命名实体识别
首先下载相应bert 模块
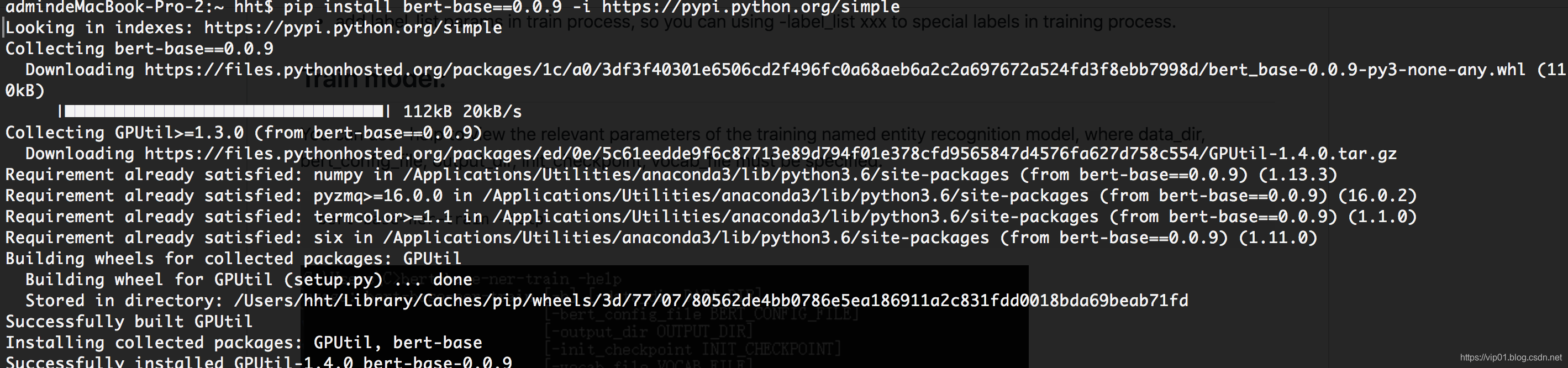
pip install bert-base==0.0.9 -i https://pypi.python.org/simple
也可参考官网处理
安装
软件包现在支持的功能
1.命名实体识别的训练
2.命名实体识别的服务C/S
3.继承优秀开源软件:bert_as_service(hanxiao)的BERT所有服务
4.文本分类服务
后续功能会继续增加
基于命名行训练命名实体识别模型:
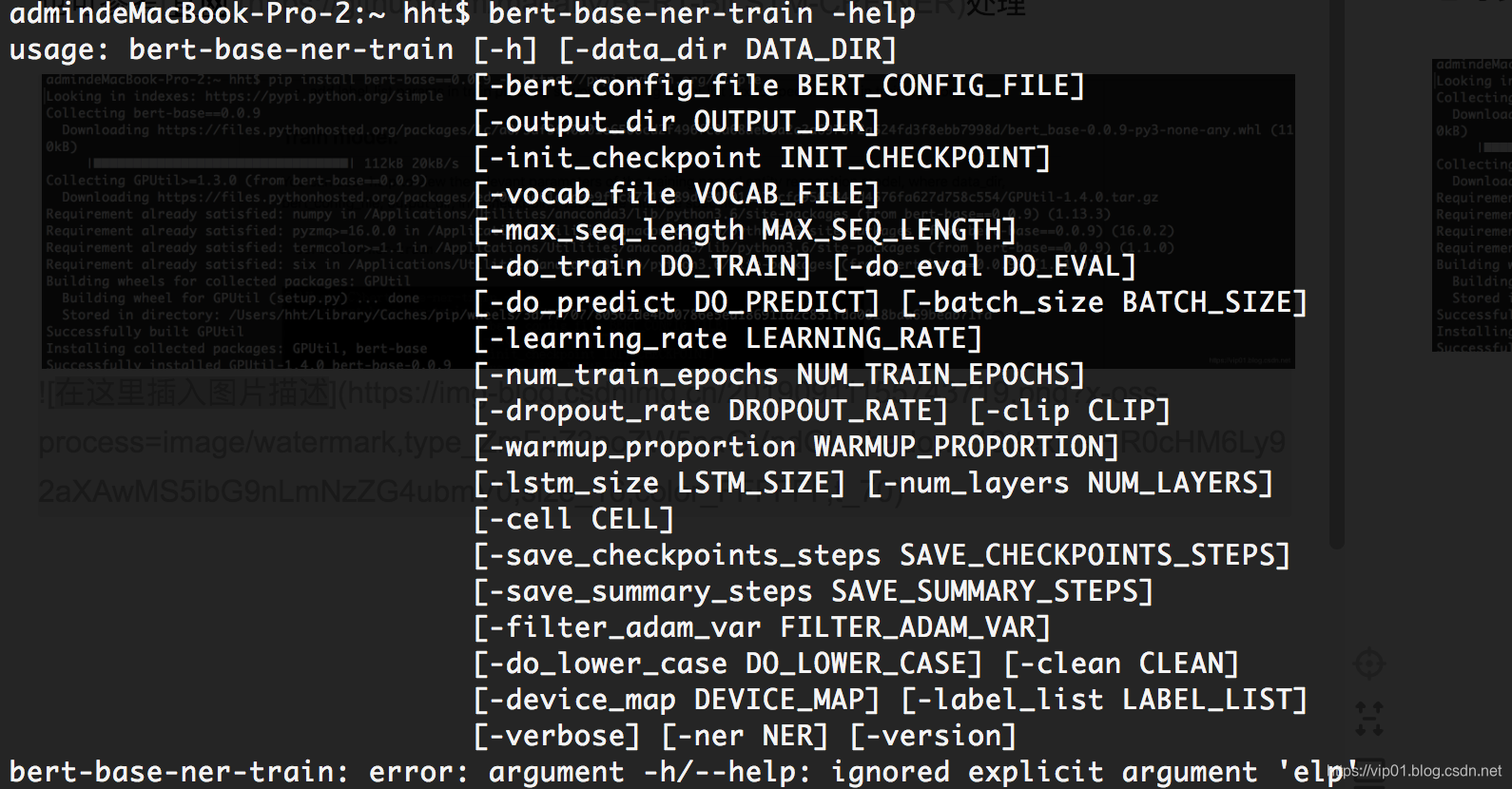
安装完bert-base后,会生成两个基于命名行的工具,其中bert-base-ner-train支持命名实体识别模型的训练,你只需要指定训练数据的目录,BERT相关参数的目录即可。可以使用下面的命令查看帮助
训练的事例命名如下:
bert-base-ner-train \
-data_dir {your dataset dir}\
-output_dir {training output dir}\
-init_checkpoint {Google BERT model dir}\
-bert_config_file {bert_config.json under the Google BERT model dir} \
-vocab_file {vocab.txt under the Google BERT model dir}
参数说明
其中data_dir是你的数据所在的目录,训练数据,验证数据和测试数据命名格式为:train.txt, dev.txt,test.txt,请按照这个格式命名文件,否则会报错。
训练数据的格式如下:
海 O
钓 O
比 O
赛 O
地 O
点 O
在 O
厦 B-LOC
门 I-LOC
与 O
金 B-LOC
门 I-LOC
之 O
间 O
的 O
海 O
域 O
。 O
每行得第一个是字,第二个是它的标签,使用空格’ '分隔,请一定要使用空格。句与句之间使用空行划分。程序会自动读取你的数据。
output_dir: 训练模型输出的文件路径,模型的checkpoint以及一些标签映射表都会存储在这里,这个路径在作为服务的时候,可以指定为-ner_model_dir
init_checkpoint: 下载的谷歌BERT模型
bert_config_file : 谷歌BERT模型下面的bert_config.json
vocab_file: 谷歌BERT模型下面的vocab.txt
训练完成后,你可以在你指定的output_dir中查看训练结果。
更多操作:
https://blog.csdn.net/macanv/article/details/85684284
还有一个bert模型的封装
https://www.jianshu.com/p/1d6689851622
https://cloud.tencent.com/developer/article/1470051
https://www.h3399.cn/201908/714454.html
