不同颜色的鸢尾花花语不尽相同,蓝色鸢尾花语是精致的美丽,红色鸢尾花的花语代表着热情、适应力强。紫蓝色鸢尾花花语代表着好消息、想念你。黄色鸢尾花的花语代表着友谊永固、热情开朗,白色鸢尾花花语代表着纯真。

因为在上机器学习的课程,作业即通过python实现KNN算法
算法设计
1、 KNN算法简单描述:
KNN算法用于分类,基本思想就是:我们已经有一些已知类型的数据,称为训练集;
当一个新数据(称为测试集)进入的时候,开始跟训练集数据中的每个数据点求距离,挑选与这个训练集中最近的K个点看这些点属于什么类型,用少数服从多数的方法将测试数据分类。(如下图)
图片来源于某位大佬博客,致谢

KNN算法优点
简单易用,相比其他算法,KNN算是比较简洁明了的算法。即使没有很高的数学基础也能搞清楚它的原理。
模型训练时间快,上面说到KNN算法是惰性的,这里也就不再过多讲述。
预测效果好。
对异常值不敏感
KNN算法缺点
对内存要求较高,因为该算法存储了所有训练数据
预测阶段可能很慢
对不相关的功能和数据规模敏感
至于什么时候应该选择使用KNN算法,sklearn的这张图给了我们一个答案。
sklearn算法选择

2、 python实现KNN算法:
(1) 加载数据:
数据在网上下载为txt文档,格式如下(150组)
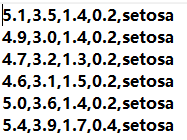
以split参数为限,将小于split的随机数对应的数据划分到训练集,大于则划分到测试集。
1. def loadDataset(self,filename, split, trainingSet, testSet): # 加载数据集 split以某个值为界限分类train和test
2. with open(filename, 'r') as csvfile:
3. lines = csv.reader(csvfile) #读取所有的行
4.
5. dataset = list(lines) #转化成列表
6. for x in range(len(dataset)-1):
7. for y in range(4):
8. dataset[x][y] = float(dataset[x][y])
9. if random.random() < split: # 将所有数据加载到train和test中
10. trainingSet.append(dataset[x])
11. else:
12. testSet.append(dataset[x])
(2) 对每个数据集中的数据进行迭代,取临近点:
计算测试集中每个点到训练集中每个点的距离,将这些距离升序排序,取最近的K个点作为归类点;
1. def getNeighbors(self,trainingSet, testInstance, k): # 返回最近的k个边距
2. distances = []
3. length = len(testInstance)-1
4. for x in range(len(trainingSet)): #对训练集的每一个数计算其到测试集的实际距离
5. dist = self.calculateDistance(testInstance, trainingSet[x], length)
6. print('训练集:{}-距离:{}'.format(trainingSet[x], dist))
7. distances.append((trainingSet[x], dist))
8. distances.sort(key=operator.itemgetter(1)) # 把距离从小到大排列
9. neighbors = []
10. for x in range(k): #排序完成后取前k个距离
11. neighbors.append(distances[x][0])
12. print(neighbors)
13. return neighbors
计算距离函数:
距离计算
二维空间两个点的欧式距离计算公式如下:
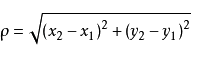
计算(x1,y1)和(x2,y2)的距离。拓展到多维空间,则公式变成这样:
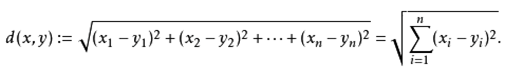
1. def calculateDistance(self,testdata, traindata, length): # 计算距离
2. distance = 0 # length表示维度 数据共有几维
3. for x in range(length):
4. distance += pow((testdata[x]-traindata[x]), 2)
5. return math.sqrt(distance)
(3) 判断每个点所属的类别,选择出现频率最大的类标号作为测试集的类标号
(4) def getResponse(self,neighbors): # 根据少数服从多数,决定归类到哪一类
(5) classVotes = {}
(6) for x in range(len(neighbors)):
(7) response = neighbors[x][-1] # 统计每一个分类的多少
(8) if response in classVotes:
(9) classVotes[response] += 1
(10) else:
(11) classVotes[response] = 1
(12) print(classVotes.items())
(13) sortedVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True) #reverse按降序的方式排列
(14) return sortedVotes[0][0]
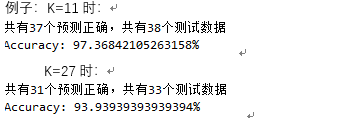
3、 取K值:在使用KNN算法之前,我们要先决定K的值是多少,要选出最优的K值,可以使用sklearn中的交叉验证方法:

运行结果:可以看出k=11的时候预测准确率最好
1. # -*- coding: utf-8 -*-
2. """
3. Created on Mon Oct 14 15:45:44 2019
4.
5. @author: 商嘉鑫
6. """
7.
8. from sklearn.datasets import load_iris
9. from sklearn.model_selection import cross_val_score
10. import matplotlib.pyplot as plt
11. from sklearn.neighbors import KNeighborsClassifier
12. def loadDataset(self,filename, split, trainingSet, testSet): # 加载数据集 split以某个值为界限分类train和test
13. with open(filename, 'r') as csvfile:
14. lines = csv.reader(csvfile) #读取所有的行
15.
16. dataset = list(lines) #转化成列表
17. #读取鸢尾花数据集
18. x = dataset.data
19. y = dataset.target
20. k_range = range(1, 31)
21. k_error = []
22.
23. for k in k_range:
24. knn = KNeighborsClassifier(n_neighbors=k)
25. #cv参数决定数据集划分比例,这里是按照5:1划分训练集和测试集
26. scores = cross_val_score(knn, x, y, cv=6, scoring='accuracy')
27. k_error.append(1 - scores.mean())
28.
29. #画图,x轴为k值,y值为误差值
30. plt.plot(k_range, k_error)
31. plt.xlabel('Value of K for KNN')
32. plt.ylabel('Error')
33. plt.show()
流程图:
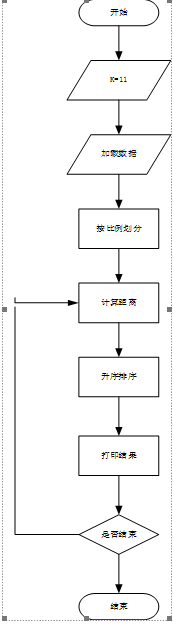
源码下载即数据集点击
撒花撒花~~有错误请大佬指出
参考文献:https://www.cnblogs.com/listenfwind/p/10311496.html
