1 回归模型
回归算法模型用来预测连续数值型,其目标不是分类值而是数字。为了评估这些回归预测值是否与实际目标相符,我们需要度量两者间的距离,打印训练过程中的损失,最终评估模型损失。
这里使用的例子是从均值为1、标准差为0.1的正态分布中抽样随机数,然后乘以变量A,损失函数为L2正则损失函数。理论上,A的最优值是10,因为生成的样例数据均值是1。回归算法模型拟合常数乘法,目标值是10。
1.1 实现模型
# TensorFlow实现、训练并评估回归模型
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
# 1.创建计算图、数据集、变量和占位符。
# 创建完数据后,将它们随机分割成训练数据集和测试数据集。
# 不管算法模型预测的如何,我们都需要测试算法模型,这点相当重要。
# 在训练数据和测试数据上都进行模型评估,以搞清楚模型是否过拟合:
sess = tf.Session()
x_vals = np.random.normal(1, 0.1, 100)
y_vals = np.repeat(10., 100)
x_data = tf.placeholder(shape=[None, 1], dtype=tf.float32)
y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32)
batch_size = 25
train_indices = np.random.choice(len(x_vals),
round(len(x_vals) * 0.8),
replace=False)
test_indices = np.array(list(set(range(len(x_vals))) -
set(train_indices)))
x_vals_train = x_vals[train_indices]
x_vals_test = x_vals[test_indices]
y_vals_train = y_vals[train_indices]
y_vals_test = y_vals[test_indices]
A = tf.Variable(tf.random_normal(shape=[1, 1]))
# 2.声明算法模型、损失函数和优化器算法。初始化模型变量A
my_output = tf.matmul(x_data, A)
loss = tf.reduce_mean(tf.square(my_output - y_target))
init = tf.global_variables_initializer()
sess.run(init)
my_opt = tf.train.GradientDescentOptimizer(0.02)
train_step = my_opt.minimize(loss)
1.2 训练模型
# 3.迭代训练模型
for i in range(100):
rand_index = np.random.choice(len(x_vals_train),size=batch_size)
rand_x = np.transpose([x_vals_train[rand_index]])
rand_y = np.transpose([y_vals_train[rand_index]])
sess.run(train_step,feed_dict={x_data: rand_x, y_target: rand_y})
if (i + 1) % 25 == 0:
print('Step # ' + str(i+1) + ' A = ' + str(sess.run(A)))
print('Loss = ' + str(sess.run(loss, feed_dict={x_data: rand_x, y_target: rand_y})))
1.3 评估模型
mse_test = sess.run(loss, feed_dict={x_data: np.transpose([x_vals_test]),
y_target: np.transpose([y_vals_test])})
mse_train = sess.run(loss, feed_dict={x_data: np.transpose([x_vals_train]),
y_target: np.transpose([y_vals_train])})
print("MSE on test: " + str(np.round(mse_test, 4)))
print("MSE on train: " + str(np.round(mse_train, 4)))
//输出结果
Step # 25 A = [[6.699071]]
Loss = 12.127724
Step # 50 A = [[8.651022]]
Loss = 2.3122501
Step # 75 A = [[9.345232]]
Loss = 0.95689005
Step # 100 A = [[9.618834]]
Loss = 1.1624776
MSE on test: 1.2316
MSE on train: 0.9331
2 分类模型
分类算法模型基于数值型输入预测分类值,实际目标是1和0的序列。我们需要度量预测值与真实值之间的距离。分类算法模型的损失函数一般不容易解释模型好坏,所以通常情况是看下准确预测分类的结果的百分比。
这里的例子是一个简单的二值分类算法。从两个正态分布N(-1, 1)和N(3, 1)生成100个数。所有从正态分布N(-1, 1)生成的数据标为目标类0;从正态分布N(3, 1)生成的数据标为目标类1。模型算法通过sigmoid函数将这些生成的数据转换成目标类数据。换句话讲,模型算法是 ,其中,A是要拟合的变量,理论上 。假设,两个正态分布的均值分别是m1和m2,则达到A的取值时,它们通过 转换成到0等距的值。
2.1 实现模型
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
sess = tf.Session()
# 声明批大小
batch_size = 25
# 创建数据
x_vals = np.concatenate((np.random.normal(-1, 1, 50),
np.random.normal(2, 1, 50)))
y_vals = np.concatenate((np.repeat(0., 50), np.repeat(1., 50)))
x_data = tf.placeholder(shape=[1, None], dtype=tf.float32)
y_target = tf.placeholder(shape=[1, None], dtype=tf.float32)
# 将数据分为 训练集/测试集 = 0.8/0.2
train_indices = np.random.choice(len(x_vals), round(len(x_vals)*0.8), replace=False)
test_indices = list(set(range(len(x_vals))) - set(train_indices))
x_vals_train = x_vals[train_indices]
x_vals_test = x_vals[test_indices]
y_vals_train = y_vals[train_indices]
y_vals_test = y_vals[test_indices]
A = tf.Variable(tf.random_normal(mean=10, shape=[1]))
# 设置模型和损失函数,初始化变量并创建优化器
my_output = tf.add(x_data, A)
xentropy = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(
logits=my_output, labels=y_target))
my_opt = tf.train.GradientDescentOptimizer(0.05)
train_step = my_opt.minimize(xentropy)
init = tf.global_variables_initializer()
sess.run(init)
2.2 训练模型
for i in range(1000):
rand_index = np.random.choice(len(x_vals_train), size=batch_size)
rand_x = [x_vals_train[rand_index]]
rand_y = [y_vals_train[rand_index]]
sess.run(train_step, feed_dict={x_data: rand_x, y_target: rand_y})
if (i + 1) % 200 == 0:
print('Step # ' + str(i + 1) + ' A = ' + str(sess.run(A)))
print('Loss = ' + str(sess.run(xentropy, feed_dict={x_data: rand_x, y_target: rand_y})))
2.3 评估模型
# 评估模型
# 创建预测操作,用squeeze()使得预测值和目标值有相同的维度
# 用equal()函数检测是否相等,
# 把得到的true或false的boolean型张量转化成float32型
# 再对其取平均值,得到一个准确度值。
y_prediction = tf.squeeze(tf.round(tf.nn.sigmoid(tf.add(x_data, A))))
correct_prediction = tf.equal(y_prediction, y_target)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
acc_value_test = sess.run(accuracy, feed_dict={x_data: [x_vals_test], y_target: [y_vals_test]})
acc_value_train = sess.run(accuracy, feed_dict={x_data: [x_vals_train], y_target: [y_vals_train]})
print('训练集准确率:' + str(acc_value_train))
print('测试集准确率:' + str(acc_value_test))
# 训练集准确率:0.975
# 测试集准确率:0.9
2.4 可视化
A_result = sess.run(A)
bins = np.linspace(-5, 5, 50)
plt.hist(x_vals[0:50], bins, alpha=0.5, label='N(-1, 1)', color='green')
plt.hist(x_vals[50:100], bins[0:50], alpha=0.5, label='N(2, 1)', color='skyblue')
plt.plot((A_result, A_result), (0, 8), 'k--', linewidth=3, label = 'A = ' + str(np.round(A_result, 2)))
plt.legend(loc = 'upper right')
plt.show()
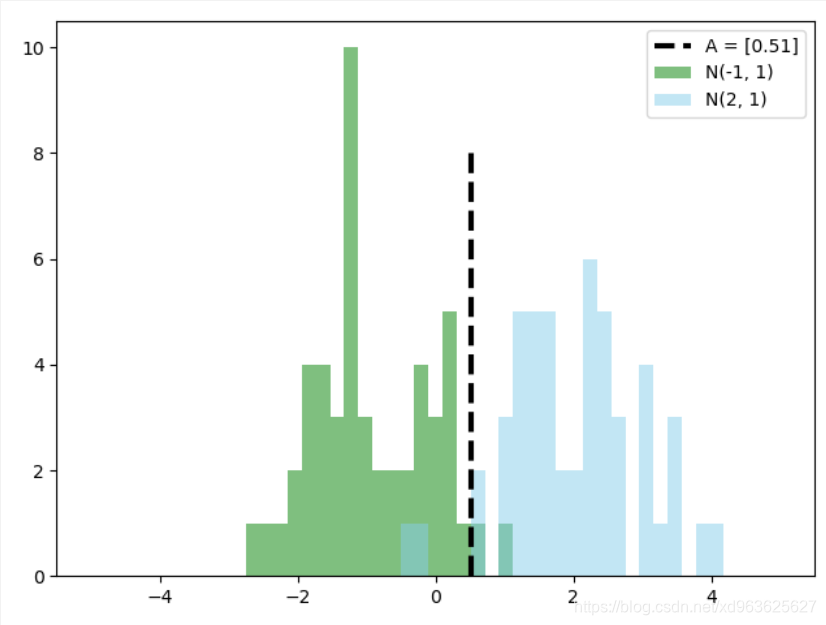
两个正态分布的均值分别是-1和2,理论上最佳分割点是
,可以看出,这里的模型结果为0.51非常接近理论值。
3 总结
从上述两个例子可以看出,模型评估是必不可少的,为了对模型进行评估需要先划分数据集,除了训练集和测试集外,有时还需要验证集。模型训练完成后可以得到准确率、MSE的结果,可以利用这些结果对机器学习模型进行评估。
