目录
1 LR (Logistic Regression)
1.1 原理
逻辑回归,将各特征进行加权和,经过sigmoid变换函数映射到[0,1]之间,得到预估分值,计算如下:
p = s i g m o i d ( ∑ i = 1 n w i x i + b ) p = sigmoid(\sum_{i=1}^{n}w_ix_i +b) p=sigmoid(i=1∑nwixi+b)
做一个二分类任务,可用交叉熵loss作为损失函数。
1.2 优点
- 模型简单,速度快
- 可解释性强,可扩展性强
1.3 缺点
- 没有利用高维特征,表达能力有限
- 需要做较多的特征工程
- 模型不能自动进行特征交叉组合学习,需要人工提交设计特征交叉组合
2 FM (Factorization Machines)
2010 FM Factorization Machines
2.1 解决什么问题
- 解决LR不能主动学习特征交叉组合问题
- 解决特征稀疏,特征交叉,权重矩阵稀疏学习困难问题
- 解决特征交叉组合,模型参数量过大,复杂度高问题
2.2 计算公式
我们先来看下FM是怎么计算的,公式如下:
y ( x ) ^ : = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n ∑ j = i + 1 n < v i , v j > x i x j \hat{y(x)}:= w_0 +\sum_{i=1}^nw_ix_i + \sum_{i=1}^n\sum_{j=i+1}^n<v_i, v_j>x_ix_j y(x)^:=w0+i=1∑nwixi+i=1∑nj=i+1∑n<vi,vj>xixj
所以,模型需要学习的参数有三个变量:
- 全 局 的 偏 置 项 : w 0 ∈ R 全局的偏置项:w_0 \in R 全局的偏置项:w0∈R
- n 个 特 征 , 每 个 特 征 对 应 的 权 重 : w ∈ R n n个特征,每个特征对应的权重:w\in R^n n个特征,每个特征对应的权重:w∈Rn,
- 特征 x i x_i xi与特征 x j x_j xj交叉的权重 w i , j : = < v i , v j > w_{i,j} := <v_i, v_j> wi,j:=<vi,vj>, 其中 w i , j ∈ R w_{i,j} \in R wi,j∈R是根据隐向量矩阵 V V V中第 i i i行向量 v i v_i vi与第 j j j行向量 v j v_j vj做点乘学习得来: V ∈ R n × k V \in R^{n \times k} V∈Rn×k
2.3 如何理解 w i , j : = < v i , v j > w_{i,j}:=<v_i, v_j> wi,j:=<vi,vj>
2.3.1 直观理解
在FM中,通过隐向量来学习特征的交叉权重,也就是每个特征 x i x_i xi对应一个隐向量 v i v_i vi,而 n n n个特征构成的隐向量矩阵 V ∈ R n × k V \in R^{n \times k} V∈Rn×k, 其中第 i i i行代表的是特征 x i x_i xi对应的隐向量,每个隐向量 v i ∈ R k v_i \in R^k vi∈Rk是一个 k k k维度的向量,所以特征 x i x_i xi和 x j x_j xj的交叉权重 w i , j w_{i,j} wi,j由对应的隐向量 v i v_i vi和 v j v_j vj做dot product点乘求得。
2.3.2 矩阵乘法
首先我们来看下公式的具体展开计算形式:
< v i , v j > : = ∑ f = 1 k v i , f . v j , f <v_i, v_j>:=\sum_{f=1}^kv_{i,f}. v_{j,f} <vi,vj>:=f=1∑kvi,f.vj,f
其中 v i , v j ∈ R k v_i, v_j \in R^k vi,vj∈Rk分别表示的是隐向量矩阵 V V V的第 i i i行和第 j j j行,两个向量做点乘。原因如下:
任何一个正定矩阵 W W W,存在一个矩阵 V V V,使得:
W = V V t W = VV^t W=VVt
交叉矩阵 W ∈ R n × n W \in R^{n\times n} W∈Rn×n,里面的每个元素 w i , j w_{i,j} wi,j是由矩阵中的第 i i i行和第 j j j行做点乘得来的。
如下图所示:
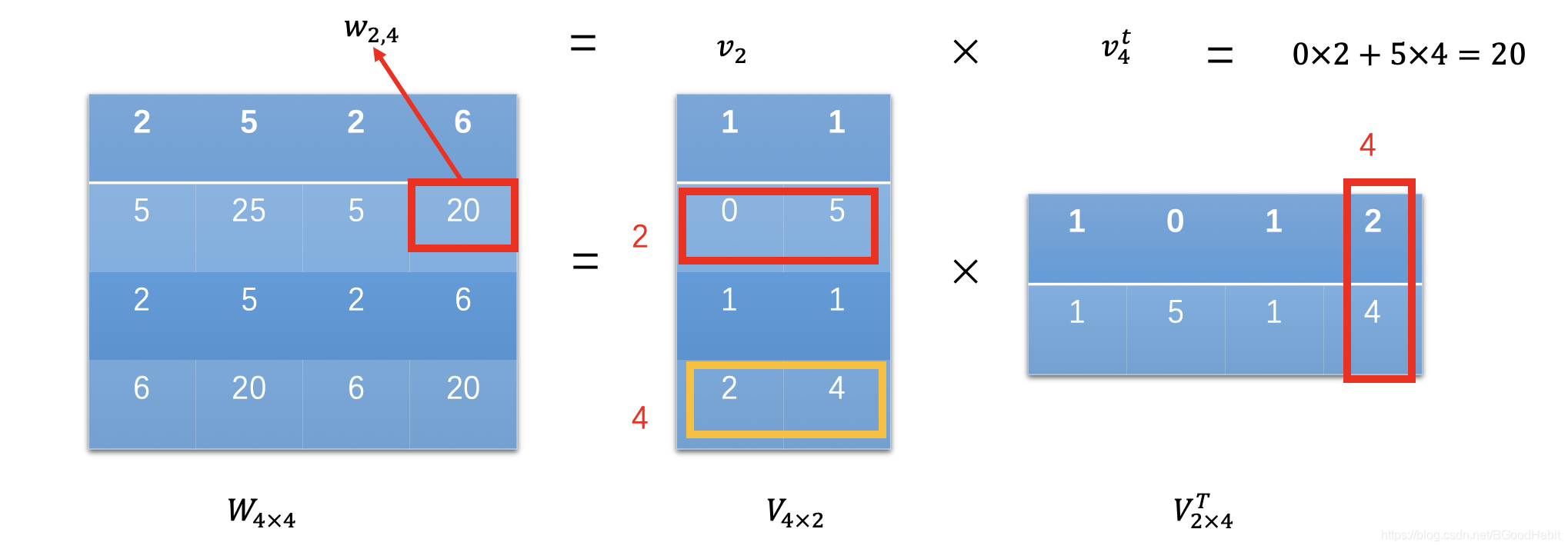
矩阵 W ∈ R 4 × 4 W \in R^{4\times 4} W∈R4×4,可以通过矩阵 V ∈ R 4 × 2 V \in R^{4 \times 2} V∈R4×2和其转置矩阵 V T V^T VT相乘得来, W W W中的每个元素 w i , j w_{i,j} wi,j是矩阵 V V V中的第 i i i行 v i v_i vi与转置矩阵 V T V^T VT的第 j j j列 v j t v^t_j vjt相乘得来,而矩阵的第 j j j行的值就是其转置的第 j j j列的值 v i = v j t v_i=v^t_j vi=vjt,所以:
w i , j = < v i , v j t > = < v i , v j > = ∑ f = 1 k v i , f . v j , f w_{i,j} =<v_i, v^t_j>=<v_i, v_j>=\sum_{f=1}^kv_{i,f}. v_{j,f} wi,j=<vi,vjt>=<vi,vj>=f=1∑kvi,f.vj,f
2.4 如何理解交叉特征权重参数学习量级由 n ( n − 1 ) 2 \frac{n(n-1)}{2} 2n(n−1)减少到 n × k n\times k n×k
我们来看下, n n n维的特征向量两两交叉,需要学习的参数个数。如下图所示:
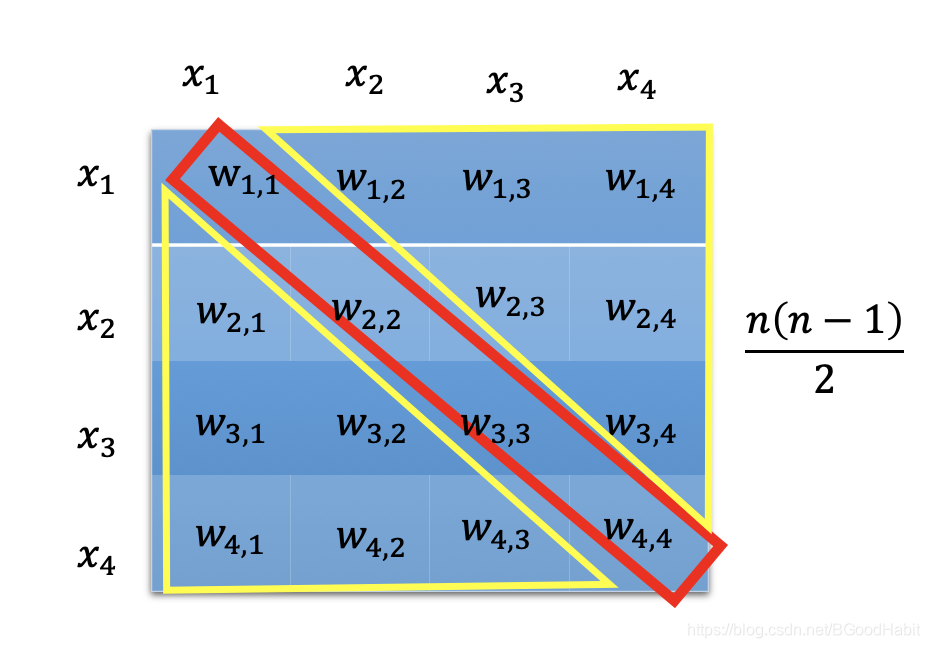
假设特征个数有4个,则交叉形成的矩阵是一个 4 × 4 4 \times 4 4×4的对称权重参数,对角线是特征自身的交叉去除 (上图的红色部分),剩余的对称部分取一半 (上图的黄色部分),所以 n n n个特征,两两交叉需要学习的参数个数为 n ( n − 1 ) 2 \frac{n(n-1)}{2} 2n(n−1)。
而在FM中,交叉的权重参数 w i , j w_{i,j} wi,j是通过矩阵 V V V中隐向量学习得来,而 V ∈ R n × k V \in R^{n \times k} V∈Rn×k,模型只需要学习参数矩阵 V V V,则特征交叉参数学习量变化形式如下:
n ( n − 1 ) 2 → n × k \frac{n(n-1)}{2} \to n\times k 2n(n−1)→n×k
2.5 FM模型的时间复杂度如何从 O ( k n 2 ) O(kn^2) O(kn2)变到 O ( k n ) O(kn) O(kn)
让我们再来写一篇FM的计算公式:
y ( x ) ^ : = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n ∑ j = i + 1 n < v i , v j > x i x j \hat{y(x)}:= w_0 +\sum_{i=1}^nw_ix_i + \sum_{i=1}^n\sum_{j=i+1}^n<v_i, v_j>x_ix_j y(x)^:=w0+i=1∑nwixi+i=1∑nj=i+1∑n<vi,vj>xixj
时间复杂度为 O ( k n 2 ) O(kn^2) O(kn2),所有的pairwise交叉都需要计算,且 < v i , v j > <v_i, v_j> <vi,vj>每次需要计算 k k k次,如下图所示:
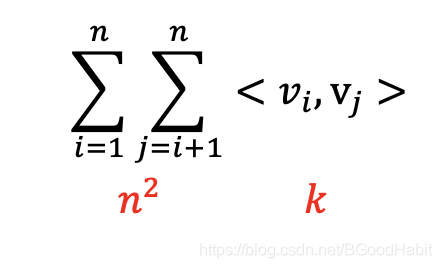
让我们对等式进行一步一步变化:
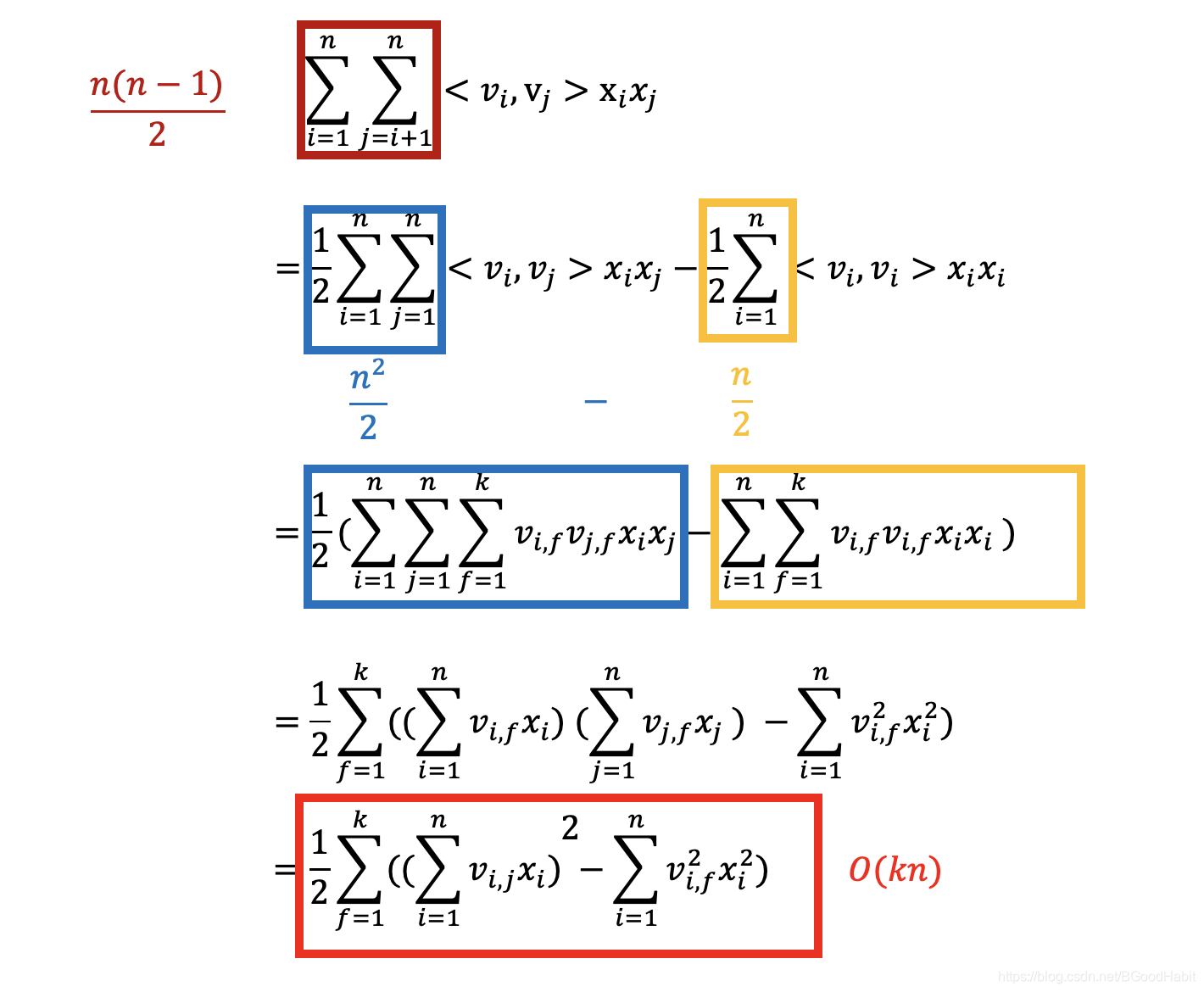
通过逐步的化简操作,最后的等式结果时间复杂度变成了 O ( k n ) O(kn) O(kn)。在tensorflow计算中,用矩阵计算形式如下:
1 2 ∑ f = 1 k ( ( ∑ i = 1 n v i , f 2 x i 2 ) \frac{1}{2}\sum_{f=1}^k((\sum_{i=1}^nv_{i,f}^2x_i^2) 21f=1∑k((i=1∑nvi,f2xi2)
= t f . r e d u c e _ s u m ( ( 1 2 ( ( X V ) 2 − X 2 V 2 ) ) , a x i s = 1 ) =tf.reduce\_sum((\frac{1}{2}((XV)^2-X^2V^2)), axis=1) =tf.reduce_sum((21((XV)2−X2V2)),axis=1)
其中 X ∈ R b × n X \in R^{b \times n} X∈Rb×n代表的是输入batch size为b,特征个数为n的样本, V ∈ R n × k V \in R^{n\times k} V∈Rn×k隐向量矩阵。
2.6 模型参数梯度计算
FM模型参数, w 0 , w 和 V w_0, w和V w0,w和V可以通过梯度下降算法学习,从上述的 y ( x ) ^ \hat{y(x)} y(x)^计算公式可以得出梯度计算公式如下:
∂ ∂ θ y ^ ( x ) = { 1 i f θ i s w 0 x i i f θ i s w i x i ∑ j = 1 n v j , f x j − v i , f x i 2 i f θ i s v i , f \frac{\partial}{\partial \theta}\hat{y}(x) = \begin{cases} 1 \text{ } \text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ } if \text{ }\text{ }\theta \text{ }is \text{ }w_0 \\\\ x_i \text{ } \text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ } \text{ }if \text{ }\theta \text{ }is \text{ }w_i \\\\ x_i \sum_{j=1}^nv_{j,f}x_j - v_{i,f}x_i^2 \text{ }\text{ }\text{ }\text{ }\text{ }\text{ } if \text{ }\theta \text{ }is\text{ } v_{i,f} \end{cases} ∂θ∂y^(x)=⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧1 if θ is w0xi if θ is wixi∑j=1nvj,fxj−vi,fxi2 if θ is vi,f
其中 ∑ j = 1 n v j , f x j \sum_{j=1}^nv_{j,f}x_j ∑j=1nvj,fxj相对于 i i i是独立的,所以可以提前计算好。整体来说,每个梯度计算可以在一个常数量时间 O ( 1 ) O(1) O(1)完成。
2.7 模型的应用
FM模型可以用在多种预测任务中,回归任务,分类任务,排序任务都可以。
应 用 = { 回 归 ( r e g r e s s i o n ) : 可 以 直 接 用 来 做 回 归 任 务 , 用 最 小 化 均 方 误 差 进 行 优 化 学 习 b i n a r y 分 类 任 务 ( b i n a r y c l a s s i f i c a t i o n ) : 可 以 用 h i n g e l o s s 或 者 l o g i t l o s s 作 为 损 失 函 数 排 序 任 务 ( r a n k i n g ) : 通 过 预 测 的 分 值 y ( x ) ^ 进 行 排 序 , 每 次 可 以 用 p a i r w i s e 分 类 l o s s , 通 过 优 化 一 个 p a i r 对 ( x ( a ) , x ( b ) ) ∈ D 进 行 学 习 应用 = \begin{cases} 回归 (regression):可以直接用来做回归任务,用最小化均方误差进行优化学习 \\\\ binary分类任务 (binary classification): 可以用hinge loss或者logit loss作为损失函数 \\\\ 排序任务 (ranking): 通过预测的分值\hat{y(x)}进行排序,每次可以用pairwise分类loss,通过优化一个pair对(x^{(a)}, x^{(b)}) \in D进行学习 \end{cases} 应用=⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧回归(regression):可以直接用来做回归任务,用最小化均方误差进行优化学习binary分类任务(binaryclassification):可以用hingeloss或者logitloss作为损失函数排序任务(ranking):通过预测的分值y(x)^进行排序,每次可以用pairwise分类loss,通过优化一个pair对(x(a),x(b))∈D进行学习
3 FFM
Field-aware Factorization Machines for CTR Prediction
3.1 引入Field-aware
FFM相比FM基础上,引入了Field-aware,这是什么意思呢?一句话总结就是:受到PITF中个性化推荐启发,特征划分不同的域,所以相对FM中隐向量矩阵 V ∈ R n × k V\in R^{n\times k} V∈Rn×k,变为 V ∈ R n × f × k V\in R^{n\times f\times k} V∈Rn×f×k,其中 f f f表示的是filed个数。在FFM中,每个特征在每个field上有对应不同的隐向量。
那具体不同filed下的特征交叉权重怎么计算呢?用论文中给的例子进行说明,如下图所示:

在FM中,特征两两交叉权重计算如下:
ϕ F M = V E S P N . V N i k e + V E S P N . V M a l e + V N i k e . V M a l e \phi_{FM} = V_{ESPN} . V_{Nike} + V_{ESPN} . V_{Male} + V_{Nike}.V_{Male} ϕFM=VESPN.VNike+VESPN.VMale+VNike.VMale
在FM中,<ESPN, Nike>和<ESPN, Male>的两两特征的交叉权重学习,ESPN特征对应的隐向量都是相同的 V E S P N V_{ESPN} VESPN,而Nike属于Advertiser域,Male属于Gender域,不同的域之间的交叉按理是有差别的,为了体现这种差别,更加细粒度的计算这种差异,这也是在FFM中,引入Filed的概念,那我们来看下,在FFM中,计算形式如下:
ϕ F F M = V E S P N , A . V N i k e , P + V E S P N , G . V M a l e , P + V N i k e , G . V M a l e , A \phi_{FFM} = V_{ESPN,A}.V_{Nike,P}+V_{ESPN,G}.V_{Male,P}+V_{Nike,G}.V_{Male,A} ϕFFM=VESPN,A.VNike,P+VESPN,G.VMale,P+VNike,G.VMale,A
而在FFM中,<ESPN, Nike>和<ESPN, Male>两两交叉特征中的ESPN是不同的隐向量。
说明如下:
- 第一:<ESPN, Nike>两个特征的交叉权重,是由A域下的ESPN隐向量 V E S P N , A V_{ESPN, A} VESPN,A(因为Nike属于A域)与P域下的Nike隐向量 V N i k e , P V_{Nike,P} VNike,P(因为ESPN属于P域)做向量内积计算得来
- 第二:<ESPN, Male>是由G域下的ESPN隐向量 V E S P N , G V_{ESPN, G} VESPN,G(因为Male属于G域)与P域下的Nike隐向量 V N i k e , P V_{Nike, P} VNike,P(因为ESPN属于P域)做向量内积得来
3.2 FM与FFM差异对比
用一个图表汇总如下:
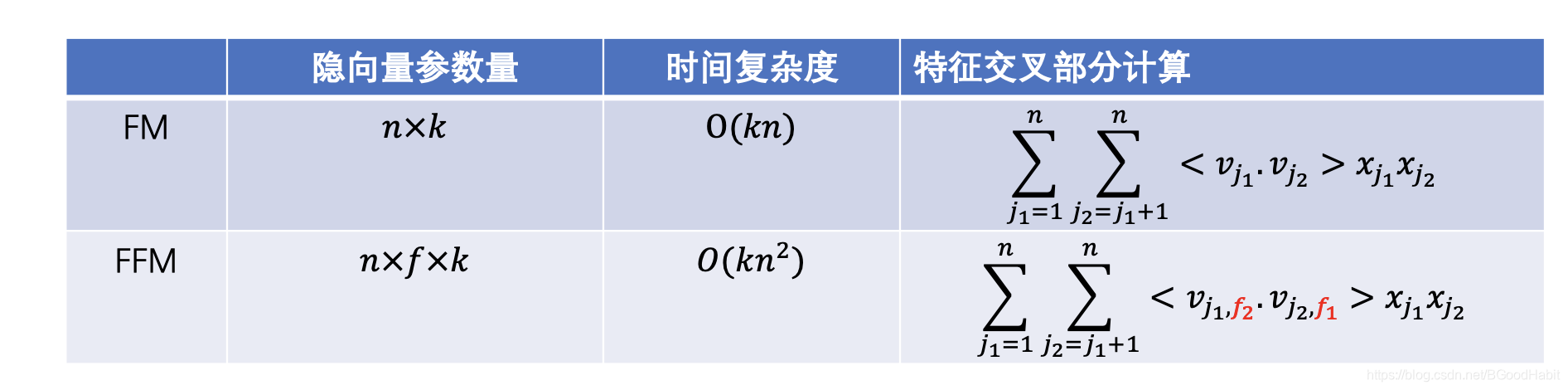
注意:FFM中特征交叉部分计算隐向量的 v v v对应的索引,隐向量在filed索引取的是与该特征交叉的特征所在的filed域索引,如上图中标红的 f 2 f_2 f2表示的是 x j 2 x_{j_2} xj2特征对应的filed,而 f 1 f_1 f1代表的是特征 x j 1 x_{j_1} xj1对应的filed,容易搞混。
4 Wide & Deep
4.1 原理
wide & Deep Learning for Recommender Systems
- wide: 是一个线性模型,对输入的原始特征 x = [ x 1 , x 2 , . . . , x d ] x=[x_1, x_2,...,x_d] x=[x1,x2,...,xd]以及经过转换后的特征 ϕ ( x ) \phi(x) ϕ(x),进行加权求和: y = w T [ x , ϕ ( x ) ] + b y=w^T[x,\phi(x)]+b y=wT[x,ϕ(x)]+b
- deep: 一个前向的神经网络模型,稀疏的类别特征,转成稠密的embedding向量,经过模型的非线性变换,学习高阶的语义特征: a ( l + 1 ) = f ( W ( l ) a ( l ) + b ( l ) a^{(l+1)} = f(W^{(l)}a^{(l})+b^{(l)} a(l+1)=f(W(l)a(l)+b(l),其中 l l l是神经网络层数, f f f是激活函数, a ( l ) , b ( l ) 和 W ( l ) a^{(l)}, b^{(l)}和W^{(l)} a(l),b(l)和W(l)分别表示的是在第 l l l层的激活函数输出值,偏置项和模型的参数
4.2 结构
我们来看下模型的整体结构,如下图所示:
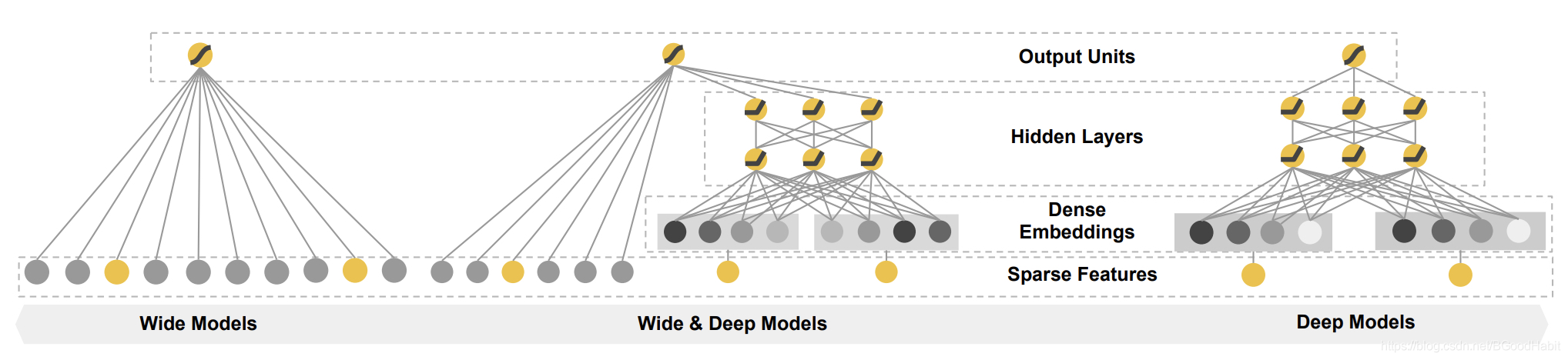
其中左边是wide部分,最右边是deep部分,然后将两部分合并到一起,将最后的输出结果相加,再经过sigmoid后得到输出,公式表达如下:
y ( x ) = σ ( w w i d e T [ x , ϕ ( x ) ] + w d e e p T a ( l f ) + b ) y(x) = \sigma(w_{wide}^T[x,\phi (x)] + w_{deep}^Ta^{(l_f)} + b) y(x)=σ(wwideT[x,ϕ(x)]+wdeepTa(lf)+b)
其中 ϕ ( x ) \phi(x) ϕ(x)表示的转换后的特征,最常见的一种就是cross-product 转换,定义形式如下:
ϕ k ( x ) = ∏ i = 1 d x i c k i c k i ∈ 0 , 1 \phi_k(x) = \prod_{i=1}^d x_i^{c_{ki}} \text{ } \text{ } c_{ki} \in {0,1} ϕk(x)=i=1∏dxicki cki∈0,1
其中 c k i c_{ki} cki是一个布尔型变量,如果第 i i i个特征属于第 k k k个转换 ϕ k \phi k ϕk,则为1,否则为0。
论文中给出的apps推荐应用中模型设计结构如下:
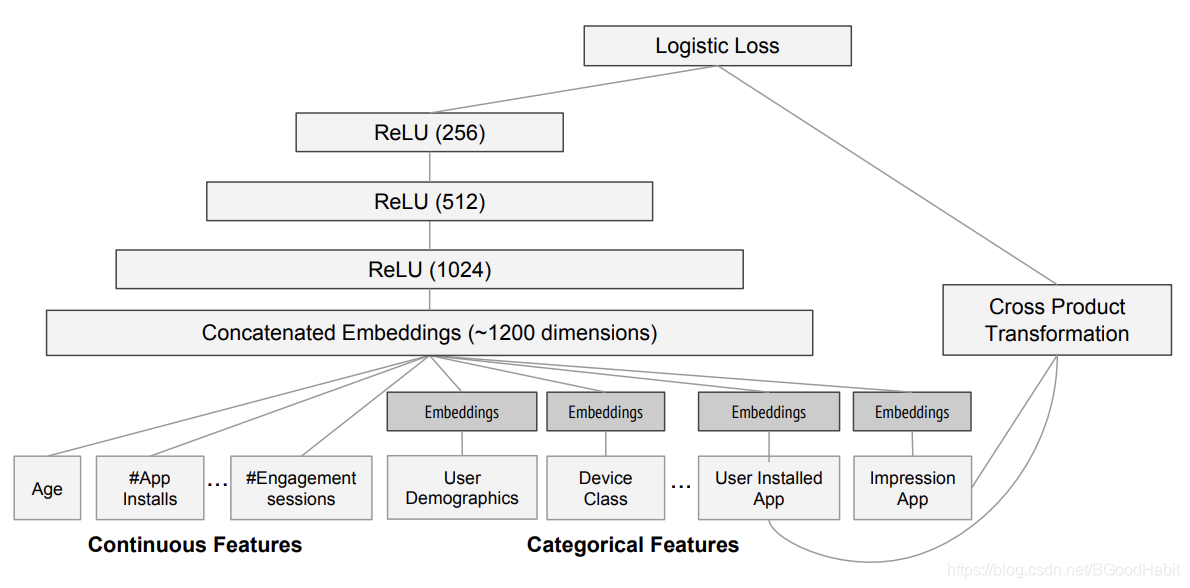
- wide部分:是用户安装过的apps与曝光的apps做cross-product转换
- deep部分:每个类属特征经过embddings层转换成32维度的特征,然后全部concat到一起,包括连续的统计特征,得到一个1200维度的向量,再经过3层的一个ReLu层,最后得到logistic输出。
5 DeepFM
5.1 原理
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
DeepFM是一个端到端的学习模型,相比Wide & Deep,不需要做特征工程(如cross-product等),DeepFM将FM的隐向量 V V V同时作为Deep的词向量参数,两者共享,让模型自动去学习低阶与高阶的特征交互。
5.2 结构
模型结构如下图所示:

其中wide 和deep部分共享相同的原始输入特征,原始特征输入是 m m m个filed: x = [ x f i l e d 1 , x f i l e d 2 , . . . , x f i l e d m ] x=[x_{filed_1}, x_{filed_2}, ..., x_{filed_m}] x=[xfiled1,xfiled2,...,xfiledm],每个 x f i l e d i x_{filed_i} xfiledi是一个向量表示,包括了categorical fields (比如性别,位置等)以及continuous fields (比如年龄等),每个categorical field是一个one-hot编码的向量,而每个continuous field的可以用自己本身的值代表,或者离散化后编码成one-hot向量。其中的Dense向量层与FM的隐向量 V V V共享,所以向量的维度等于 V V V中隐向量的 k k k值,是一个端到端,模型同时学习低阶和高阶特征交互的模型,相比 google的Deep & Wide少了特征工程,同时模型在性能和效果上都有提升。
5.2.1 FM
再来回顾下,特征的二阶交叉学习,若直接学习两个特征的交叉权重,只有在两个特征都同时存在的情况下,才可以学习,但在特征很稀疏的情况下,特征交叉乘积大部分为0。所以FM通过引入隐向量矩阵 V V V,将特征 x i x_i xi的隐向量 v i v_i vi与特征 x j x_j xj的隐向量 v j v_j vj做内积来学习特征 x i x_i xi与特征 x j x_j xj交叉的权重 w i j w_{ij} wij,不管特征 x i x_i xi和 x j x_j xj是否同时存在,都可以有效的训练模型。
FM部分:
- 假设field=20, 每个field有50个取值,隐向量大小 k = 100 k=100 k=100
- 则隐向量矩阵 V ∈ R 1000 × 100 V \in R^{1000 \times 100} V∈R1000×100, 因为 20 × 50 = 1000 20 \times 50=1000 20×50=1000,所以 V V V中的行大小为1000,而输入的 X ∈ R 256 × 1000 X\in R^{256 \times 1000} X∈R256×1000,其中256表示的是一个batch size,1000对应one-hot编码
- FM计算,其中交叉的 w i j w_{ij} wij权重是 V V V中第i行向量与第j行向量做内积得来,O(nk)的复杂度,交叉部分计算公式为: 1 / 2 × ( ( X V ) 2 − X 2 V 2 ) 1/2\times ((XV)^2-X^2V^2) 1/2×((XV)2−X2V2),再与一阶特征加权和相加,得到FM部分的输出: y F M y_{FM} yFM
5.2.2 Deep
在Deep部分,与上述介绍的Deep & Wide的最大区别就是Deep部分的词向量权重参数是FM部分的隐向量举证 V V V。那么我们来看下,在Deep部分具体计算流程:
- 输入: f e a t u r e _ i n d s ∈ R 256 × 20 feature\_inds \in R^{256 \times 20} feature_inds∈R256×20, 其中256是batch,20是field总数量,其中每个field是跨越50个值的。
- 通过输入的index,经过embedding向量层后,其中embeedding的参数权重是FM中的 V ∈ R 1000 × 100 V\in R^{1000\times 100} V∈R1000×100,得到向量输出 e ∈ R 256 × 20 × 100 e\in R^{256 \times 20 \times 100} e∈R256×20×100,若是直接将每个filed的特征concat,则 e ∈ R 256 × 2000 e \in R^{256 \times 2000} e∈R256×2000,再输入到Deep三层全连接层DNN中,得到Deep的输出 y d e e p y_{deep} ydeep
5.2.3 DeepFM
最后将两者的输出相加,经过一个sigmoid函数,就可以得到模型的预测分值
y o u t = σ ( y F M + y d e e p ) y_{out}=\sigma(y_{FM}+y_{deep}) yout=σ(yFM+ydeep)
6 DSSM (Deep Structured Semantic Models)
6.1 原理
Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
将输入的原始的高维的one-hot的term向量,通过DNN模型学习,映射到低维的语义向量;通过计算query与doc的向量cos值,进而来衡量query与doc的相似性。
6.2 word hashing
目的:降低输入维度,由于bag-of-words 词表大小将会比较庞大,论文中给出有500k的一个数量级,所以为了降低复杂度,用n-gram进行字母粒度的切分,词的大小可以降低30k的一个量级。
问题: 有可能不同的词,会有相同的n-gram模式,导致冲突问题。
(发这篇paper可能那时候word2vec还没广泛应用,词向量直接解决上述问题)
6.3 模型结构
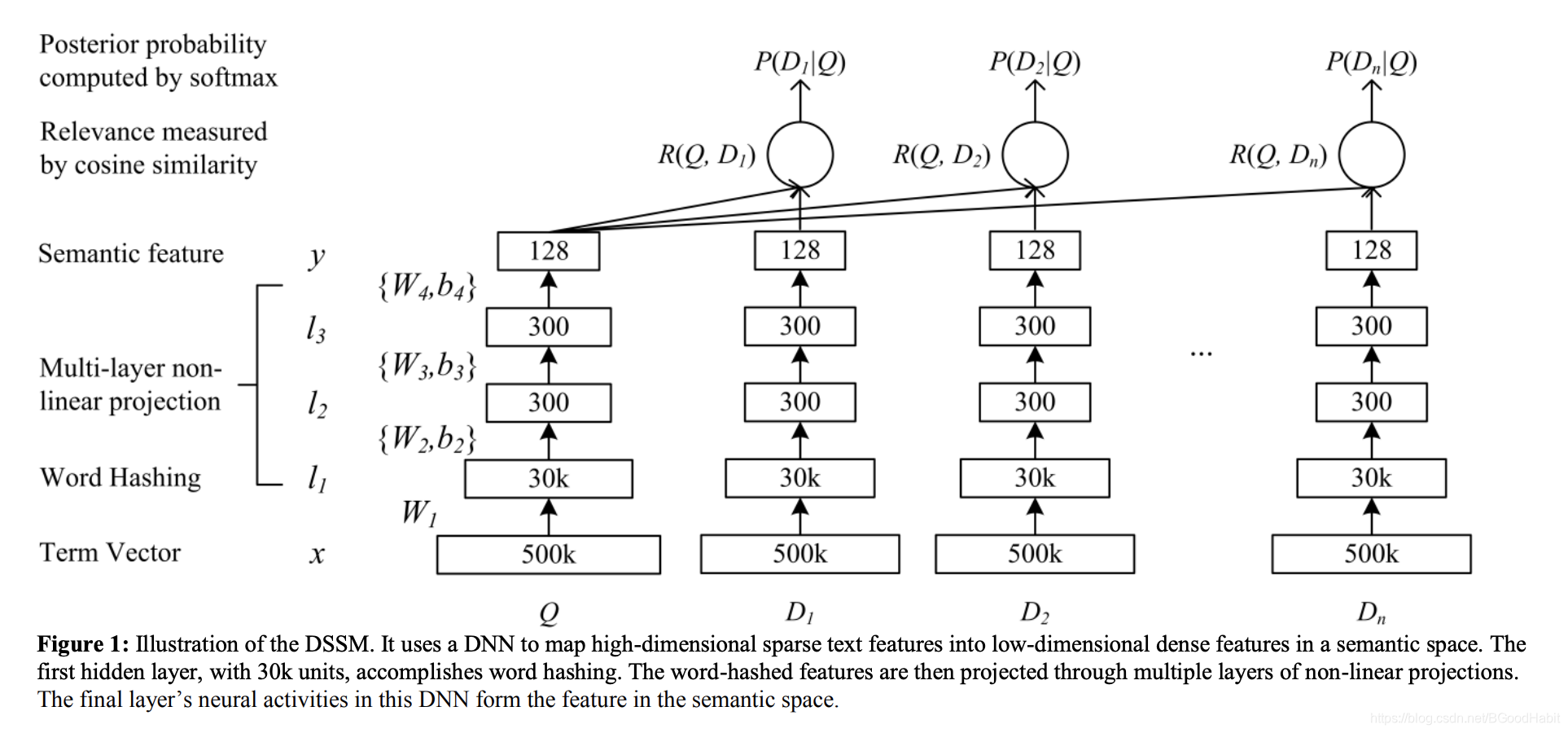
模型的结构是一个DNN结构,query和doc分别经过模型得到语义向量表征 y q 和 y d y_q和y_d yq和yd,两者的语义相关分值通过衡量两个向量的cos值:
R ( q , d ) = c o s i n e ( y q , y d ) = y q T y d ∣ y q ∣ ∣ y d ∣ R(q,d) = cosine(y_q, y_d) = \frac{y_q^Ty_d}{\begin{vmatrix} y_q \end{vmatrix}\begin{vmatrix} y_d \end{vmatrix}} R(q,d)=cosine(yq,yd)=∣∣yq∣∣∣∣yd∣∣yqTyd
模型训练:输入的是一个list序列,其中包含了一个query,与点击的doc和未点击的doc构成的序列 ( Q , D ) (Q,D) (Q,D),其中 D D D包含了点击的doc和未点击的doc,论文里介绍的是一个点击的doc和4个为点击的doc组成的 ( Q , D + , D 1 − , D 2 − , D 3 − , D 4 − ) (Q, D^+, D_1^-, D_2^-, D_3^-, D_4^-) (Q,D+,D1−,D2−,D3−,D4−),query与每个doc计算cos相似分值,然后用softmax函数计算概率分布:
P ( D ∣ Q ) = e x p ( γ R ( Q , D ) ) ∑ D t ∈ D e x p ( γ R ( Q , D t ) ) P(D|Q) = \frac{exp(\gamma R(Q,D))}{\sum_{D^t \in D}exp(\gamma R(Q,D^t))} P(D∣Q)=∑Dt∈Dexp(γR(Q,Dt))exp(γR(Q,D))
模型可以通过基于梯度的数值优化算法求解。