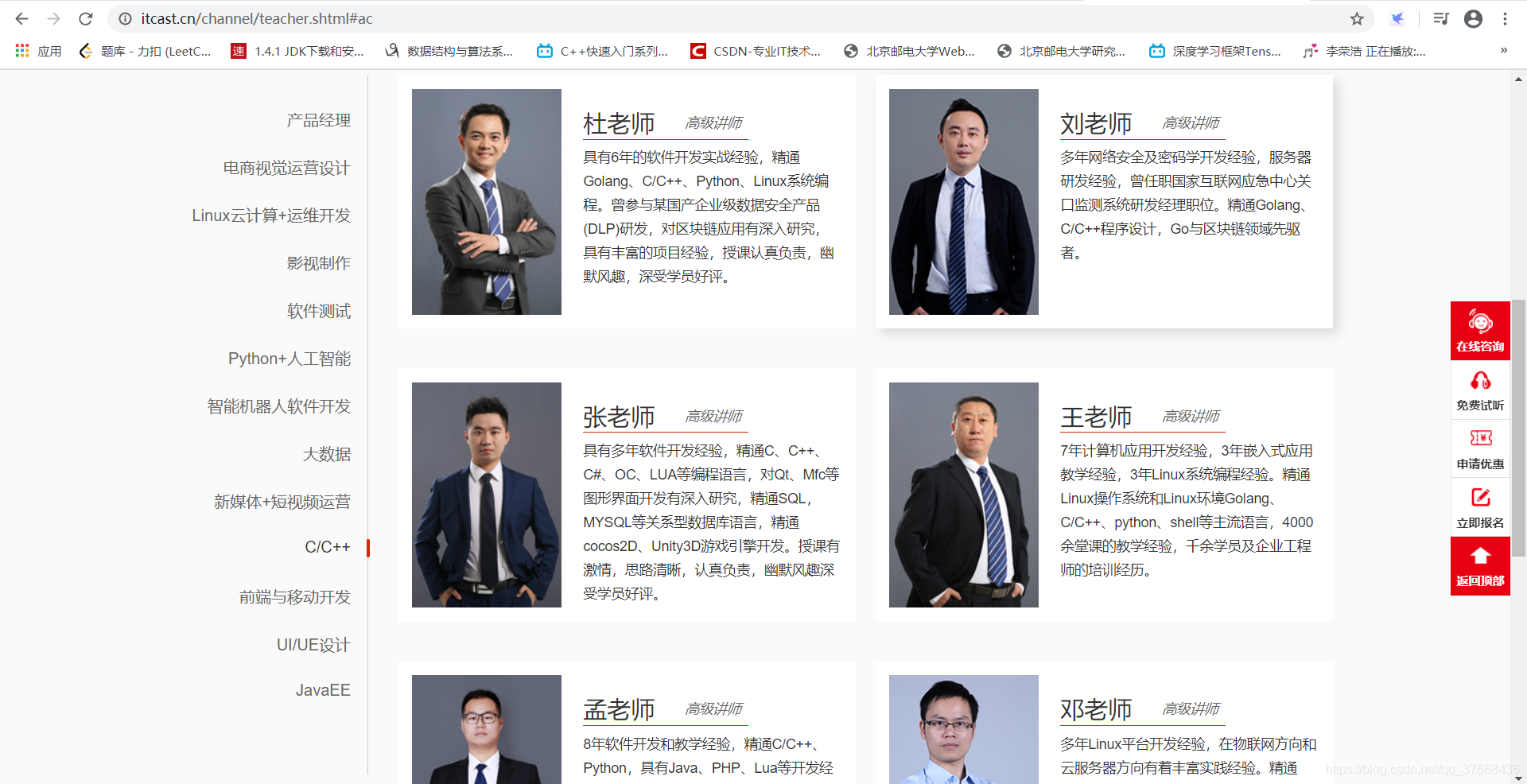
查看网页源码:

所有的老师信息都在这个div中,并且是以下格式存储:
<div class="li_txt">
<h3>姓名</h3>
<h4>职称</h4>
<p>介绍</p>
</div>
那么这个特征提取就很简单了
scrapy爬虫配置
新建工程:
scrapy startproject mySpider
文件夹样式如下:
修改items.py文件加入我们自己的消息类型:
# teacher
class ItcastItem(scrapy.Item):
name = scrapy.Field()
level = scrapy.Field()
info = scrapy.Field()
在spiders文件夹下新建爬虫文件itcast_spider.py:
使用命令行:
scrapy genspider itcast_spider "itcast.com"
#-*- coding:utf-8 -*-
import scrapy
from mySpider.items import ItcastItem # 加入自己定义的消息类型
class ItcastSpider(scrapy.spiders.Spider):
name = "itcast" # 爬虫名字
# allowd_domains = ["http://www.itcast.cn"]
start_urls = ['https://www.itcast.cn/channel/teacher.shtml#ac'] # 起始url
def parse(self,response): # 网页解析函数
#file_name = "teacher.html"
#with open(file_name,"wb") as f:
#f.write(response.body) # 保存网页在本地
items = [] # 全部老师的集合
for site in response.xpath("//div[@class=\"li_txt\"]"): # 匹配div并且class属性的值是li_txt
item = ItcastItem()
teacher_name = site.xpath('h3/text()').extract() # 获取老师名字
teacher_level = site.xpath('h4/text()').extract() # 获取老师职称
teacher_info = site.xpath('p/text()').extract() # 获取老师简介
item['name'] = teacher_name[0]
item['level'] = teacher_level[0]
item['info'] = teacher_info[0]
items.append(item)
return items
注意这里:
item['name'] = teacher_name[0]
item['level'] = teacher_level[0]
item['info'] = teacher_info[0]
这里在给类成员赋值的时候不能item.name = teacher_name[0]这样赋值,因为这样的话name就是字符串类型而不是scrapy.Field()类型了
运行爬虫:
scrapy crawl itcast
保存数据为json格式:
scrapy crawl itcast -o teachers.json -t json
本地多了json文件:
