Logistic回归的目的是寻找一个非线性函数Sigmoid的最佳拟合参数,求解过程可以由最优化算法来完成。在最优化算法中,最常用的就是梯度上升算法,听到这里可能感觉有点抽象,下面,会具体地说明,本文首先阐述Logistic回归的定义,然后介绍一些最优化算法,然后具体讲解梯度上升算法,同时给出python源代码并讲解一个例子。
在机器学习中,我们想要的函数应该是,能接受所有输入然后预测出类别,所谓训练是指根据已标记的数据(已知道类别),我们根据这些数据的特征和其标签的关系来建立某种联系,然后对于未知数据(有特征,但没有被标记的数据),通过训练的结果来猜测其标签。如下图所示为训练数据示例。
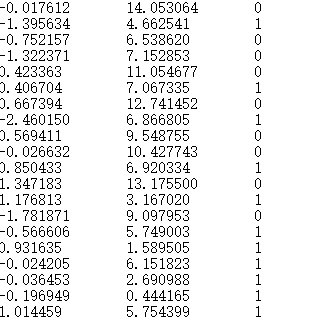
数据来自某本机器学习书中附带的数据,如上共有3列,每列的分割幅为('\t'),第一列和第四列分别为特征值,最后一列是标记,我们要建立的是特征和标签的关系,从而实现预测。Logistic回归是通过最优化算法求出特征和标签之间最佳的拟合关系,我们所求出的拟合参数可以看成各个特征的权,各个特征加权求和然后带入Sigmoid函数中,对于结果大于0.5的取1,小于0.5的取0,为什么要利用Sigmoid函数(后面称为S函数),这要从Sigmoid函数的特性说起,如下图所示:

从图上可以看出,在区分边界(0.0.5)可以当x变化很小时,Sigmoid函数值变化很大,这样更加有利于区分。
在最优化算法中,我们时常听过牛顿法、梯度下降法、梯度上升法,这里梯度下降法和梯度上升法的区别是一个试求极小值一个是求极大值,下面先从牛顿法的说起,学过计算方法的同学应该知道牛顿法,,对于x当其为n维向量时即是我们常用的迭代求每次未知数的改正值,而对于梯度下降法,将函数的倒数看成一个常数,即成为梯度下降法,将减好号改为加号即为梯度上升法。下面我们来看看Sigmoid中利用到梯度上升法的python源代码,并仔细分析。
def gradAscent(dataMatIn, classLabels):
dataMatrix =np.mat(dataMatIn) #convert to NumPy matrix
labelMat = np.mat(classLabels).transpose() #convert to NumPy matrix
m,n = np.shape(dataMatrix)
alpha = 0.001
maxCycles = 500
weights = np.ones((n,1))
for k in range(maxCycles): #heavy on matrix operations
h = sigmoid(dataMatrix*weights) #matrix mult
error = (labelMat - h) #vector subtraction
weights = weights + alpha * dataMatrix.transpose()* error #matrix mult
weights1= np.ones(n)
for i in range(n):
weights1[i]=weights[i,0]
return weights1 首先dataMatrix是特征数据,而labelMat是特征数据的标签,最为核心的代码为:
weights = weights + alpha * dataMatrix.transpose()* error #matrix mult 下面来讲讲为什么是这样的,我们将dataMatrix看成一个矩阵A(m*n),即m行n列,即常说的系数矩阵,未知数weights为 x,标签labelMat为l ,即观察值(这里需要测绘学的一些知识),那么结果就成了A*x=l,求x,首先法化得到AT*A*x=AT*l(AT代表A的转置,根据前面讲解的梯度上升法的知识,这每次的改正数为 alpha*(AT*A*x0-AT*l),即为alpha*AT*(A*x0-l)(x0为初始值),这样就是上面的公式,当考虑Sigmoid函数时,将A*x0-l带入Sigmoid函数作为残差error。
下面再给出一个例子来看Logistic回归分类算法的结果,还是最初给出的三列数据,以此作为样本来得到不同类型数据的分类线,如图所示:
到此已经讲完,我们重点讲解了最优化算法即梯度上升算法的原理,同时分析编写代码的原理,同时粗略讲解了logistic回归分类,最后给出了一
个分类边界图,希望对读者有帮助(在这里说明本文中例子来自于对一本书的理解,但也加上了和改进以及自己的看法)