关于bert模型的细节记录
1. Input
1.1. pretrain
- 输入包含七个部分,分别为
input_ids,input_mask,segment_ids,masked_lm_positions,mask_lm_ids,masked_lm_weights,next_sentence_labels.- input_ids:表示tokens的ids
- input_mask:表示哪些是input,哪些是padding.len(input_ids)个1,后面继续补0.对于mask的词,主要占了全部vocabulary的15%左右,在代码中对于每个词80%replace with [mask],10% keep original,10% replace with random word.超过了mask的词数,则终止.
- segment_ids:第一个句子到[SEP]为0,后面为1.主要是对输入进行区分,判断输入的两个句子.
- masked_lm_positions:表示句子中mask的token的position.
- mask_lm_ids:表示句子中mask的token的id.
- masked_lm_weights:表示句子中mask的token的权重.
- next_sentence_labels:表示两个句子是不是相连的.
- 对于每个句子,sentence->embedding->postprocess
- embedding: 将输入[batch_size, seq_len]->[batch_size, seq_len, embedding_size]
- postprocess:
- 1.输入input_embedding,
- 2.加上token_type_ids,使用one_hot
token_type_table = tf.get_variable( name=token_type_embedding_name, shape=[token_type_vocab_size, width], initializer=create_initializer(initializer_range)) # This vocab will be small so we always do one-hot here, since it is always # faster for a small vocabulary. flat_token_type_ids = tf.reshape(token_type_ids, [-1]) one_hot_ids = tf.one_hot(flat_token_type_ids, depth=token_type_vocab_size) token_type_embeddings = tf.matmul(one_hot_ids, token_type_table) token_type_embeddings = tf.reshape(token_type_embeddings, [batch_size, seq_length, width]) output += token_type_embeddings- 3.加上use_postion_embedding,max_position_embedding >> sequence_len ,使用slice截取
full_position_embeddings = tf.get_variable( name=position_embedding_name, shape=[max_position_embeddings, width], initializer=create_initializer(initializer_range)) # Since the position embedding table is a learned variable, we create it # using a (long) sequence length `max_position_embeddings`. The actual # sequence length might be shorter than this, for faster training of # tasks that do not have long sequences. # # So `full_position_embeddings` is effectively an embedding table # for position [0, 1, 2, ..., max_position_embeddings-1], and the current # sequence has positions [0, 1, 2, ... seq_length-1], so we can just # perform a slice. position_embeddings = tf.slice(full_position_embeddings, [0, 0], [seq_length, -1]) num_dims = len(output.shape.as_list()) # Only the last two dimensions are relevant (`seq_length` and `width`), so # we broadcast among the first dimensions, which is typically just # the batch size. position_broadcast_shape = [] for _ in range(num_dims - 2): position_broadcast_shape.append(1) position_broadcast_shape.extend([seq_length, width]) position_embeddings = tf.reshape(position_embeddings, position_broadcast_shape) output += position_embeddings- 4.layer_normalization
- 5.dropout
1.2 run_classifier
- 针对不同的任务可以有不同的输入格式,针对不同的输入格式,可以修改不同的DataProcessor来进行处理.
- 例如,针对pair的分类任务,可以有label [sep] sen1 [sep] sen2.这样的话可以集成DataProcessor来进行处理.
2. Model
- 将postprocess的input输入到transformer, 每层的处理过程,求出
attention_head->concat->dense,dropout,layer_norm->dense->dense,dropout,layer_norm- attention_head:
attention_head = attention_layer( from_tensor=layer_input, to_tensor=layer_input, attention_mask=attention_mask, num_attention_heads=num_attention_heads, size_per_head=attention_head_size, attention_probs_dropout_prob=attention_probs_dropout_prob, initializer_range=initializer_range, do_return_2d_tensor=True, batch_size=batch_size, from_seq_length=seq_length, to_seq_length=seq_length) attention_heads.append(attention_head)- concat:
if len(attention_heads) == 1: attention_output = attention_heads[0] else: # In the case where we have other sequences, we just concatenate # them to the self-attention head before the projection. attention_output = tf.concat(attention_heads, axis=-1)- dense,dropout,layer_norm:
attention_output = tf.layers.dense( attention_output, hidden_size, kernel_initializer=create_initializer(initializer_range)) attention_output = dropout(attention_output, hidden_dropout_prob) attention_output = layer_norm(attention_output + layer_input)- dense:
intermediate_output = tf.layers.dense( attention_output, intermediate_size, activation=intermediate_act_fn, kernel_initializer=create_initializer(initializer_range))- dense,dropout,layer_norm
layer_output = tf.layers.dense( intermediate_output, hidden_size, kernel_initializer=create_initializer(initializer_range)) layer_output = dropout(layer_output, hidden_dropout_prob) layer_output = layer_norm(layer_output + attention_output) prev_output = layer_output all_layer_outputs.append(layer_output) - attention_layer解析
- 标准的self-multi-head的算法流程.
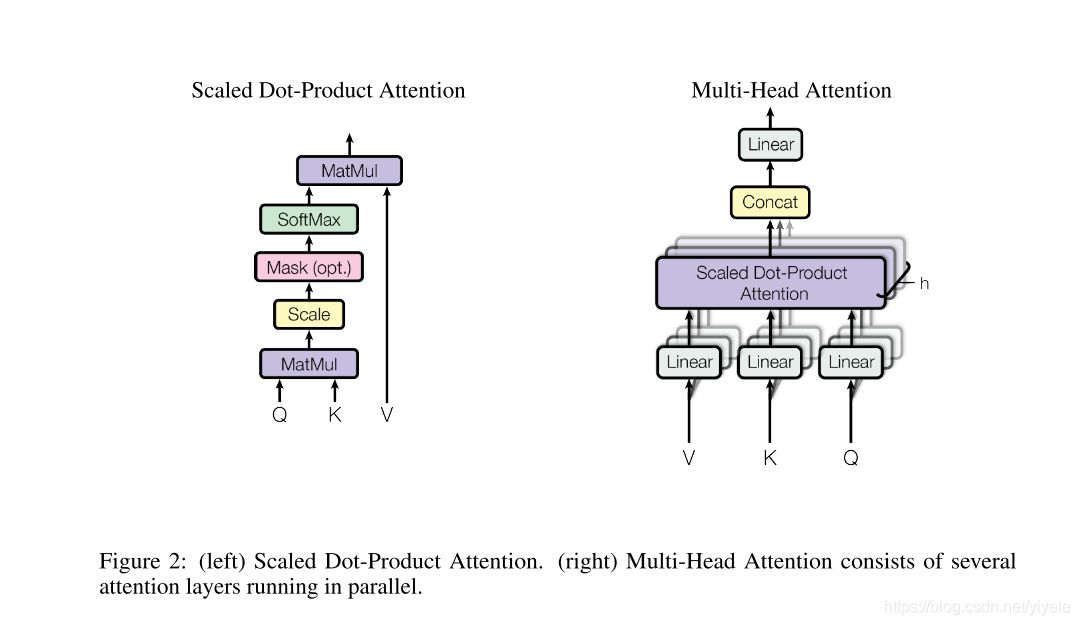
- 代码解析
def attention_layer(from_tensor, to_tensor, attention_mask=None, num_attention_heads=1, size_per_head=512, query_act=None, key_act=None, value_act=None, attention_probs_dropout_prob=0.0, initializer_range=0.02, do_return_2d_tensor=False, batch_size=None, from_seq_length=None, to_seq_length=None): # 函数的主要作用是调换两个维度. def transpose_for_scores(input_tensor, batch_size, num_attention_heads, seq_length, width): output_tensor = tf.reshape( input_tensor, [batch_size, seq_length, num_attention_heads, width]) output_tensor = tf.transpose(output_tensor, [0, 2, 1, 3]) return output_tensor # bert这里的from_tensor和to_tensor是同一个 from_shape = get_shape_list(from_tensor, expected_rank=[2, 3]) to_shape = get_shape_list(to_tensor, expected_rank=[2, 3]) if len(from_shape) != len(to_shape): raise ValueError( "The rank of `from_tensor` must match the rank of `to_tensor`.") if len(from_shape) == 3: batch_size = from_shape[0] from_seq_length = from_shape[1] to_seq_length = to_shape[1] elif len(from_shape) == 2: if (batch_size is None or from_seq_length is None or to_seq_length is None): raise ValueError( "When passing in rank 2 tensors to attention_layer, the values " "for `batch_size`, `from_seq_length`, and `to_seq_length` " "must all be specified.") # Scalar dimensions referenced here: # B = batch size (number of sequences) # F = `from_tensor` sequence length # T = `to_tensor` sequence length # N = `num_attention_heads` # H = `size_per_head` from_tensor_2d = reshape_to_matrix(from_tensor) to_tensor_2d = reshape_to_matrix(to_tensor) # 将from_tensor_2d(query)维度变为[B*F, N*H] # `query_layer` = [B*F, N*H] query_layer = tf.layers.dense( from_tensor_2d, num_attention_heads * size_per_head, activation=query_act, name="query", kernel_initializer=create_initializer(initializer_range)) # 将to_tensor_2d(key)维度变为[B*F, N*H] # `key_layer` = [B*T, N*H] key_layer = tf.layers.dense( to_tensor_2d, num_attention_heads * size_per_head, activation=key_act, name="key", kernel_initializer=create_initializer(initializer_range)) # 将to_tensor_2d(value)维度变为[B*F, N*H] # `value_layer` = [B*T, N*H] value_layer = tf.layers.dense( to_tensor_2d, num_attention_heads * size_per_head, activation=value_act, name="value", kernel_initializer=create_initializer(initializer_range)) # 调换query_layer的维度 # `query_layer` = [B, N, F, H] query_layer = transpose_for_scores(query_layer, batch_size, num_attention_heads, from_seq_length, size_per_head) # 调换key_layer的维度 # `key_layer` = [B, N, T, H] key_layer = transpose_for_scores(key_layer, batch_size, num_attention_heads, to_seq_length, size_per_head) # Take the dot product between "query" and "key" to get the raw # attention scores. # `attention_scores` = [B, N, F, T] # Q与K相乘 attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True) # scale,注意scale的大小是根据size_per_head来决定的. attention_scores = tf.multiply(attention_scores, 1.0 / math.sqrt(float(size_per_head))) # 注意这里的mask方式,主要是因为下一个步骤是softmax if attention_mask is not None: # `attention_mask` = [B, 1, F, T] attention_mask = tf.expand_dims(attention_mask, axis=[1]) # Since attention_mask is 1.0 for positions we want to attend and 0.0 for # masked positions, this operation will create a tensor which is 0.0 for # positions we want to attend and -10000.0 for masked positions. adder = (1.0 - tf.cast(attention_mask, tf.float32)) * -10000.0 # Since we are adding it to the raw scores before the softmax, this is # effectively the same as removing these entirely. attention_scores += adder # Normalize the attention scores to probabilities. # `attention_probs` = [B, N, F, T] attention_probs = tf.nn.softmax(attention_scores) # This is actually dropping out entire tokens to attend to, which might # seem a bit unusual, but is taken from the original Transformer paper. attention_probs = dropout(attention_probs, attention_probs_dropout_prob) # `value_layer` = [B, T, N, H] value_layer = tf.reshape( value_layer, [batch_size, to_seq_length, num_attention_heads, size_per_head]) # `value_layer` = [B, N, T, H] value_layer = tf.transpose(value_layer, [0, 2, 1, 3]) # `context_layer` = [B, N, F, H] context_layer = tf.matmul(attention_probs, value_layer) # `context_layer` = [B, F, N, H] context_layer = tf.transpose(context_layer, [0, 2, 1, 3]) if do_return_2d_tensor: # `context_layer` = [B*F, N*V] context_layer = tf.reshape( context_layer, [batch_size * from_seq_length, num_attention_heads * size_per_head]) else: # `context_layer` = [B, F, N*V] context_layer = tf.reshape( context_layer, [batch_size, from_seq_length, num_attention_heads * size_per_head]) return context_layer - 标准的self-multi-head的算法流程.
3. Loss
- masked_lm_loss:(采用对数损失函数)
input_tensor = gather_indexes(input_tensor, positions)
with tf.variable_scope("cls/predictions"):
# We apply one more non-linear transformation before the output layer.
# This matrix is not used after pre-training.
with tf.variable_scope("transform"):
input_tensor = tf.layers.dense(
input_tensor,
units=bert_config.hidden_size,
activation=modeling.get_activation(bert_config.hidden_act),
kernel_initializer=modeling.create_initializer(
bert_config.initializer_range))
input_tensor = modeling.layer_norm(input_tensor)
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
output_bias = tf.get_variable(
"output_bias",
shape=[bert_config.vocab_size],
initializer=tf.zeros_initializer())
logits = tf.matmul(input_tensor, output_weights, transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias)
log_probs = tf.nn.log_softmax(logits, axis=-1)
label_ids = tf.reshape(label_ids, [-1])
label_weights = tf.reshape(label_weights, [-1])
one_hot_labels = tf.one_hot(
label_ids, depth=bert_config.vocab_size, dtype=tf.float32)
# The `positions` tensor might be zero-padded (if the sequence is too
# short to have the maximum number of predictions). The `label_weights`
# tensor has a value of 1.0 for every real prediction and 0.0 for the
# padding predictions.
per_example_loss = -tf.reduce_sum(log_probs * one_hot_labels, axis=[-1])
numerator = tf.reduce_sum(label_weights * per_example_loss)
denominator = tf.reduce_sum(label_weights) + 1e-5
loss = numerator / denominator
- next_sentence_loss:(采用对数损失函数)
output_weights = tf.get_variable(
"output_weights",
shape=[2, bert_config.hidden_size],
initializer=modeling.create_initializer(bert_config.initializer_range))
output_bias = tf.get_variable(
"output_bias", shape=[2], initializer=tf.zeros_initializer())
logits = tf.matmul(input_tensor, output_weights, transpose_b=True)
logits = tf.nn.bias_add(logits, output_bias)
log_probs = tf.nn.log_softmax(logits, axis=-1)
labels = tf.reshape(labels, [-1])
one_hot_labels = tf.one_hot(labels, depth=2, dtype=tf.float32)
per_example_loss = -tf.reduce_sum(one_hot_labels * log_probs, axis=-1)
loss = tf.reduce_mean(per_example_loss)
最后,总的loss是将上面的两个任务的loss相加.
4. 总结
- bert模型输入是一个个字,中文不需要分词.
- bert模型是多任务的模型,包括预测mask词以及判断是sen2是不是sen1的下一句.
5. bert模型改进
一. 是强调通用性好以及规模大。加入越来越多高质量的各种类型的无监督数据。它的最明显好处是通用性好,训练好后什么场合都适用。
二. 是通过多任务训练,加入各种新型的NLP任务数据,它的好处是有监督,能够有针对性的把任务相关的知识编码到网络参数里,所以明显的好处是学习目标明确,学习效率高;而对应的缺点是NLP的具体有监督任务,往往训练数据量少,于是包含的知识点少;而且有点偏科,学到的知识通用性不强。
三. 字级别 input + 词级别 mask.如百度ERNIE以及Google 在 SQUAD 2.0 上的 BERT N-Gram Mask.
