无信息搜索是只有信息的一些真实的条件,那么有信息搜索就是除了真实的条件还有一些估计的条件,以让我们能够定义评价函数。
简单地将,就是我们现在知道了,目标距离我们大概有多远,注意,是大概!大概!大概!!估计值是有信息搜索的重点之一,好的估计函数可以大大提高算法的性能。
最佳优先搜索
基本思路:通过对每一个节点计算评价函数f(n)值,找到一个f(n)最低的未扩散的节点。和一致代价搜索很像。但是这里的评价函数是估计值,而一致搜索中的代价是计算真实值。
大多数评价函数由启发函数h构成:h(n)节点n到目标节点的最小代价估计值
贪婪最佳优先搜索
首先扩展与目标节点估计距离最近的节点。
和上面的最佳优先搜索有什么区别呢?首先,他们的评价函数都是计算的估计值,而没有真实值的参与,但是,最佳优先搜索计算的是距离当前点最近的点,而贪婪最佳优先搜索计算的是距离目标点最近的点。
a※树搜索
就是对贪婪的改进,引进了当前节点与下一节点的距离。这个时候,他的评价函数就变成了:
f(n)=g(n)+h(n):f(n)通过节点n到达目标节点的总评估代价(距离);g(n)到达节点n已花费的代价;h(n)节点n到目标节点的评估代价(距离)
也就是说,评价函数=当前节点与下一节点的实际距离+下一节点与目标节点的估计距离。
很好理解是不是?类似于画了一条从当前点到目标点的折线,从而选择下一个点。
但这里,有个问题:为什么这样的算法找到的路径会是最优的呢?
首先,这个问题要分为两种情况:
第一种:路径上的任何一点与目标节点的估计距离小于直线距离,即可采纳性。
简单地讲,可以理解为“有弯路,且这个弯路在目标点与最后一层点之间”
这样有什么效果呢?这样的话,路径上的任何一个点出来,去找目标点的时候,只能先找到最优路径上的下一个点,而其他的所有的点,计算到目标节点的估计距离,均会比最优路径上的下一个点大。
证明:假设start为开始节点,G为目标节点,n在最短路径上,G2是局部最优。
那么只要证明f(G2)>f(n)<证明路径是最优的>和f(G2)>f(G)<没到达G之前,
G2不会出队>即可。
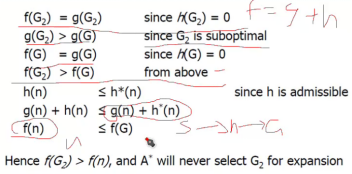
第二种:路径上的任何两点的估计距离小于直线距离,即一致性
简单地将,就是路径上所有的路都是弯曲的,没有直路。
这种情况下,我们只要找到距离目标点估计距离最小的点,那么必定是最优路径上的点。
证明:A*根据f值从小到大扩展结点;A*选择扩散结点n时,就已经找到了达到
结点n的最优路径。如若不是,假设存在另一个边缘结点n’在到达n的最优路径
上,因为由一致性可得到f(n’)<f(n),所以n’会被优先选择
由此可以看到,在这两种情况下,a※树搜索算法可以得到最优结果。
一致性是可采纳性的特例,类比于图搜索是树搜索的特例
当启发式算法只能满足可采纳性而不能满足一致性,那么此时树搜索是最优的,但图搜索不是最优的;若满足一致性,那么搜索结果应该相同。
