一、介绍
在这篇博文中,我将讨论像BERT,BART和T5这样的大型语言模型。到2020年,LLM领域取得的主要进展包括这些模型的开发。BERT和T5由Google开发,BART由Meta开发。我将根据这些模型的发布日期依次介绍这些模型的详细信息。在之前的博客文章自然语言处理的自回归模型中,我讨论了生成式预训练转换器的自回归性质。在这篇博客中,我将比较这些模型与自回归模型的不同之处。因此,如果您还没有查看上一篇文章,请去查看。BERT 论文于 2018 年发布,BART 于 2019 年发布,T5 于 2020 年发布。我将以相同的顺序介绍论文的细节。
二、变压器的双向编码器表示 (BERT)
BERT模型基于多层双向变压器编码器。BERT旨在通过在所有层中联合调节左上下文和右上下文来预训练来自未标记文本的深度双向表示。因此,只需一个额外的输出层即可对预先训练的BERT模型进行微调,以创建最先进的模型。BERT使用掩蔽语言模型预训练目标来克服单向性约束。BERT的预训练也是通过下一句预测来完成的。

bert输入表示
与transformer相比,BERT的输入表示是令牌嵌入,段嵌入和位置嵌入的总和。还添加了特殊的分类标记和句子分隔符标记。令牌嵌入是词汇量为 30,000 的词片嵌入。预训练期间使用的数据集是BookCorpus和Wikipedia。
2.1 MLM语言模型
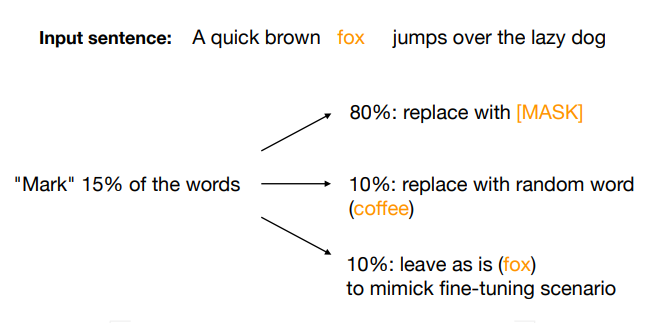
在MLM预训练中,输入序列的15%的单词被获取。其中 80% 被屏蔽,10% 被替换为随机单词,10% 保持不变。因此,每次模型查看掩码时,它都会输出词汇标记的分布。
2.2 传输工作:下一句预测
在第二个预训练任务中,模型在一个序列中提供两个句子,模型必须根据上下文输出第二个句子是Next还是NotNext。已确保数据集与相同数量的isNext和NotNext类进行平衡。这有助于理解句子之间的关系。

2.2 NSP 工作:下游任务训练
在大型未标记数据集上完成预训练后,将针对标记数据为下游任务训练模型。遵循两种方法:
- 微调方法: 在这种方法中,我们在模型的末尾添加一个分类层,该分类层输出单词的softmax概率。模型在下游任务的标记数据集上进行端到端训练。模型的所有参数都将更新。
- 基于功能的方法: 在这种方法中,BERT模型的权重在预训练后被冻结。为标记数据集创建BERT嵌入,然后在这些嵌入上训练新模型。在原始论文中,应用于来自BERT模型连接的最后2层的嵌入的4层BILSTM表现最佳。
三、双向和自回归变压器 (BART)
BART是Facebook开发的模型。它是谷歌的BERT和OpenAI的GPT的组合。BERT的双向和自动编码器特性有助于需要有关整个输入序列信息的下游任务。但它不适用于序列生成任务。GPT 模型擅长文本生成,但不擅长需要了解整个序列的下游任务。这是由于其单向和自回归的性质。BART结合了两种模型的方法,因此是两全其美的。

3.1 巴特架构
BART 模型由双向编码器和自回归解码器组成。对于编码器,噪声变换已应用于序列。序列被掩码符号损坏。然后,此损坏的序列作为输入发送到双向编码器。在此之后,使用自回归解码器计算原始文档的可能性。不强制要求以相同的方式对齐输入和输出。但是在微调的情况下,将未损坏的文档输入到编码器和解码器,并使用解码器最终隐藏状态的表示。

3.2 噪声变换
在 BART 模型的预训练期间,对序列应用了多个噪声变换。对模型进行了优化,以从损坏的序列中重建原始序列。

捷径结果
四、文本到文本传输变压器 (T5)
T5模型的架构与Vaswani等人提出的原始变压器几乎相同。编码器和解码器都由 12 个模块组成。该模型有 220.5 亿个参数。仅对架构进行了一些更改,例如它们消除了层范数偏差并将层规范化置于残差路径之外。T<> 中使用了不同的位置嵌入方案。为了训练模型,使用了模型和数据并行性的组合。使用相同的无监督预训练和监督微调技术。

4.1 文本转文本框架
T5 以文本到文本格式的形式对每个问题进行建模。输入和输出将始终采用文本格式。他们还以文本格式对回归问题进行了建模。T5 在 750 GB C4 数据集上训练。此数据集是在清理 20 TB 通用爬网数据集后检索的。删除了带有 JavaScript 代码、大括号、HTML 标签、占位符文本和冒犯性语言的句子。

4.2 屏蔽方法
在无监督的预训练期间,设计了一个目标,该目标随机采样,然后丢弃输入序列中 15% 的标记。丢弃令牌的所有连续跨度都将替换为单个哨兵令牌。在BERT的情况下,训练模型以预测相应掩码的一个单词。但T5是混合的。它被训练为输出一个掩码的一个单词或多个单词。这使得模型在学习语言结构时可以灵活。
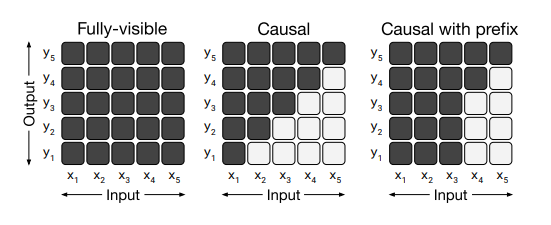
4.3 注意面具图案
在上图中,显示了模型中使用的各种注意力掩模模式。光细胞表示不允许自我注意机制关注相应的细胞。在左侧,整个输入在每个输出步骤中可见。在中间部分(因果关系),输出步骤无法查看来自未来的任何输入。在右侧部分(带前缀的因果关系),自我注意机制在输入序列的一部分上使用完全可见的掩码。
五、结语
总之,BERT、BART和T5等语言模型具有不同的架构和训练方式。与单向预训练相比,MLM技术在自然语言处理领域引发了革命性的变化,并展示了大规模语言模型的力量。这些模型在生成连贯且上下文相关的文本方面展示了非凡的能力,推动了语言生成任务的界限。在下一篇博文中,我将详细介绍从 GPT-3.5 到 ChatGPT 和 RLHF 概念的过渡。
参考和引用