问题:时间的依赖变量通过光流建立,空间的依赖由于空间限制表达能力,无法建模复杂依赖,一些高阶概率结合学习模式或强化预分割区域中标签一致性
使用CNN进行高阶空间可能性编码,可以基于CNN定义目标函数来评估给定的掩码整体。每帧像素空间potential可以使用基于CNNDA方法进行定义,更复杂的依赖也可以通过这种方式进行定义,因此MRF模型将强制每帧中的推断结果更像特定的对象。
对MRF以及相关定义的说明
马尔科夫核心:当前节点只与和它相连的有关,而与其他无关,具有条件独立性求取联合概率分布
团块:团块中节点集合是全连接的,每对节点间都存在连接
因子:定义为团块中变量的函数
重新回到文章,在一整个视频序列中定义随机场X,每帧中每个像素都是一个变量,值在{0,1}之间(二值分类),用x表示X中变量可能的label。场中的团用C定义,团中变量集用xc表示。
随机场最大后验概率时,x的标签

表示受图片数据限制时,各团能量总和最小时x应取什么label
通过最小能量函数实现最大后验概率
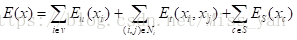

一元能量函数,表示每个像素点取当前label 的概率的对数值。
Et使用forward-backward consistency check进行过滤。
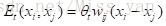
用两帧之间对应的标签(像素)作差,Wij用于表示时空连接可信度,该能量函数用于保证时空一致性。
空间:一帧中所有像素作为一个团,也即一帧中的某个像素的label与当前帧中其余所有像素都有关。
计算一帧图像的能量函数f(·),评价一整个mask的质量,如直接用当前mask与真值mask直接作差,但实际上真值也是不知道的。空间能量函数定义如下
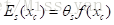
基于CNN能量函数的MRF推断比较困难
公式太多我就直接放图了
