针孔相机模型
针孔相机成像模型
针孔相机(pinhole camera )实物模型如下所示:
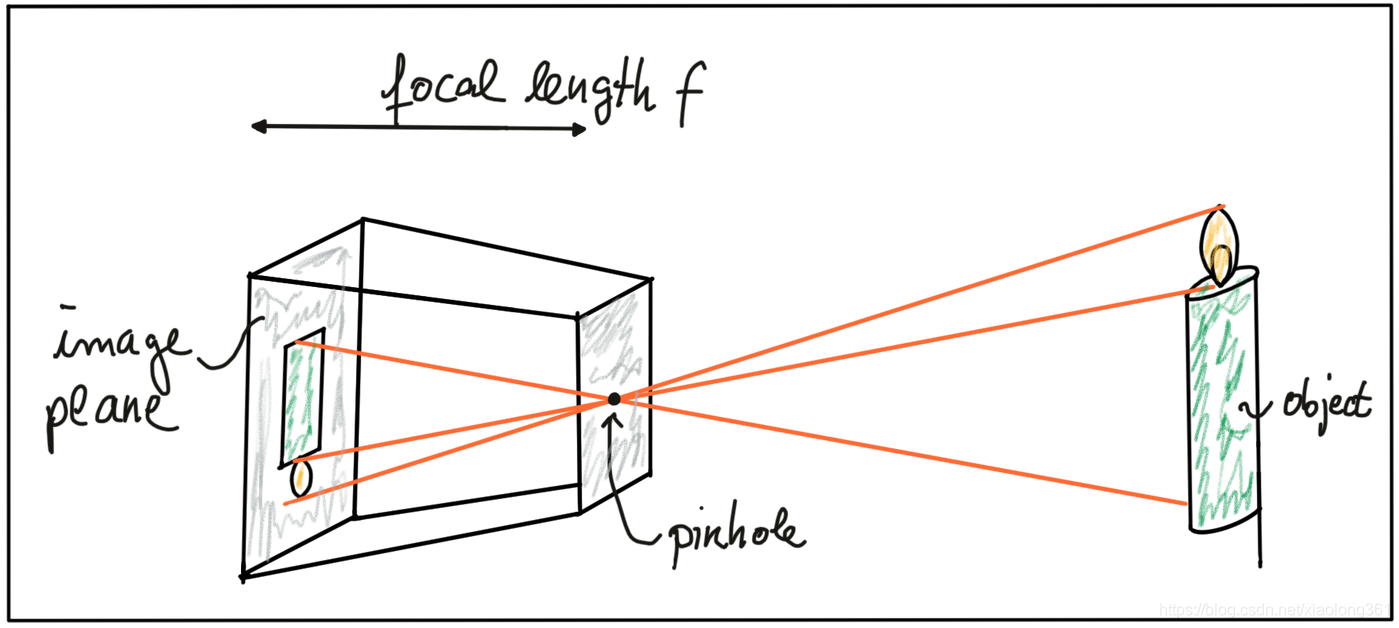
左边的感光表面称为像平面,而针孔(pinhole)称为相机中心。相机中心与像平面之间的距离称为焦距f。
三维世界中的目标物体上的点
利用经过相机中心的光线投射可以映射到像平面上的点
,如下图所示。

其中,映射关系可以用下列公式表示:
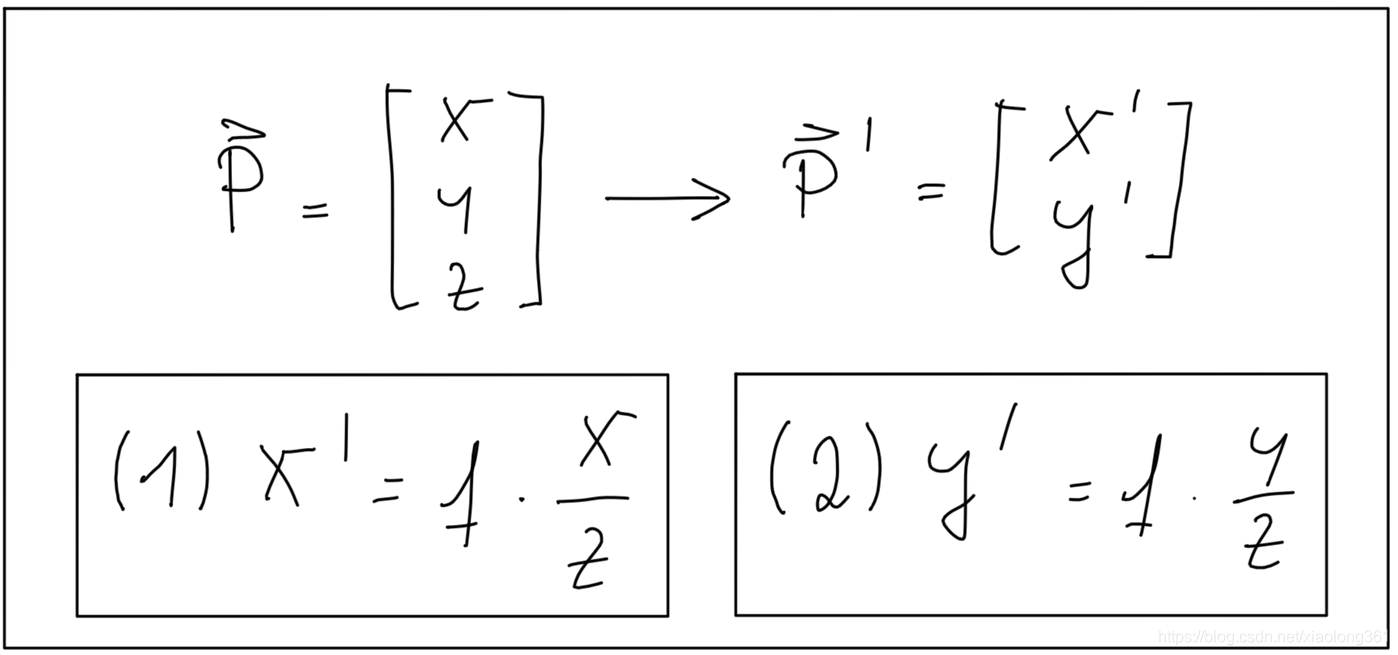
利用这些方程,我们可以根据实际物体在空间中的三维位置以及相机的焦距,计算出实际物体在成像平面上的二维位置。但是,请注意得到的坐标
和
还只是“测量坐标”,而不是真正的像素位置。
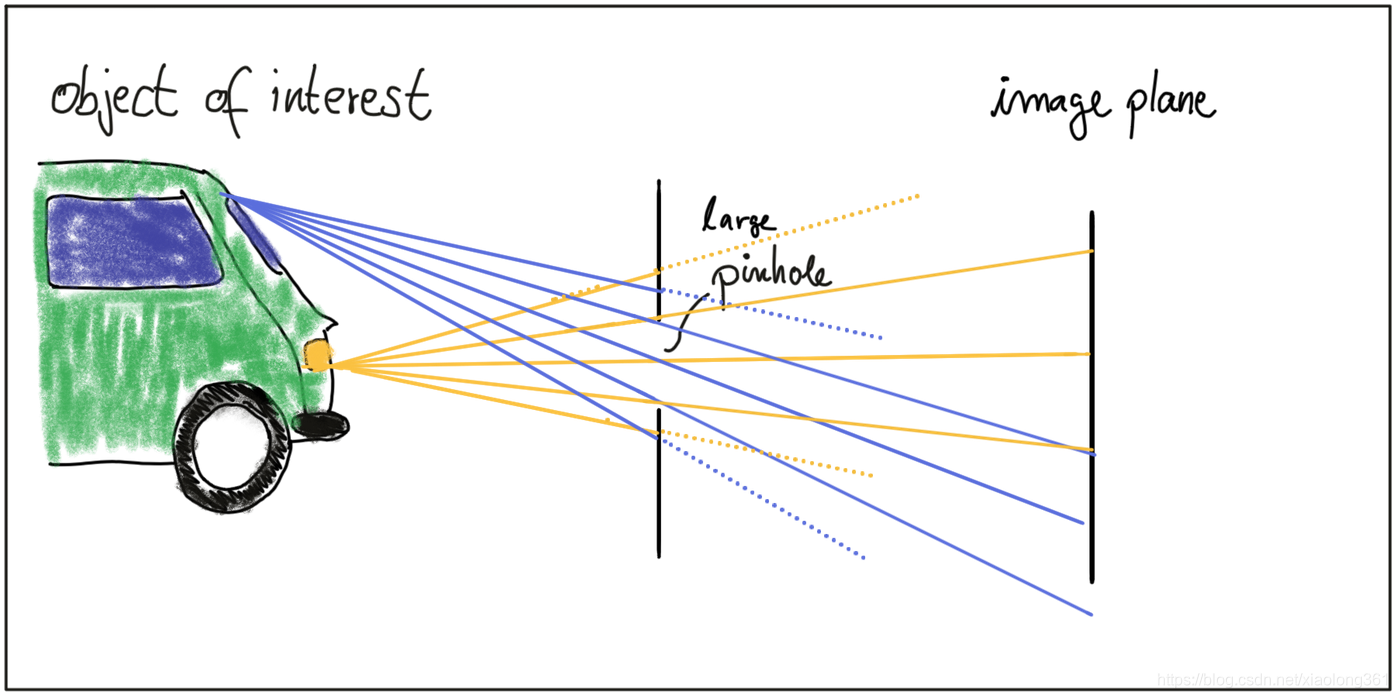
针孔相机存在的一个问题是,通过针孔的光线不足以在感光传感器上生成图像。如果要增加光线可以简单通过扩大针孔实现,如下图所示。但这样会使目标对象反射的光线与其他部分反射的光线互相重叠,从而导致成像效果模糊:即针孔开的越大,图像越明亮,但与此同时,成像平面上的对象模糊越严重。
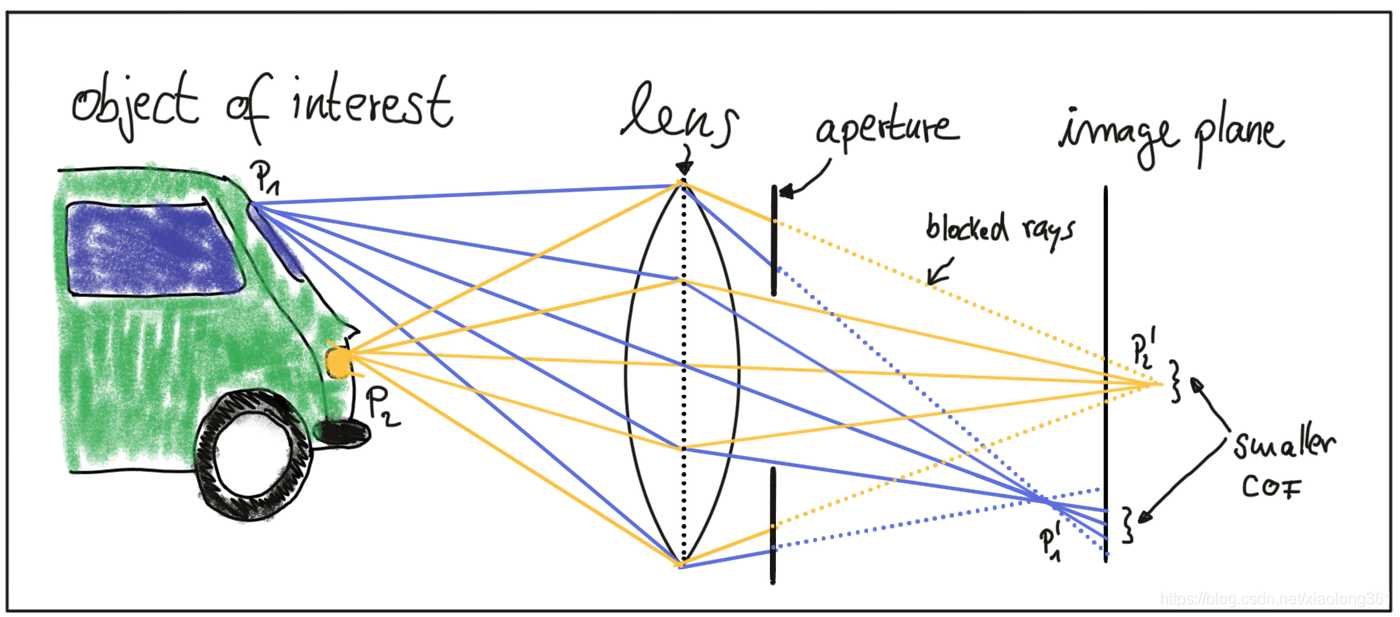
 解决这个问题的一种方法是使用镜头,它能够捕捉到目标物体同一点发出的多条光线。接下来我们来看镜头和光圈。
解决这个问题的一种方法是使用镜头,它能够捕捉到目标物体同一点发出的多条光线。接下来我们来看镜头和光圈。
镜头和光圈
一个适当大小和位置的镜头(透镜)可以将目标物体上点 发出的所有光线折射到像平面上的一个点 上。然而,穿过透镜中心的光线不发生折射,它们以直线继续前进,直到与成像平面相交。
物体上其他距离更近或更远的点,如
,在像平面上出现焦点不集中的现象,因为从它们发出的一组光线无法通过透镜汇聚在一个点上,而是汇聚在一个特定半径的圆上。这个模糊的圆通常被称为circle of confusion (COF)。为了减少模糊,可以使用一个光圈,它是一个和透镜同中心的开口,通常大小可调,直接放在镜头后面。下图说明了原理:
枕形畸变和桶形畸变
通过减小光圈的直径,经过透镜外边缘的光线被阻挡,从而减小了成像平面上COF的大小。显然,较小的光圈可以减少模糊,但代价是降低了光线敏度度。光圈越大,则更多的光线会被汇聚到成像区域,产生信噪比更好的更明亮的图像,缺点就是可能增大图像模糊程度。
那么,我们如何计算空间中的物体在图像中的位置呢?给定空间中的一个三维点,其通过透镜后在成像平面上的二维位置可以类似针孔相机的方式进行计算。实际上,镜头会由于镜头类型的不同而导致图像失真。最接近实际情况的畸变我们称为“径向畸变”。这是由于透镜的焦距在其直径上不均匀造成的。因此,镜头的放大效果取决于相机中心(光轴)与通过镜头的光线之间的距离。如果放大倍数增大,所产生的畸变效应称为“枕形畸变(Pincushion Distortion)”;若放大倍数减少,则它被称为“桶形畸变(Barrel Distortion)”。当使用广角镜头时,通常就会发生桶形畸变。在下面的图中,说明了这两种畸变类型。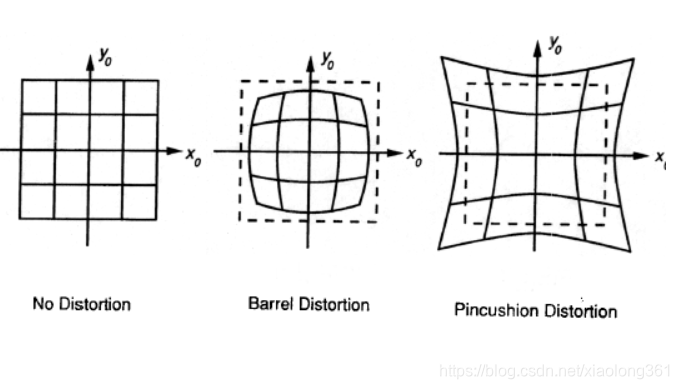
图像标定和校准概念
当从相机图像中提取信息时,许多应用程序需要从图像中获取目标对象(例如车辆)的空间位置。为了达到这个目的,必须去除或至少减轻镜头的畸变效应。该过程被称之为标定(Calibration)。对于每个相机镜头配置,必须执行一个标定程序,以便可以计算出畸变参数。这通常是通过拍摄一组已知的物体照片来实现的,比如平面棋盘图案。从这些已知的几何图形中可以推导出所有的镜头和图像传感器参数。从摄像头图像中消除畸变的过程称为校准(Rectification)。下图显示了本课程中进行图像校正的标定装置。可以很容易地看到,左右两边的直线都出现了严重的畸变。
 然而,关于畸变校正的细节,我们不再这里进行深入讨论。然而,当使用自己的相机设置时,如果以精确测量或对象的空间重建为目标,那么必须执行校准过程。
然而,关于畸变校正的细节,我们不再这里进行深入讨论。然而,当使用自己的相机设置时,如果以精确测量或对象的空间重建为目标,那么必须执行校准过程。
三维坐标系到像素坐标系的转换
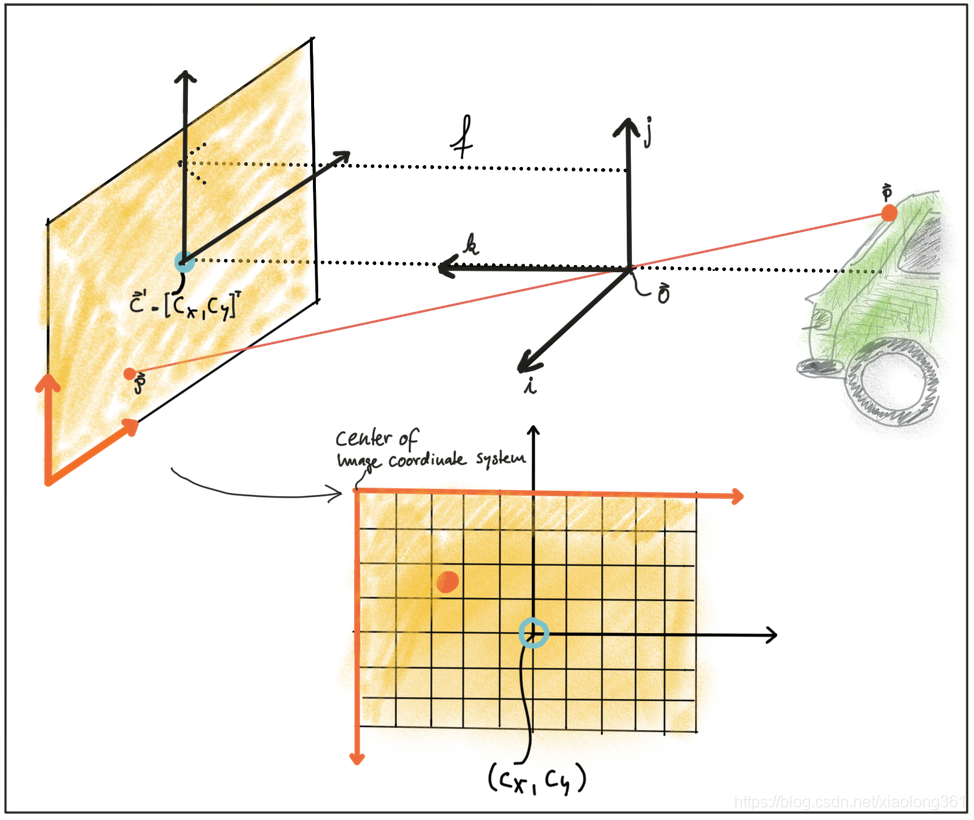
如前所述,在三维空间中,点在像平面上的投影与我们在实际数字图像中所看到的并不直接对应,而实际数字图像是由成千上万的像素(pixel)组成。为了理解图像是如何以离散像素来表达的,我们需要再次仔细观察上述相机模型。如下图所示,摄像头中心在空间中点 的位置,并且有自己的坐标系,其坐标轴分别为 、 、 ,其中 轴指向成像平面的方向。 轴与成像平面相交的位置点 ,点 称为主点(Principal Point),表示图像坐标系的中心。
将空间中的点
映射到像平面后的第一步是减去主点坐标,这样离散图像就拥有了以成像平面左下角为中心的自己的坐标系统,如下图所示。
转换过程的第二步是从测量坐标系转换到像素坐标系。我们可以使用标定过程提供的参数
和
实现从测量值到像素的转换,并且这些参数也很容易被整合到如下图所示的映射公式中。注意:在图像坐标系中,其坐标原点位于左上角,且
轴正方向指向正下方,
轴正方向指向正右方。
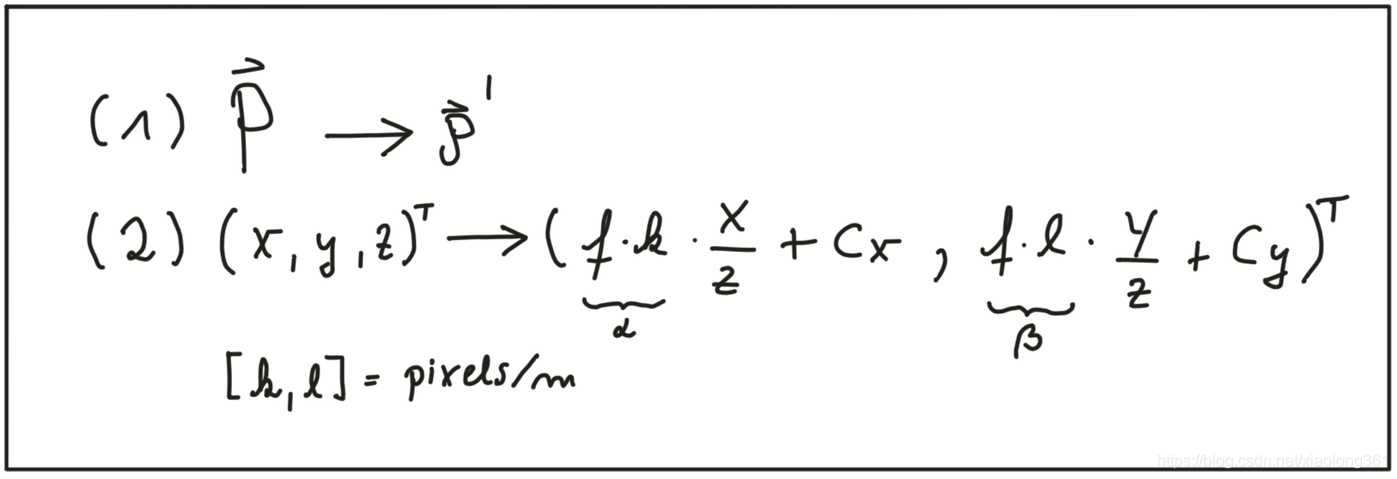 在后面的章节,我们将把激光雷达3D点云映射到摄像头图像中。我们将利用上述公式实现这一目标。另外,焦距
和
和
的乘积(也分别称之为
和
)将在一个校准矩阵中被使用,从而极大地简化了映射操作。
在后面的章节,我们将把激光雷达3D点云映射到摄像头图像中。我们将利用上述公式实现这一目标。另外,焦距
和
和
的乘积(也分别称之为
和
)将在一个校准矩阵中被使用,从而极大地简化了映射操作。
图像校准中还有最后一点需要注意的是:在许多应用中(如特征跟踪),处理原始图像是有意义的,因为这样可以避免在校准图像以及校准图像后像素转换没有完全落入离散像素的中心等过程造成的计算误差。在这种情况下,建议在未修改的原始图像中定位特征,然后使用上面的方程对得到的结果进行坐标转换。当使用基于一组训练权重的深度学习时,在将图像导入网络之前进行图像校准是很有意义的——如果我们使用原始图像,畸变(例如,由于使用鱼眼镜头造成)将会导致检测错误,因为这些网络通常是利用无畸变的图像进行训练生成的。
图像传感器和拜耳阵列(Bayer Pattern)
在本节中,你将了解具有特定波长的光线是如何转换成可以进行数字存储的彩色像素的。
当照相机捕捉到图像时,光线会穿过镜头并落在图像传感器上。这种传感器由光敏元件组成,它们记录照在它们身上的光的数量,并将其转换成相应数量的电子。光线越强,产生的电子越多。当曝光时间完成后,生成的电子被转换成电压,最后通过数模(A/D)转换器转换成离散的数字量。
目前,有两种主流的图像技术——CCD(电荷耦合器件)和CMOS(互补金属氧化物半导体)。这两种技术都是将电子转换成电压,并且天生是色盲的,因为它们无法区分产生电子的不同波长。为了能够显示出色彩,在每个像素前会放置微小的滤光装置(也称为微透镜),这些滤光装置只允许特定波长的光线通过。将波长映射到颜色的一种常见方法是将滤镜装置排列成RGB(红、绿、蓝)阵列,从而只允许三种原色(红、绿、蓝)单独通过,这样就可以得到三幅单独的图像——每幅图像对应一种原色。
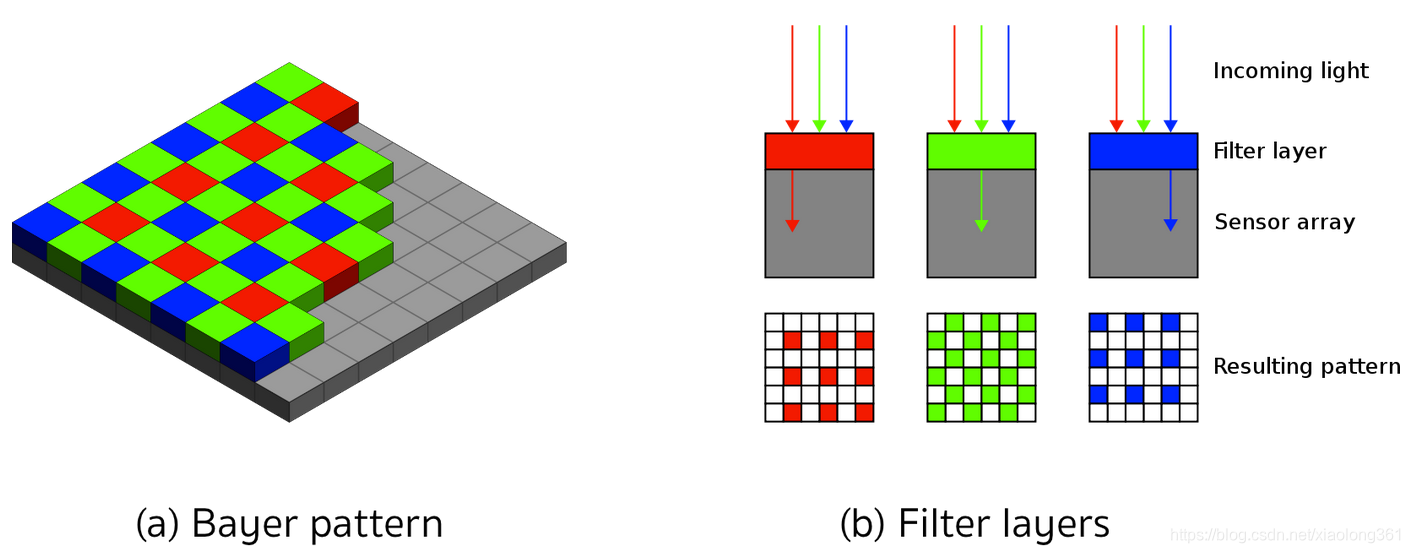
通过各种不同的组合,RGB值可以产生人眼可见的绝大多数颜色。当每个离散的颜色值被编码为8位(即256个值)时,利用“RGB滤光器”原理总共可以创造出1670万种不同的颜色。其中,最常见的排列“RGB滤光器”的方法是拜耳阵列(Bayer Pattern),它具有红绿交替和蓝绿交替两种滤光器组合。由于人眼对绿色比对红色或蓝色更敏感,拜耳阵列的绿色滤光器数量是红色滤光器或蓝色滤光器的两倍。在计算机视觉应用程序中,当处理彩色图像时,RGB三个图层都是可以使用的。如果处理能力有限,则可将不同的通道组合成灰度图像。值得一提的是,我们可以利用OpenCV计算机视觉库中的cvtColor方法实现RGB图像到灰度图像的转换,具体的转换原理和使用说明,可以参考OpenCV官方文档:https://docs.opencv.org/3.1.0/de/d25/imgproc_color_conversions.html
CCD vs. CMOS
在CCD传感器中,每个图像元件中收集到的电子通过一个或几个输出节点从芯片中传输出来。然后,电荷被转换成电压电平,经过缓冲后作为模拟信号发送出去。随后该信号会被传感器外的信号放大器放大,并利用传感器外的A/D转换器将将放大后的信号转换为离散数字量。最初,CCD技术与CMOS相比有很多优点,比如更高的光敏性和更低的噪声。然而,近年来,这些差异几乎消失了。CCD的主要缺点是生产成本高,功耗高(比CMOS大约高100倍),这通常会导致相机发热问题。
CMOS传感器最初用于机器视觉应用,但由于其较差的光灵敏度,导致图像质量较差。然而,随着现代CMOS传感器的发展,其成像质量和光敏性都有了显著提高。CMOS技术具有以下几个优点:不同于CCD,CMOS芯片集成了放大器和A/D转换器,这带来了巨大的成本优势。对于CCD,这些元器件均位于传感器芯片的外部。CMOS传感器还具有更快的数据读出速度、更低的功耗、更高的抗噪能力和更小的系统尺寸。在汽车应用中,由于这些优点,几乎所有的相机都使用CMOS传感器。本课程中使用的大部分图像序列的相机设置可以在这里找到: http://www.cvlibs.net/datasets/kitti/setup.php
