机器学习实战(Machine Learning in Action)
CH05 logistic regression 学习笔记(一)梯度上升优化算法
import numpy as np
import math
%matplotlib inline
import matplotlib.pyplot as plt
def loadDataSet():
dataMat = []
labelMat = []
with open('testdata.txt', 'r') as fr:
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat, labelMat
加载数据
返回 dataMat(list) 和 labelMat(list)
dataMat.len 为 (dataSize)(float)
labelMat.len 为 (dataSet)(int)
def sigmoid(inX):
return 1.0/(1 + np.exp(-inX))
sigmoid 函数
σ(z)=1+e−z1
值得注意的是
σ′(z)=σ(z)(1−σ(z))
sigmoid 函数经常被用于二分类,当
σ(z)<0.5 时,被认为
P=0。而
σ(z)≥0.5 时,被认为
P=1。
在 logistic regression 里,我们把每个特征乘于一个回归系数,然后相加,将得到的总和带进
σ(z) 中,得到一个
0∼1 的值。
即
z=ω0x0+ω1x1+⋯+ωnxn,如果采用向量的写法可以写成
z=wTx。
其中,
ω 是回归系数(权重)的了列向量,而
x 是输入的特征值列向量。
因此我们现在剩下的问题就是如何求解回归系数(权重
ω)。
def gradAscent(dataMatIn, classLabels):
dataMatrix = np.mat(dataMatIn)
labelMat = np.mat(classLabels).transpose()
m, n = np.shape(dataMatrix)
alpha = 0.001
maxCycles = 100
weights = np.ones((n, 1))
for k in range(maxCycles):
h = sigmoid(dataMatrix * weights)
error = labelMat - h
weights = weights + alpha * dataMatrix.transpose() * error
return weights
梯度上升(gradient ascent)
梯度
梯度是一个向量,表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该方向变化最快(梯度的方向),变化率最大(梯度的模)。
我们将梯度记为
∇,则
f(x,y) 的梯度为
∇f(x,y)=[∂x∂f(x,y)∂y∂f(x,y)] 。
表示我们现在需要沿着
x 轴移动
∂x∂f(x,y),沿着
y 轴移动
∂y∂f(x,y) 。(
f(x,y) 要在这些点上有意义且可微)
但是我们上面的式子中,只给出了梯度的方向和变化率,并没有给出步长,因此我们还要定义一个步长
α,
α 也会被称之为学习率(learning rate)。
最优化权重
在本节中,我们讨论的分类为二分类,因此类别非0即1。
我们设
x 为输入的特征向量,
ξ 为类别。
我们定义
P(ξ=1∣x)=σ(z)
显然
P(ξ=0∣x)=1−P(ξ=1∣x)=1−σ(z)=σ(−z)
因此,对于第
i 个样本,有
P(ξ=ξi∣xi)=P(ξ=0∣xi)1−ξiP(ξ=1∣xi)ξi=(1−σ(zi))1−ξiσ(zi)ξi
由于各个样本之间是相互独立的,联合概率为各个样本的乘积。因此我们可以得到关于权重向量
ω 的最大似然函数
L(ω)=i=1∏n(1−σ(z))1−ξi(σ(z))ξi(n 为样本总数)
两边同时取对数,得
ln L(ω)=i=1∑nln((1−σ(z))1−ξiσ(z)ξi)=i=1∑n((1−ξi)ln(1−σ(z))+ξiln σ(z))=i=1∑n((1−ξi)ln σ(−zi)+ξiln σ(zi))
当
L(ω) 最大时,此时的
ω 为回归系数最优解。
显然,若存在一个
ω 使得
L(ω) 取得最大值,同样也可使
ln L(ω) 取最大值。
因此,求解
ln L(ω) 的最大值与求解
L(ω) 的最大值是等效的。
现在的问题转换为求
ln L(ω) 的最大值。
我们使用梯度上升求
ω 的最大值,即
ω:=ω+α∇ln L(ω)
对于
ω 的第
j 个分量
ωj, 有
ωj:=ωj+α∂ωj∂ln L(ω)
∂ωj∂ln L(ω)=i=1∑n(−(1−ξi)(1−σ(−zi))+ξi(1−σ(zi)))∂ωj∂zi=i=1∑n((ξi−1)σ(zi)+ξi(1−σ(zi)))xj=i=1∑n(ξi−σ(zi))xj
即
∂ωj∂ln L(ω)=xT(ξ−σ(z))
上述代码中,我们令
error=ξ−σ(z)
最后我们可以得到梯度上升的式子为
ω:=ω+αxT(ξ−σ(z))
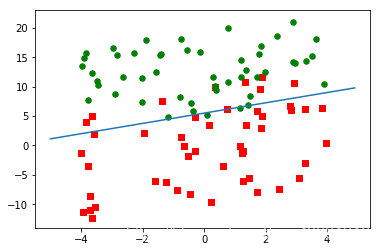
def plotBestFit(weights):
dataMat, labelMat = loadDataSet()
dataArr = np.array(dataMat)
n = np.shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i] == 1):
xcord1.append(dataArr[i, 1])
ycord1.append(dataArr[i, 2])
else:
xcord2.append(dataArr[i, 1])
ycord2.append(dataArr[i, 2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s = 30, c = 'red', marker = 's')
ax.scatter(xcord2, ycord2, s = 30, c = 'green')
x = np.arange(-5.0, 5.0, 0.1)
y = (-weights[0] - weights[1] * x)/weights[2]
ax.plot(x, y)
plt.show()
dataArr, labelMat = loadDataSet()
weights = gradAscent(dataArr, labelMat)
print(weights)
plotBestFit(weights.getA())
[[ 1.65879592]
[ 0.2642799]
[-0.30190436]]