用原生python语法实现K近邻算法,了解K近邻法的实际操作内核,并用自带鸢尾花的集合验证K近邻算法,并掌握运用散点图的绘制
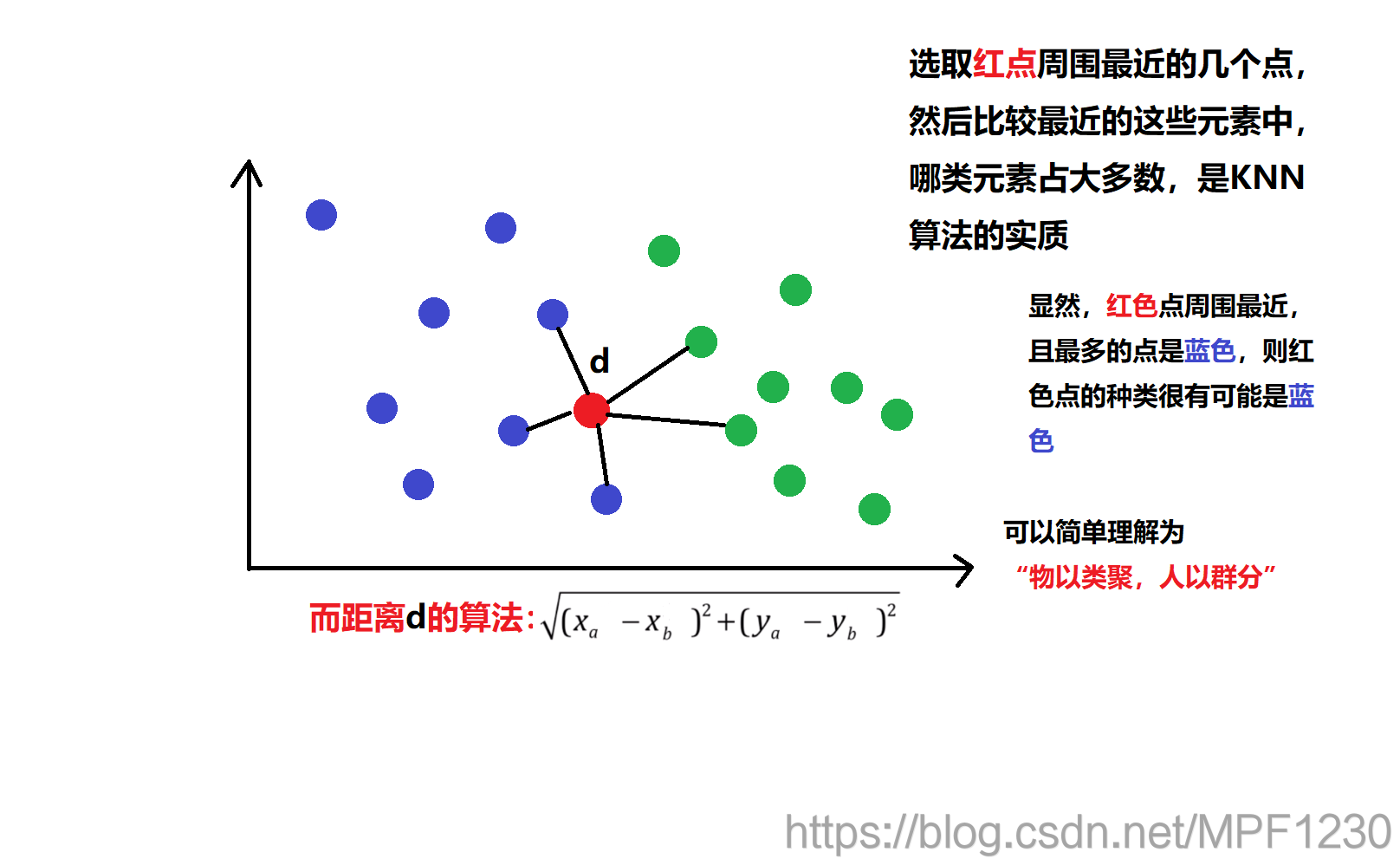
先对KNN算法做了解:
源代码获取:
https://github.com/akh5/Python/blob/master/My_KNN.ipynb
部分伪代码:
距离集合distyany2e对应的种类near_y集合
For 预测值 in near_y:
y0=0,y1=0,y2=0
预测结果=0
if 预测值 == 0:
y0+=1
elif 预测值 == 1:
y1+=1
else:
y2+=1
if y1>(y2 or y0):
预测结果 = 1
elif y2>( y1 or y0):
预测结果 = 2
else:
预测结果 = 0
结果集合
if 预测结果 == 训练集种类:
结果集合.append(1)
else:
结果集合.append(0)
此时结果集合中就只有0,1的元素了
若将 结果集合 中的各个元素相加,再处于集合长度就可以得到精确值
首先来从自带的包中获取鸢尾花的数据集
from sklearn.datasets import load_iris
import numpy as np
import matplotlib.pyplot as plt
iris_dataset = load_iris()
iris_dataset.keys()
dict_keys([‘data’, ‘target’, ‘target_names’, ‘DESCR’, ‘feature_names’, ‘filename’])
输出的是一个存放数据字典键值的list集合
iris_dataset['data'][:150]
array([[5.1, 3.5, 1.4, 0.2],
[4.9, 3. , 1.4, 0.2],
[4.7, 3.2, 1.3, 0.2],
[4.6, 3.1, 1.5, 0.2],
[5. , 3.6, 1.4, 0.2],
[5.4, 3.9, 1.7, 0.4],
[4.6, 3.4, 1.4, 0.3],
[5. , 3.4, 1.5, 0.2],
[4.4, 2.9, 1.4, 0.2],
[4.9, 3.1, 1.5, 0.1]])
数组中数据代表花萼长,花萼宽,花瓣长,花瓣宽
iris_dataset['target'][:150]
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
返回的是鸢尾花的种类0为setosa,1为versicolor,2为virginica
from sklearn.datasets import load_iris
import numpy as np
import matplotlib.pyplot as plt
import random
raw_x = iris_dataset['data'][:150] #
raw_y = iris_dataset['target'][:150]# 原生的鸢尾花数据集
X_train = np.array(raw_x) #将鸢尾花数据集添加到 numpy的数组中 作为训练集
Y_train = np.array(raw_y)
#这里为了方便只用了花萼的长,宽作为横纵坐标
plt.scatter(X_train[y_train==0,0],X_train[y_train==0,1],color='#FF00FF') #紫色点代表setosa
plt.scatter(X_train[y_train==1,0],X_train[y_train==1,1],color='#FFFF00') #黄色点代表versicolor
plt.scatter(X_train[y_train==2,0],X_train[y_train==2,1],color='#00FFFF') #青色代表virginica
X_test = iris_dataset['data'][random.randint(1,149)] #产生一个随机的鸢尾花数据作为测试数据
plt.scatter(X_test[0],X_test[1],color='#000000') #将测试数据用黑色添加在图标中
plt.ylabel('sepal width', fontsize=14)
plt.xlabel('sepal length', fontsize=14)
plt.show()
这里用data数组中的前两项,也就是花萼的长与宽来作为x_train训练集,然后给出种类给出y_train训练集
再从中随机选出一个值x_test作为测试集
描绘出的散点图如下?
三种亮色为三种y_train 黑色为测试集

#原生Python实现KNN过程
import math
distances=[]
#for循环找出测试数据与训练集每一个点的距离
for x_train in X_train:
d = math.sqrt(np.sum((x_train[0]-X_test[0])**2+(x_train[1]-X_test[1])**2))
distances.append(d)
distances
[1.4317821063276357,
1.6124515496597096,
1.7999999999999998,
1.902629759044045,
1.5524174696260025,
1.3038404810405293,
1.9104973174542803,
1.5132745950421556,
2.121320343559642,
1.6031219541881394,
这里给出的是黑点到其他各点的直线距离(未给全)
#原生Python实现KNN过程
import math
distances=[]
#for循环找出测试数据与训练集每一个点的距离
for x_train in X_train:
d = math.sqrt(np.sum((x_train[0]-X_test[0])**2+(x_train[1]-X_test[1])**2))
distances.append(d)
np.argsort(distances) #从小到大排列后返回索引
这里将所有距离放入一个列表,并按顺序排列后,找到其位置对应的iris_dataset中的位置
array([110, 51, 115, 137, 104, 147, 116, 56, 144, 75, 100, 124, 140,
65, 86, 136, 77, 145, 143, 58, 74, 148, 112, 103, 54, 120,
128, 132, 52, 141, 139, 97, 127, 91, 133, 50, 126, 76, 63,
111, 85, 138, 123, 73, 71, 78, 70, 61, 102, 149, 125, 83,
134, 72, 146, 108, 129, 109, 114, 95, 96, 107, 101, 67, 142,
82, 99, 55, 92, 88, 66, 87, 64, 130, 121, 18, 79, 94,
36, 68, 113, 14, 105, 31, 84, 20, 119, 62, 69, 90, 10,
135, 89, 122, 81, 80, 48, 5, 16, 28, 27, 117, 118, 53,
59, 23, 33, 39, 17, 0, 15, 21, 35, 49, 7, 25, 26,
46, 44, 19, 131, 43, 40, 4, 98, 32, 34, 9, 1, 37,
30, 11, 45, 24, 12, 106, 93, 57, 2, 29, 47, 3, 6,
60, 22, 42, 38, 8, 41, 13], dtype=int64)
#原生Python实现KNN过程
import math
distances=[]
#for循环找出测试数据与训练集每一个点的距离
for x_train in X_train:
d = math.sqrt(np.sum((x_train[0]-X_test[0])**2+(x_train[1]-X_test[1])**2))
distances.append(d)
nearest = np.argsort(distances) #从小到大排列后返回索引
k = 5 #随便填写一个值作为要选取最近点的个数
near_y = [y_train[i] for i in nearest[:k]]
near_y
[2, 1, 2, 2, 2]
这里就能从对应位置,找到对应y_train中的值
这样就能看出黑色位置周围,哪个种类多,哪个种类少了,最后再用代码实现返回即可
最后将所有代码封装到一块
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
import random
import math
iris_dataset = load_iris()
raw_x = iris_dataset['data'][:150] #
raw_y = iris_dataset['target'][:150]# 原生的鸢尾花数据集
X_train = np.array(raw_x) #将鸢尾花数据集添加到 numpy的数组中 作为训练集
y_train = np.array(raw_y)
#这里为了方便只用了花萼的长,宽作为横纵坐标
plt.scatter(X_train[y_train==0,0],X_train[y_train==0,1],color='#FF00FF') #紫色点代表setosa
plt.scatter(X_train[y_train==1,0],X_train[y_train==1,1],color='#FFFF00') #黄色点代表versicolor
plt.scatter(X_train[y_train==2,0],X_train[y_train==2,1],color='#00FFFF') #青色代表virginica
test = random.randint(1,149)
X_test = iris_dataset['data'][test] #产生一个随机的鸢尾花数据
plt.scatter(X_test[0],X_test[1],color='#000000') #将测试数据用黑色添加在图标中
plt.ylabel('sepal width', fontsize=14)
plt.xlabel('sepal length', fontsize=14)
plt.show()
#
#原生Python实现KNN过程
#
def My_KNN(X_train,y_train,k,test,current_list):#K随便填写一个值作为要选取最近点的个数,但只能是奇数方便做判断
distances=[]
#for循环找出测试数据与训练集每一个点的距离
for x_train in X_train:
d = math.sqrt(np.sum((x_train[0]-X_test[0])**2+(x_train[1]-X_test[1])**2))
distances.append(d)
nearest = np.argsort(distances) #从小到大排列后返回索引
near_y = [y_train[i] for i in nearest[:k]]
for vote in near_y: #for循环选出数组中出现次数最多的y值
a=0
b=0
c=0
vote_out = 0
if vote == 0:
a+=1
elif vote == 1:
b+=1
else:
c+=1
if b>(c or a):
vote_out = 1
elif c>( b or a):
vote_out = 2
else:
vote_out = 0
####### vote_out就是 从邻近点集中选出最多的点就是预测的鸢尾花种类
if vote_out == y_train[test]: #如果预测结果与实际结果相同,在数组中添加1反之为0
current_list.append(1)
else:
current_list.append(0)
print(vote_out,y_train[test])
这里用循环产生50个测试集,来测试My_KNN()函数
current_list=[]
count = 0
k = 5
#####循环生成50个测试集
for i in range(50):
count+=1
test = random.randint(1,149)
X_test = iris_dataset['data'][test]
My_KNN(X_train,y_train,k,test,current_list)
current_list
percent = sum(current_list)/len(current_list) #因为数组内只有0和1 所以数组内元素相加/数组长度就是正确率
print("""
在抽选{0}组数据中,K为{1},其算法预测的准确度为{2}
""".format(count,k,percent))
输出结果为:
“抽选50组数据中,K为5,其算法预测的准确度为0.72”
