1.BERT模型的介绍
BERT模型(Bidirectional Encoder Representations from Transformers)——基于Transformer的双向编码表示法:
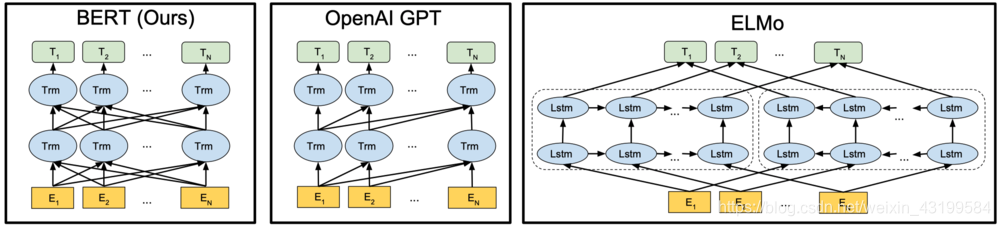
BERT模型的根基就是Transformer,来自Google团队17年的文章Attention is all you need。双向的意思表示它在处理一个词的时候,能考虑到该词前面和后面单词的信息,从而获取上下文的语义。(对于Transformer的参考资料:attention is all you need模型笔记,Transformer模型详解)
| Model | 获取长距离语义信息程度 | 能否抓取左右上下文语义 | 能否完成并行计算 |
|---|---|---|---|
| Word2Vec | 1 | Yes | Yes |
| 单向LSTM | 2 | No | No |
| ELMo | 2 | Yes | No |
| GPT | 3 | No | Yes |
| BERT | 3 | Yes | Yes |
- ELMo采用的是双向的LSTM的架构,因此能够抓取到左右上下文的语义。
- 由于GPT和BERT都采用Transformer,所有它们都是能够完成并行计算,但是由于GPT采用的是单向的,导致了每个token只能关注左侧的语境,在文献中被称为了“Transformer解码器”,而BERT采用了双向的双向的自注意机制,所以被称为了“Transformer编码器”。
2、BERT模型核心点
2.1 BERT的架构
BERT的模型架构基于了Transformer,实现了多层双向的Transformer编码器。文中有两个模型,一个是1.1亿参数的base模型,一个是3.4亿参数的large模型。里面所设置的参数如下:
| Model | Transformer层数(L) | Hidden units(H) | self-attention heads(A) | 总参数 |
|---|---|---|---|---|
| BERT(base) | 12 | 768 | 12 | 1.1亿 |
| BERT(large) | 24 | 1024 | 16 | 3.4亿 |
其中base模型的参数和OpenAI的GPT的参数一致。目的就是为了同GPT的效果进行一个比较。
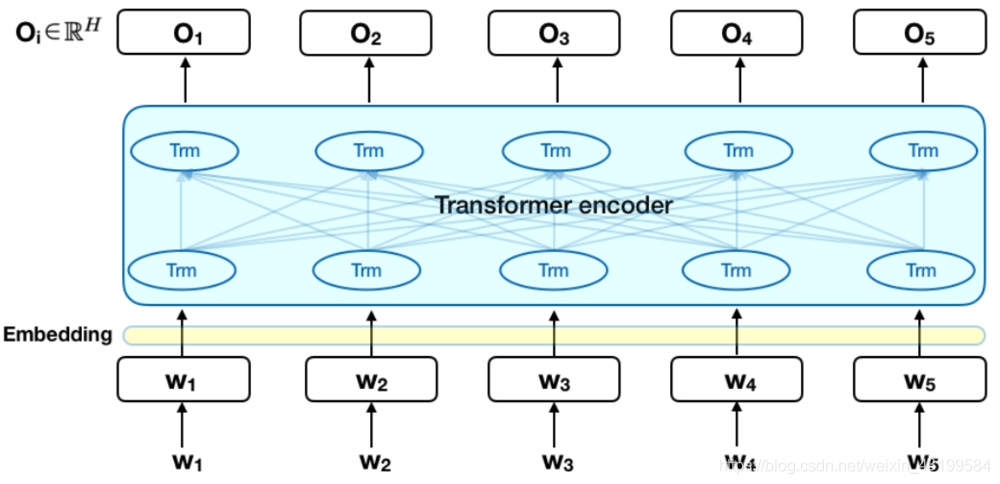
2.2 BERT的输入表征
下图表示了BERT的输入表征
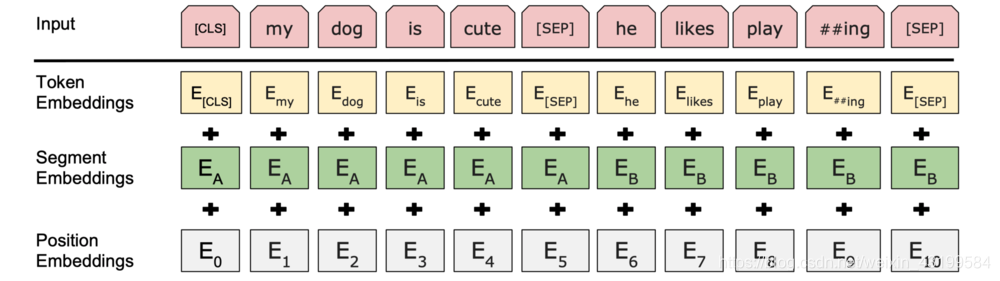
各部分的作用:
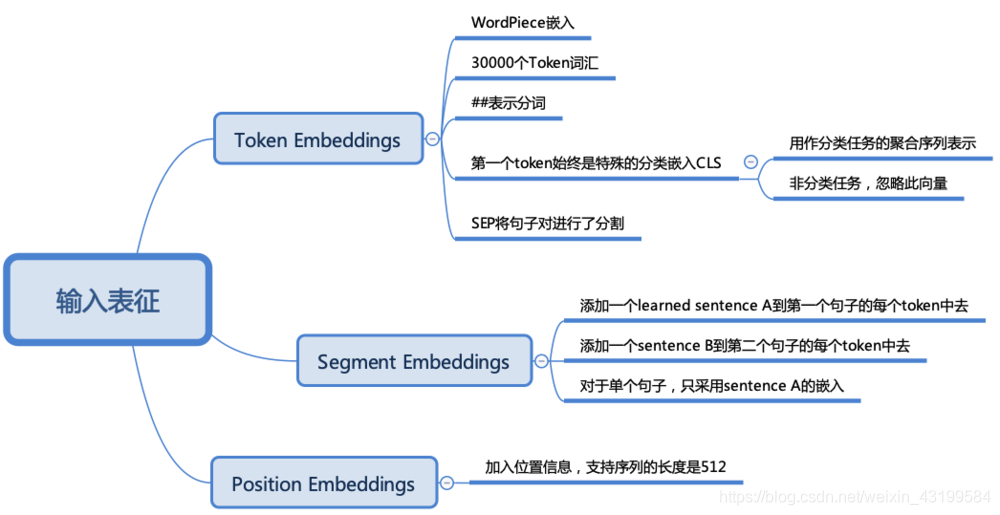
2.3 BERT中最核心的部分
(1)Masked Language Model(MLM)
为了实现深度的双向表示,使得双向的作用让每个单词能够在多层上下文中间接的看到自己。文中就采用了一种简单的策略,也就是MLM。
MLM:随机屏蔽掉部分输入token,然后再去预测这些被屏蔽掉的token。
这里实现的时候有两个缺点
缺点1:预训练与微调之间的不匹配,因为微调期间是没有看到[Mask]token。
- Solution:不是总用实际的[Mask]token替换被“masked”的词汇,而是采用训练数据生成器随机去选择15%的token。
例子:句子= my dog is hairy, 选择的token是hairy。执行的流程为:

Transformer不知道它将被要求预测哪些单词或哪些单词已被随机单词替换,因此它被迫保持每个输入词块的分布式语境表征。此外,因为随机替换只发生在所有词块的1.5%(即15%的10%),这似乎不会损害模型的语言理解能力。
缺点2:每个batch只预测了15%的token,这说明了模型可能需要更多的预训练步骤才能收敛。
(2)Next Sentence Prediction
现在从句子的角度来考虑问题,预训练了一个二值化下一句预测任务,该任务可以从任何单语语料库中轻松生成。具体来说,选择句子A和B作为预训练样本:A的下一句有50%的可能是B,另外50%的可能是来自语料库的。
例子:
- 输入=[CLS]男子去[MASK]商店[SEP]他买了一加仑[MASK]牛奶[SEP]
Label= IsNext - 输入=[CLS]男人[面具]到商店[SEP]企鹅[面具]是飞行##少鸟[SEP]
Label= NotNext
2.4 预训练过程
训练批量大小为256个序列(256个序列*512个词块=128,000个词块/批次),持续1,000,000个步骤,这比33亿个单词语料库大约40个周期
| Item | 值或名称 |
|---|---|
| 学习率 | |
| Adam β1 | 0.9 |
| Adam β2 | 0.999 |
| L2权重衰减 | 0.01 |
| dropout | 0.1 |
| 激活函数 | gelu |
| Model | TPU个数 | TPU芯片个数 | 每次预训练天数 |
|---|---|---|---|
| BERT(Base) | 4 | 16 | 4 |
| BERT(Large) | 16 | 64 | 4 |
2.5 微调过程
微调过程中,大多数模型超参数与预训练相同。批量大小、学习率和训练周期数量会有区别。最佳超参数值是特定于任务的,但我们发现以下范围的可能值可以在所有任务中很好地工作:
| 参数 | 值 |
|---|---|
| Batch | 16,32 |
| 学习率Adam | 5e-5,3e-5,2e-5 |
| 周期 | 3,4 |
3. 实验部分
BERT应用到了11项NLP的任务上面
(1)GLUE数据集:
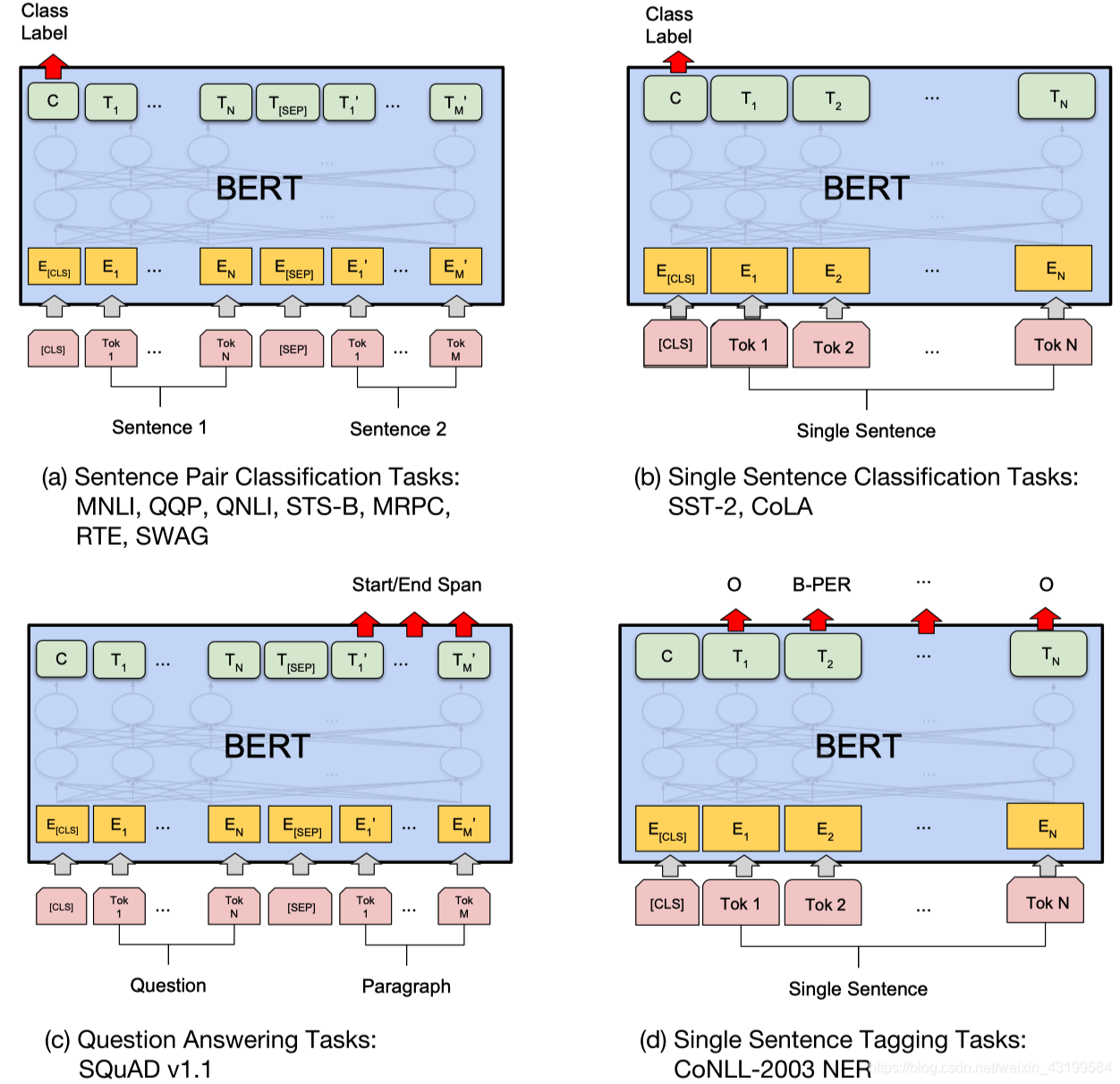
上图中,(a)和(b)是序列级任务,©和(d)是词块级任务。图中E代表其输入嵌入,Ti代表词块i的语境表征,[CLS]是分类输出的特殊符号,[SEP]是分割非连续词块序列的特殊符号。
结果:
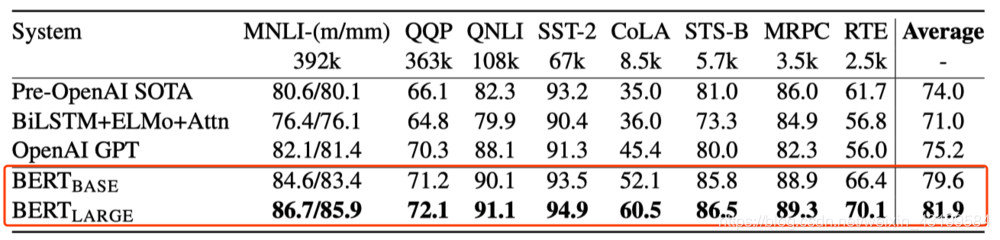
由GLUE评估服务器给出。每个任务下方的数字表示训练样例的数量。“平均”一栏中的数据与GLUE官方评分稍有不同,因为我们排除了有问题的WNLI集。BERT 和OpenAI GPT的结果是单模型、单任务下的数据。
(2) SQuAD 结果:
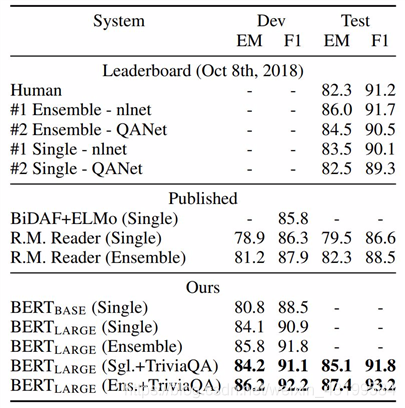
BERT 集成是使用不同预训练检查点和微调种子(fine-tuning seed)的 7x 系统。
(3) CoNLL-2003 命名实体识别结果:
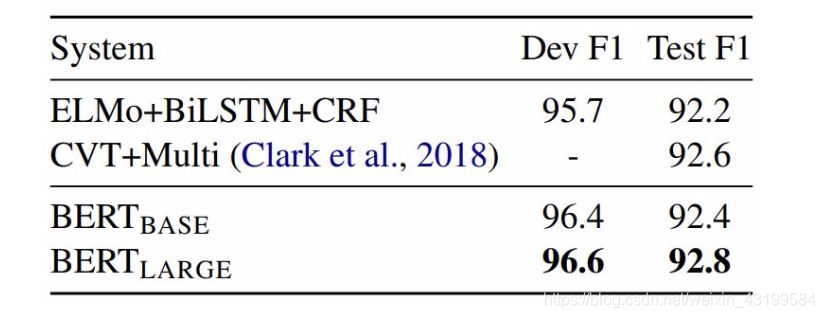
超参数由开发集选择,得出的开发和测试分数是使用这些超参数进行五次随机重启的平均值。
4. 总结
NLP的发展依赖于语言模型的改进和创新,从Word2vec——>ELMo,OpenAI , GPT——>BERT。今年CMU和google brain联手推出了bert的改进版xlnet,主要在以下三个方面进行了优化
- 采用AR模型替代AE模型,解决mask带来的负面影响
- 双流注意力机制
- 引入transformer-xl
- 在接下来的学习中会继续整理和更新Xlnet模型这一部分的学习笔记。
