点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
今天自动驾驶之心很荣幸邀请到寒风分享RV后融合算法CenterFusion,如果您有相关工作需要分享,请在文末联系我们!
>>点击进入→自动驾驶之心【多传感器融合】技术交流群
后台回复【多传感器融合综述】获取图像/激光雷达/毫米波雷达融合综述等干货资料!
前言
本文主要介绍一种基于毫米波雷达和相机后融合的3D目标检测算法——CenterFusion,原本是公司内部的一个技术方案,截取了其中的核心理论部分,所以看起来肯能有些严肃。
毫米波雷达与视觉的融合
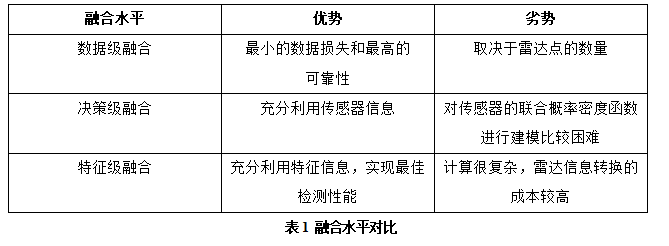
一般来说,毫米波雷达和视觉有三个融合级别,包括数据级、决策级和特征级。数据级融合是对毫米波雷达和摄像机检测到的数据的融合,它的数据损失最小,可靠性最高。决策级融合是对毫米波雷达和摄像机的探测结果的融合。特征级融合需要提取雷达特征信息,然后与图像特征融合。表1提供了三种融合水平的比较。
数据
数据方面, 3D场景下的多传感器目标检测,涉及到空间信息的处理还有不同传感器数据的结合,所以数据的维度更多,结构也相对复杂。方案中以nuScenes数据集为例,对模型进行可行性验证和预训练。整个方案的流程中,针对不同的场景和计算需要,共建立了5个不同的坐标系,不同坐标系间的映射关系由现场标定进行获取,nuSences数据集中提供了完备的标定信息供计算使用。
数据坐标系
方案中共包含5个坐标系,分别是全局坐标系(global)、车身坐标系(ego)、雷达坐标系(radar)、相机坐标系(cam)和像素坐标系(image)。其中,像素坐标系为常见的左上角点二维坐标系,像素坐标系和相机坐标系的转换关系由相机内参确定。其他四个坐标系均为三维坐标系,坐标系间的转换关系由现场标定确认。一共需要三个变换矩阵,分别是:
雷达外参:雷达坐标系到车身坐标系的变换矩阵
相机外参:相机坐标系到车身坐标系的变换矩阵
扫描二维码关注公众号,回复: 17249695 查看本文章
车身姿态:车身姿态包括当前时刻车辆在全局坐标系中的位置和偏转信息两部分
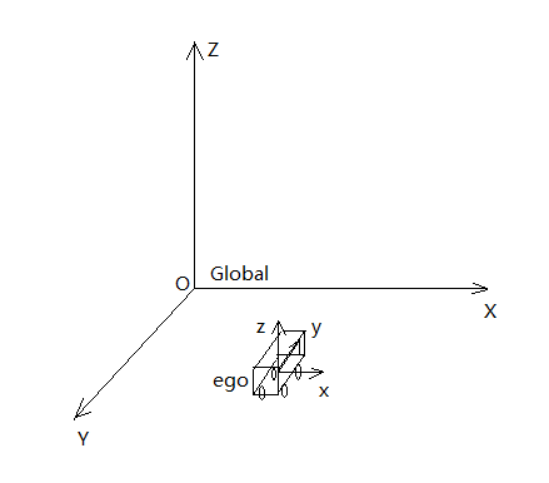
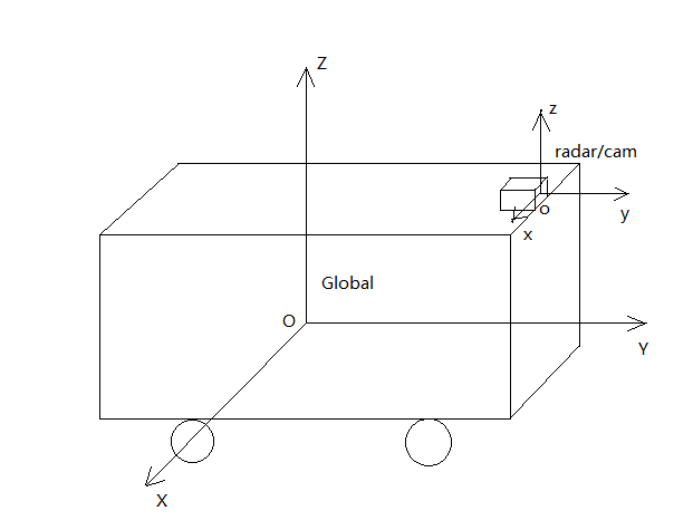
雷达和相机的坐标系虽然都是三维坐标系,但是雷达数据并没有z轴坐标,为了在投影时对齐维度,均设置为0值。
另外雷达或相机坐标系并不是与车身坐标系平行的,示意图中只是画出了相对关系,具体参数需要由现场标定确认。
数据投影
在3D框坐标计算、多传感器数据融合等步骤中,需要将数据投影到特定的坐标系中,而其中的基础步骤是相对固定的。比如将雷达数据投影到像素坐标系中,就用到了所有的基础步骤,因此以雷达数据投影为例。
雷达数据投影到像素坐标系中,一共需要五次投影变换,流程如下图所示:

这里之所以要将雷达数据投影到全局坐标系之后再投影到车身坐标系,是因为雷达和相机的采样时间存在一定的时间错位极为Δt,在Δt内车辆行驶了一定的距离,所以要根据车身的位置变化计入位移补偿,避免最终投影结果的错位。
网络结构
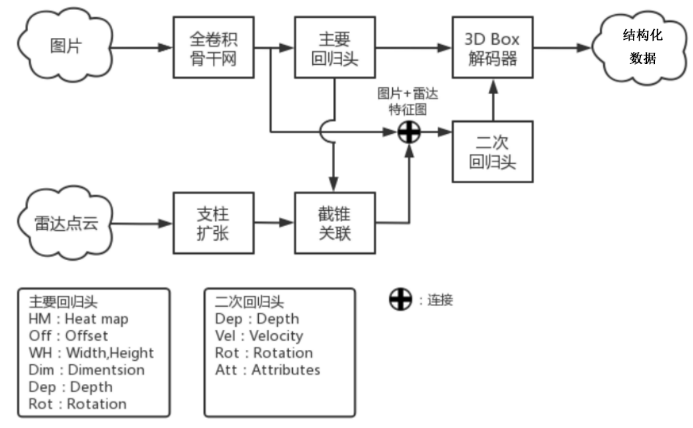
CenterFuion模型由CenterNet网络改进而来,整体逻辑类似,在数据维度上进行了3D场景的适应性扩展。输入由原来的只有图像输入,扩展到了图像、雷达、转换矩阵和景深信息等维度,输出方面扩展出了空间坐标、箱体尺寸、航向和姿态等信息。整体处理流程如图1所示:
模型输入
模型输入共包括三个部分:
相机数据和雷达数据:
数据格式见表1
图1展示的为毫米波雷达的点云俯视图,因为毫米波雷达的结构化数据只具有x,y坐标,故选择俯视展示。
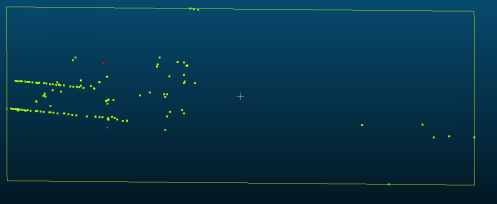
将雷达点位与相机数据进行叠加后,效果如下图。

最后进行张量化处理,对雷达数据和相机数据进行“cat”型叠加,并调整维度到[448,800,3],最后进行通道调整得到参数Images。
场景深度:
雷达数据在投影过程中,只保留了X轴和Z轴坐标(侧面相机保留的是Y轴和Z轴,此处以车前端相机为例),Y轴坐标即景深信息无法在图像上体现,因此作为一个单独的参数输入模型。数据格式见表2:

四元数矩阵
四元数矩阵是从图片坐标系直接映射到全局坐标系的投影矩阵,由相机内参矩阵、相机外参矩阵和当前时刻车身姿态矩阵组成。在模型的中间步骤需要将由2D影像检测出的中心点坐标与3D场景的景深结合,确定目标中心点的空间坐标,这时就要用的四元数矩阵来对2D检测内容进行投影变换。数据格式见表3:

图像特征提取
图像特征提取分为全卷积骨干网和主要回归头两部分。
(1)全卷积骨干网
CenterFusion 网络架构在对图像进行初步检测时,采用 CenterNet 网络中修改版本的骨干网络 DLA(深层聚合)作为全卷积骨干网,来提取图像特征,因为 DLA 网络大大减少了培训时间,同时提供了合理的性能。DLA网络架构如图1所示:

全卷积骨干网络以图象作为输入,生成预测关键点热图,其中 W 和 H是图像的宽度和高度,R是下采样比,C 是物体类别的数量。意思是将一张 W × H的图片作为输入,然后通过下采样(池化)生成的关键点热图,图中的每一个像素的热值在[0,1]之间。再通过回归图像特征的方法来实现对图像上目标中心点的预测,以及对目标的 2D 大小(宽度和高度)、中心偏移量、3D 尺寸、深度和旋转等信息的提取。
(2)主要回归头
主动回归头包括六个分支(如图2),分别输出中心点热力图、中心点偏移量、2D宽高、3D长度、距离和旋转角度,其中的中心点热力图、中心点偏移量、2D宽高、3D维度就是最终输出,不会再次预测。
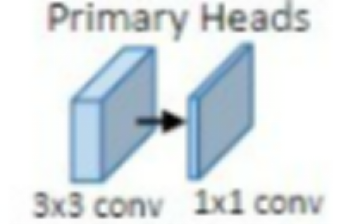
这为场景中每个被检测到的对象提供了一个精确的 2D 边界框以及一个初步的 3D 边界框。
雷达数据与目标图像的关联
要实现雷达数据与相机数据的融合,首先要将雷达的检测点与其对应的物体在图像平面进行匹配。一种比较简单直接的方法是将图像平面上落在一个2D bunding box里的雷达检测点与这个目标进行关联,但这种方法的可靠性很低,原因包括以下三点:
雷达检测点和目标不是一一对应的,场景中有的目标会产生多个雷达检测点,也有的雷达检测点匹配不到任何目标。
毫米波雷达的检测点的z轴信息准确性很差或者根本没有,在投影过程中可能无法精准投影到图像平面上的对应的bunding box内。
同样是因为z轴信息的不稳定,如果目标被遮挡,则前后两个目标的监测点很容易在图像平面上落在同一区域内,造成错误匹配。
因此需要引入截锥关联和支柱扩张模块,来更好的进行检测点和目标框的匹配。
(1)截锥关联
以图1 所示的车辆为例,此时我们通过3.2.2节中介绍的全卷积骨干网络和主要回归头获得了车辆目标的一系列预测信息,这里要用到物体的2D检测框、深度估计还有3D bunding box。如图2和图3所示,依据这些信息生成物体的3D ROI区域。其中的在训练阶段用的是物体中心点的真实深度值,在测试阶段则使用图像分支生成的预测值。δ是一个超参数,用来控制ROI区域的大小,以此来控制落入ROI区域的雷达点的数量。对于落入ROI区域的雷达检测点,仍需要进行筛选,方案中选取的是深度最小,即最靠前的检测点作为匹配结果。


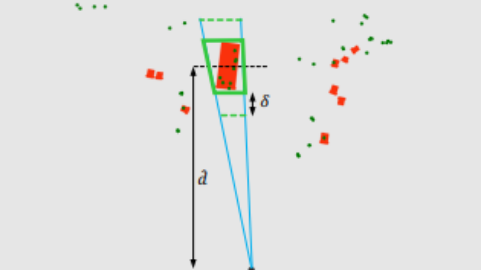
在此基础上,为了解决z轴信息缺失的影响,需要再引入支柱扩张模块。如图4.1(上图)所示,将雷达检测点扩张为一个3D立方体。若雷达检测点对应的3D立方体,全部或者有部分落到了某个目标的ROI区域内,就判定雷达检测点和物体匹配,如图4.2(中图)。当一个目标匹配到多个雷达检测点时,选取景深最小,即最靠前的雷达检测点作为目标的唯一匹配点,以匹配的雷达检测点的深度绘制截锥平面(图2中的a平面)如图4.3(下图)

雷达数据处理
完成雷达检测点和目标的关联之后,就要对雷达数据的特征进行处理,转换为张量形式,与全卷积骨干神经网络的输出进行叠加。
对于每一个与物体相关的雷达检测点,生成一个三通道的热图区域,热图区域的中心点与检测框的中心点重合,并包含在检测框内部,热图区域的宽度和高度与物体的 2D 边界框成比例,并由参数 α控制。

热图的三个通道值分别是归一化后的目标深度(d)、目标径向速度的x轴分量()和目标径向速度的y轴分量()。这里的x轴和y轴取自车身坐标系(ego)。
热图值公式如公式1所示:
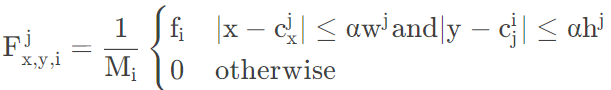
其中,F是当前像素归一化后的值,i1,2,3代表热图的通道编号,x和y代表当前像素的像素坐标,是热图的归一化因子,是当前像素的像素值(按通道分别取d,或),和是目标j的中心点的x和y坐标,和是目标j的2D边界框的宽度和高度。
最终生成的热力图会以“cat”方式作为扩充通道叠加到全卷积骨干神经网络输出的特征图上,作为融合特征输入到二次回归头中计算物体的深度、姿态、速度还有属性。
二次回归头由四个分支构成,分别预测物体的深度、旋转角、速度还有属性。这里的属性包括车辆的静止、行驶还有行人的站立、静坐等。

3DBOX解码器
3D BOX解码器汇总了主要回归头和二次回归头输出的预测信息,并据此进行3D框体信息的解码。归纳的信息包括:
检测框的宽高
检测框中心点的2D坐标
检测框中心点的深度
检测框的长度
目标航向
目标类别
目标速度
目标状态(静止、行驶)
通过目标的尺寸信息,可计算出3D框体角点关于目标中心的相对坐标。进而通过中心点坐标和航向信息计算出3D框体角点的全局坐标。
最终将框体角点的全局坐标纳入到结构化数据中返回,如果需要绘制可视化结果,通过之前介绍的坐标系投影关系,可将角点投影到图像平面进行绘制。


【自动驾驶之心】全栈技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦目标检测、语义分割、全景分割、实例分割、关键点检测、车道线、目标跟踪、3D目标检测、BEV感知、多传感器融合、SLAM、光流估计、深度估计、轨迹预测、高精地图、NeRF、规划控制、模型部署落地、自动驾驶仿真测试、硬件配置、AI求职交流等方向;

添加汽车人助理微信邀请入群
备注:学校/公司+方向+昵称