模型构建
import matplotlib.pyplot as plt
import pandas as pd
import tensorflow as tf
fashion_mnist = tf.keras.datasets.fashion_mnist
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
print(x_valid.shape, y_valid.shape)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
"""
model = tf.keras.Sequential()
# 输入层
# 将输入图片进行展开,输入是28*28的图像
# Flatten展平 将28*28二维矩阵展平为28*28一维向量
model.add(tf.keras.layers.Flatten(input_shape=[28, 28]))
# 全连接层(神经网络里最普通的一种神经网络,有层次,下一层所有单元和上一层单元都进行一一连接)
# 单元数300 activation激活函数
model.add(tf.keras.layers.Dense(300, activation="relu"))
model.add(tf.keras.layers.Dense(100, activation="relu"))
model.add(tf.keras.layers.Dense(10, activation="softmax"))
"""
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[28, 28]),
tf.keras.layers.Dense(300, activation="relu"),
tf.keras.layers.Dense(100, activation="relu"),
tf.keras.layers.Dense(10, activation="softmax")
])
model.compile(loss="sparse_categorical_crossentropy",
optimizer="adam",
metrics=["accuracy"])
print(model.layers)
print(model.summary())
history = model.fit(x_train, y_train, epochs=10,
validation_data=(x_valid, y_valid))
type(history)
print(history.history)
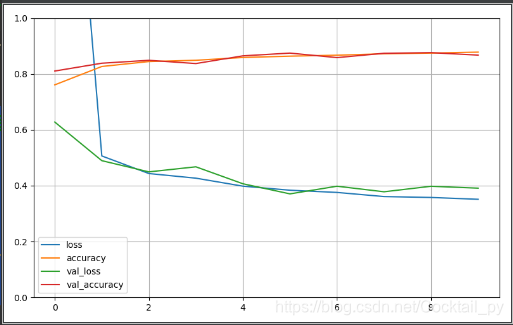
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
plot_learning_curves(history)
2-4实战分类之模型构建