引言
BERT是一种预训练模型,有很多预训练模型,例如skip-gram,cbow可以用在embedding的时候的预训练模型,但参数比较少,我们得在加上很多其他层来训练。ALBERT也是一种预训练模型。
在深度学习中,我们知道把网络变深可以增加模型的效果,但将BERT模型的网络变深,hiddne size变大之后将会很大训练,因为参数的量级达到了十几G。
所以就引出了ALBERT的核心研究问题:能不能更有效的利用参数?
参数来源
BERT-base中的Attention feed-forward block模块参数包括了12个transformer blocks,12个attention heads,且hidden size=768 。算上embedding 中的参数,共计近110million的参数。其中Attention feed-forward中的参数占了80%左右。
减少参数的方法
方法1: factorized embedding parametrization
BERT中Token编码过程中使用了V x E个参数(E与H相同),其中V表示词表大小,E表示embedding后的大小:
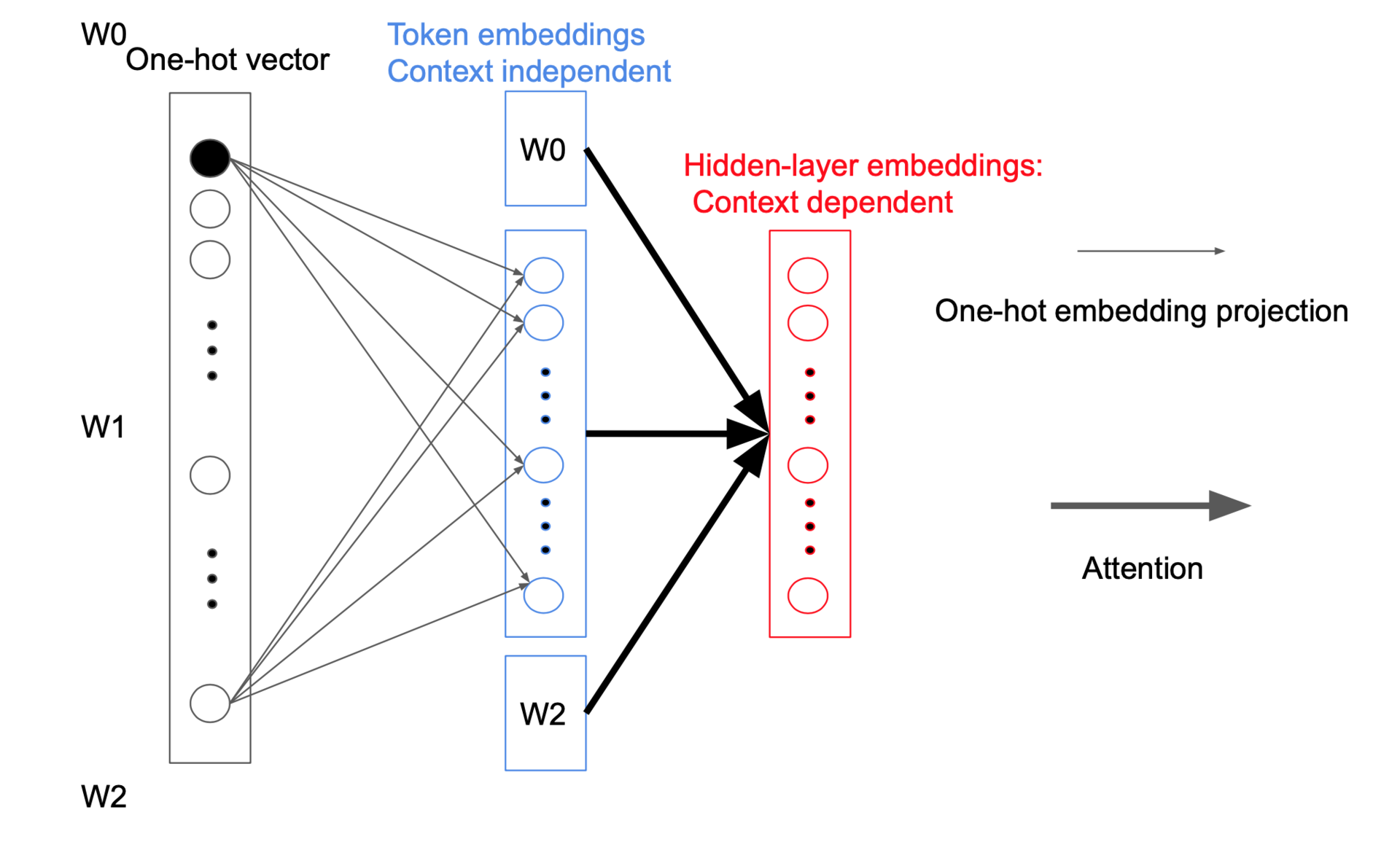
在表示词的时候使用one-hot方式,在更新参数的时候只会更新每个词所在向量中很少的一部分。可以先对one-hot向量进行压缩,然后再还原成所需的维度,认为在此过程对对信息的损失不大。但参数的规模从V x E变成了V x E + E x H,其中E<<H
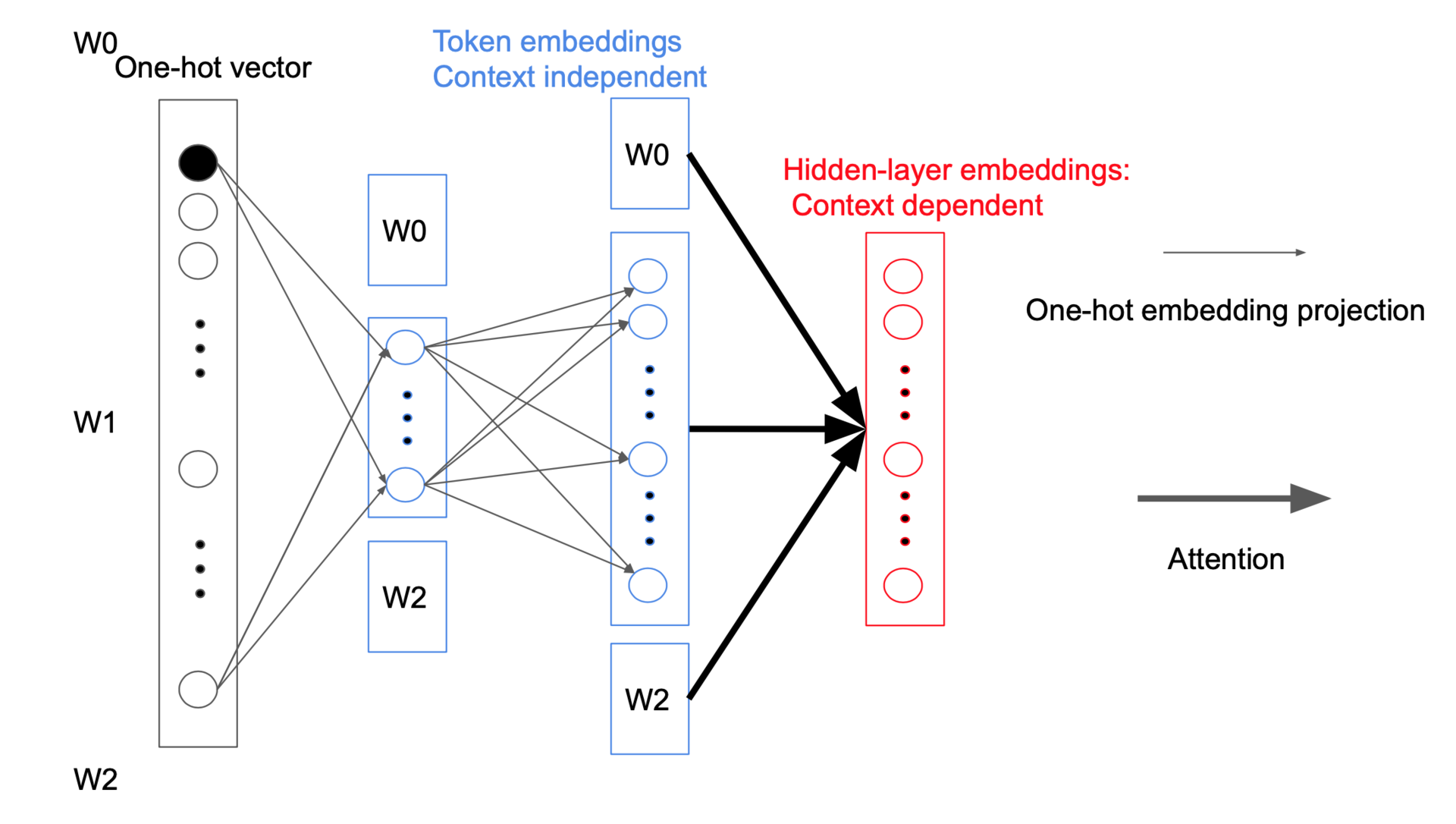
下面是一个例子(BERT basezho中hidden size=embeding size=768):
原始:30,000x768=23,040,000
修改后:30,000x128+128x768=3,938,304
方法1:实验结果
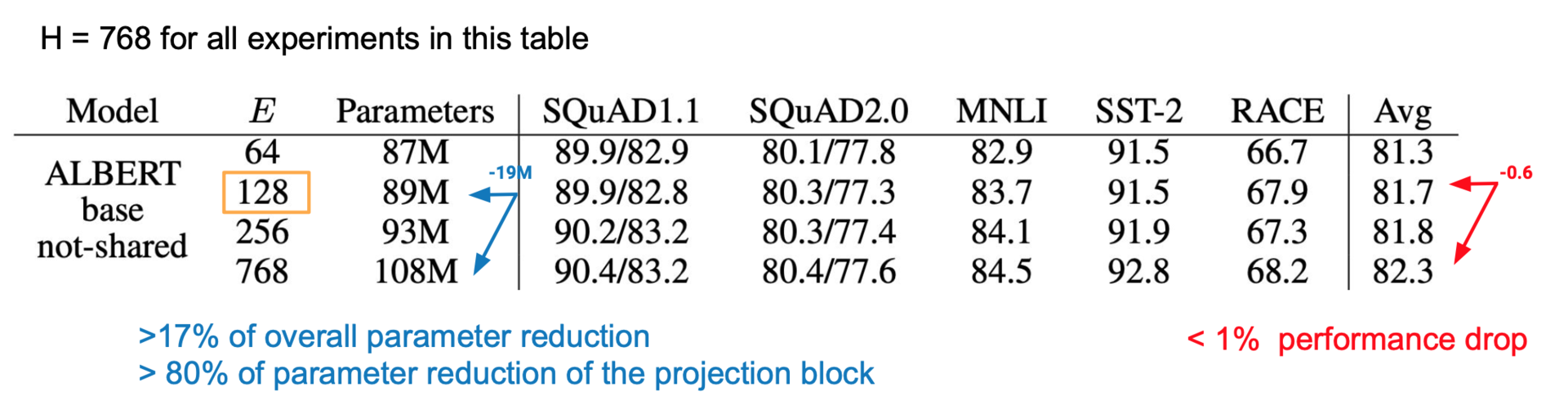
在实验中将embeding size设置为128后会减少17%的参数大小,但准确率的减少不超过1%。
方法2:Cross-layer parameter sharing
受到Gong, Linyuan, et al. “Efficient Training of BERT by Progressively Stacking.” ICML. 2019.论文的启发,观察了不同层之间的Attention可视化情况:
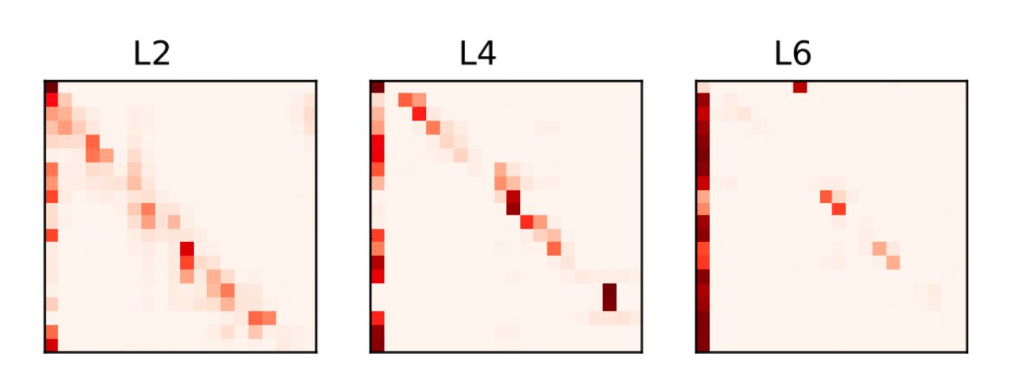
attention-feedforward 的操作是重复进行的,我们能不能共享他们的参数呢?而且attention的可视化结果在不同层之间都呈现一个三角形的图案,如果共享他们的参数,那么参数量级就会O (12 x L x H x H) 变为 O (12 x H x H)。
方法2:实验结果
进行实验后结果如下:
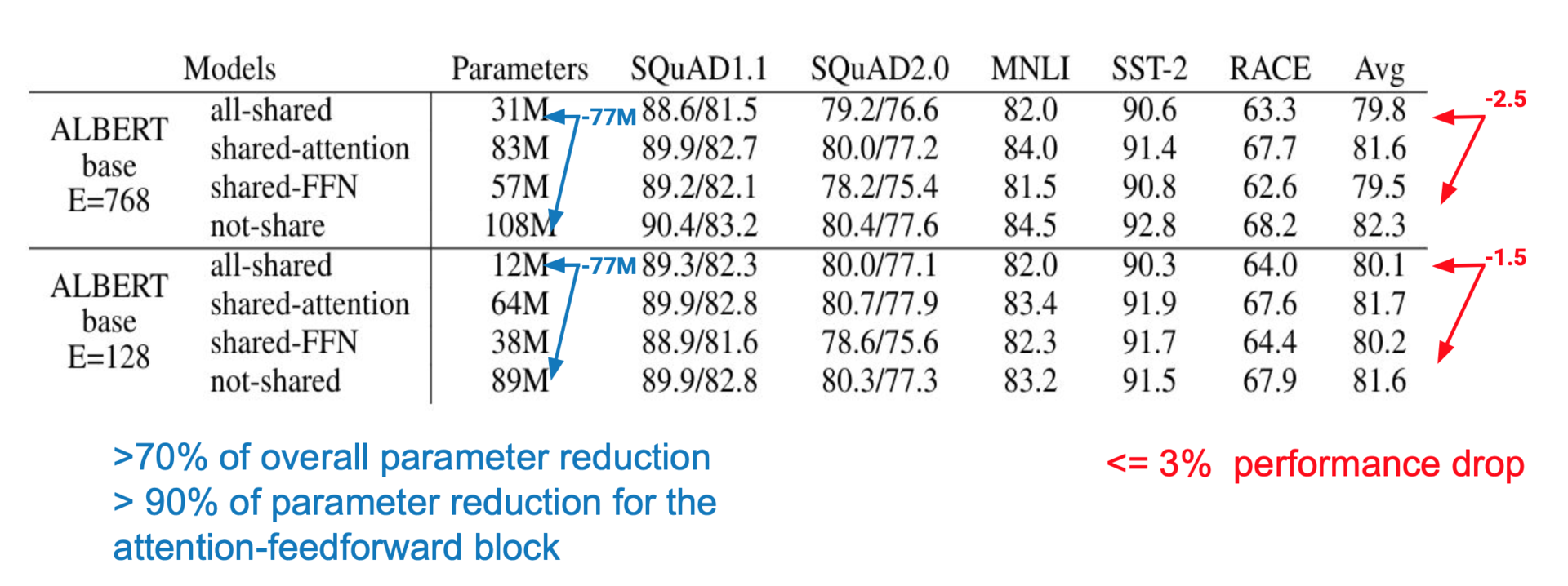
如果共享所有参数,发现在不同层之间共享参数后会减少总参数的70%,只有不到3%的精度损失。
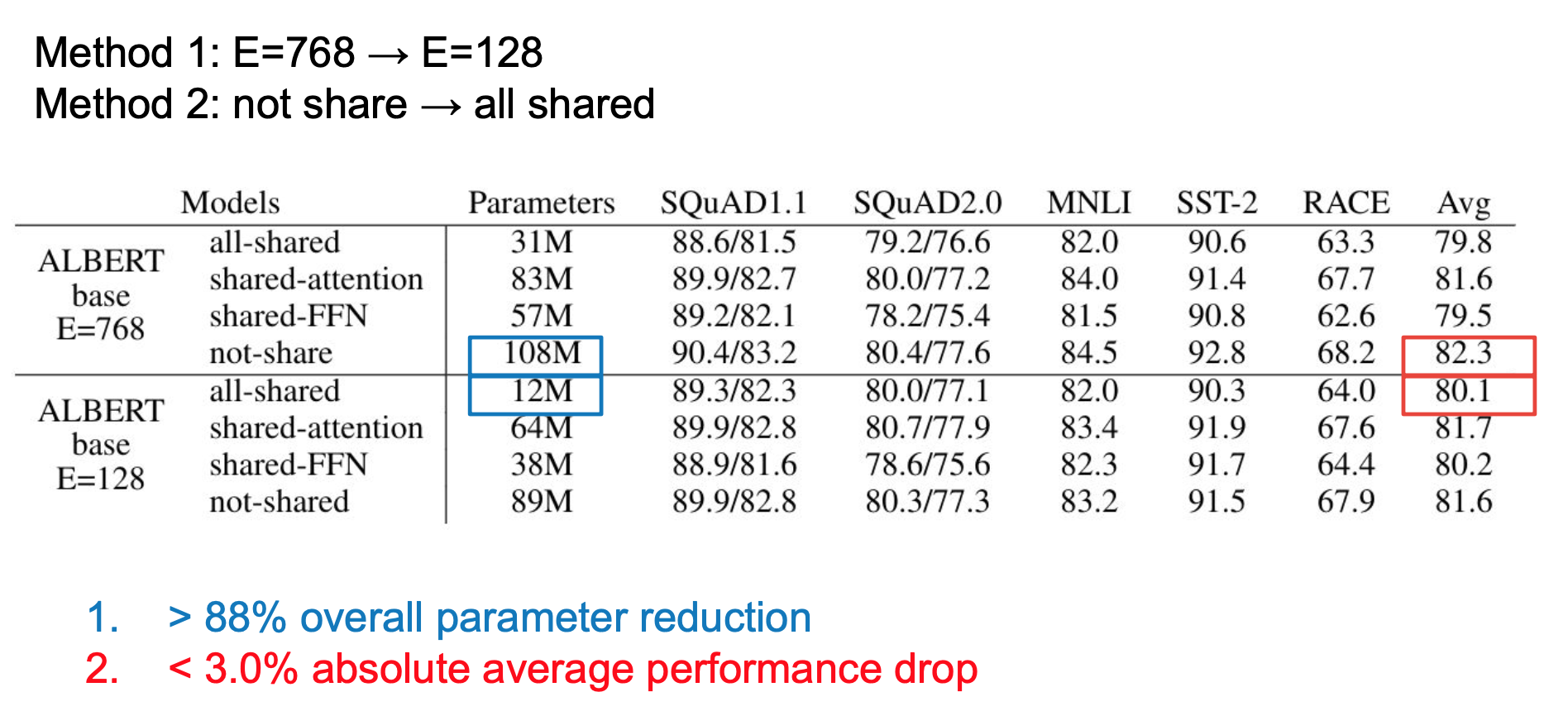
方法1和方法2结合的话,会减少总参数的88%,而精度损失不超过3%。
减少参数之后扩大模型
1、宽度
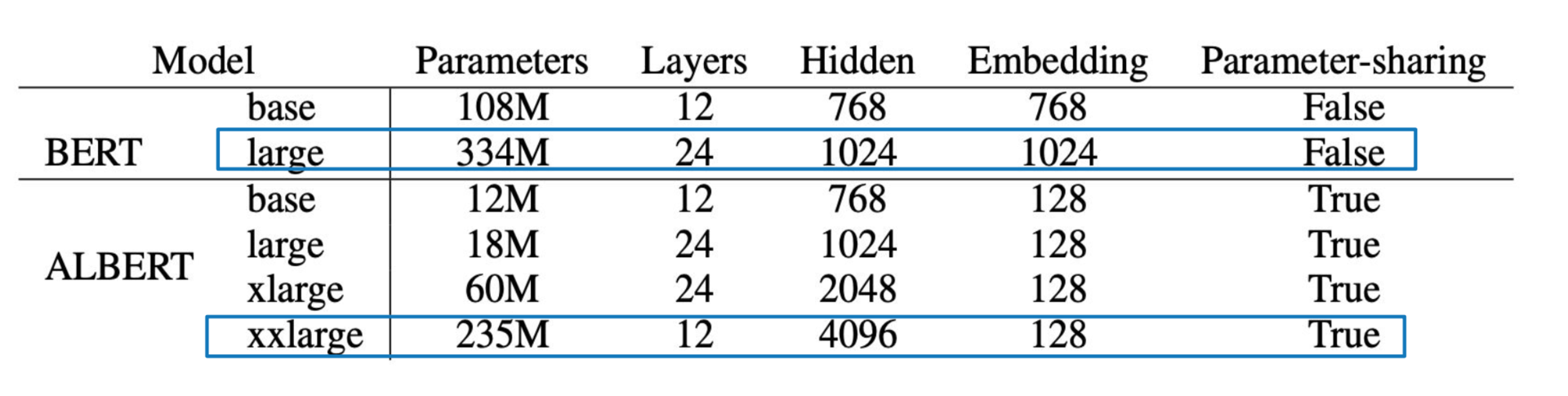
一个ALBERT-xxlarge 模型是BERT-large 模型的4倍宽度,但参数只有BERT-large的70%。
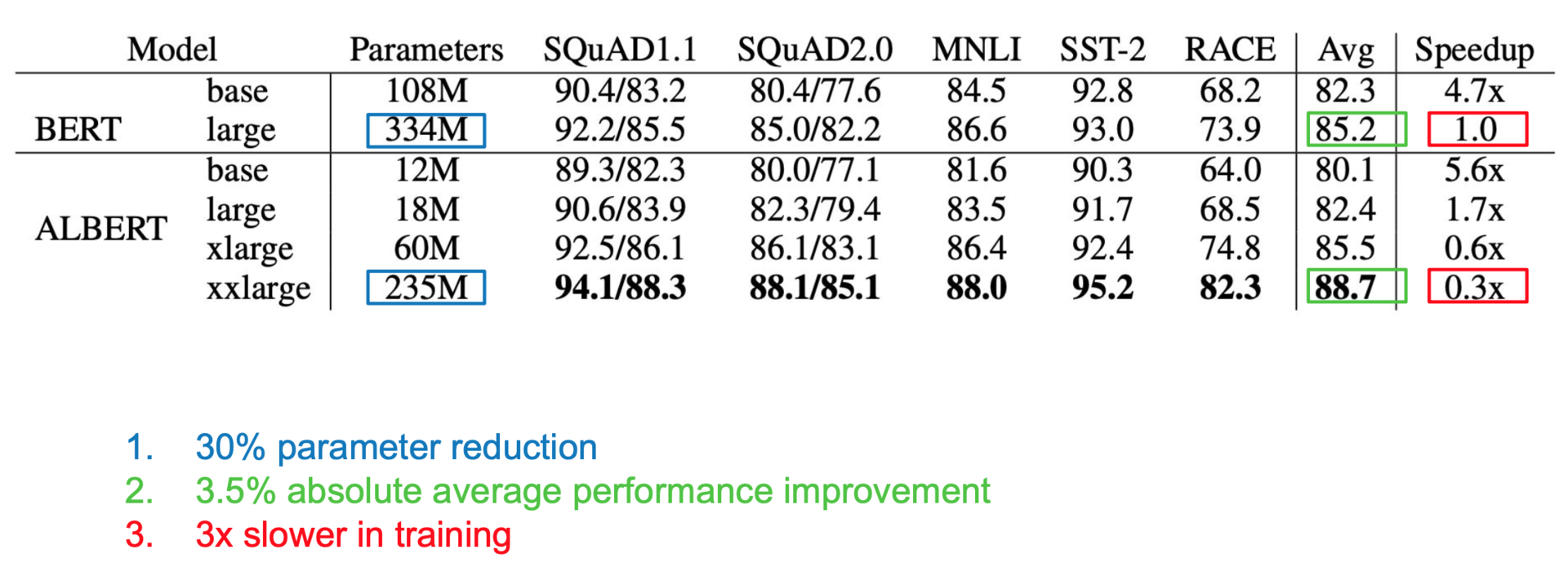
实验结果增加了3.5%的准确度。但实验时间增加了,因为并没有减少运算量。
2、深度
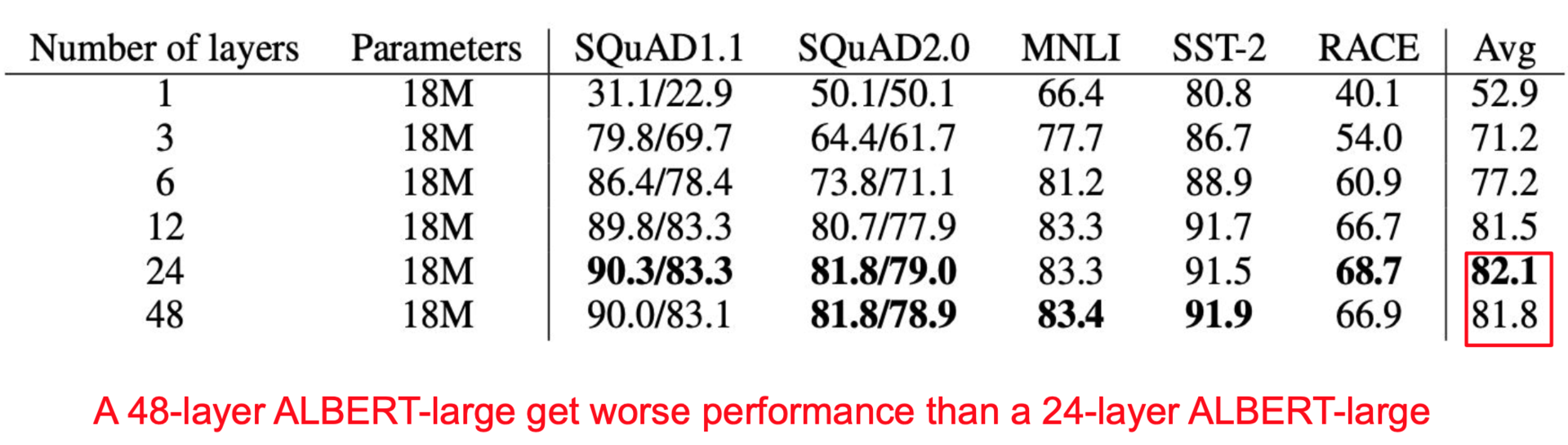
只增加深度的话ALBERT模型在48层的时候比只有24层的时候准确率低一点。

若是增加深度和宽度,12层和24层的表现不相上下。可以看出深度并不是一个很关键的因素。
相关模型:
海量中文预训练ALBERT模型:https://github.com/brightmart/albert_zh
Google research:https://github.com/google-research/ALBERT
