Tensorflow是深度学习常用的一个框架,从目前官方文档看,Tensorflow支持CNN、RNN和LSTM算法,这都是目前在Image,Speech和NLP领域最流行的深度神经网络模型。
为了熟悉和理解tensorflow,先从简单的例子开始,本文介绍用tensorflow搭建一个结构为[1,10,1]的神经网络实现简单线性回归。
过程如下:
- 生成随机样本点
- 定义变量和模型
- 通过梯度下降法减小损失函数,优化模型
- 作图
代码如下:
# coding=utf-8
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
#用numpy生成200个样本
x_data = np.linspace(-0.5,0.5,200)[:,np.newaxis] #把(1,200)转化为(200,1)方便后面的矩阵相乘运算
noise = np.random.normal(0,0.02,x_data.shape) #加入噪声数据,数据形状与x_data一样
y_data = np.square(x_data) + noise
#定义模型输入输出的占位符
x = tf.placeholder(tf.float32,[None,1])
y = tf.placeholder(tf.float32,[None,1])
#定义神经网络隐含层
Weights_L1 = tf.Variable(tf.random_normal([1,10]))
biases_L1 = tf.Variable(tf.zeros([1,10]))
L1 = tf.nn.tanh(tf.matmul(x,Weights_L1) + biases_L1)
#定义神经网络输出层
Weights_L2 = tf.Variable(tf.random_normal([10,1]))
biases_L2 = tf.Variable(tf.zeros([1,1]))
prediction = tf.nn.tanh(tf.matmul(L1,Weights_L2) + biases_L2)
#定义均方误差作为损失函数,使用梯度下降优化器减小损失函数
loss =tf.reduce_mean(tf.square(prediction-y))
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
#训练2000次
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) #初始化变量
for _ in range(2000):
sess.run(train_step,feed_dict={x:x_data,y:y_data})
#训练完之后,作预测
prediction_value = sess.run(prediction,feed_dict={x:x_data})
#作图
plt.figure()
plt.scatter(x_data,y_data)
plt.plot(x_data,prediction_value,'r-',lw=5)
plt.show()结果如下:
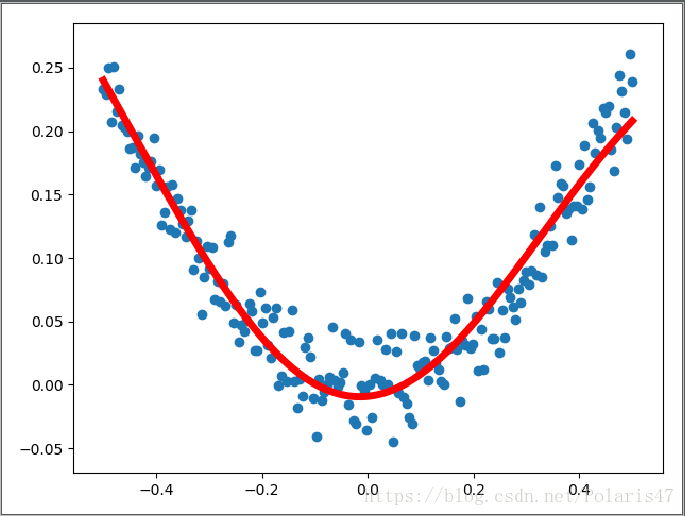
这样,整个过程就结束了。
在后续的文章中,会介绍用tensorflow实现更复杂的模型。