文章目录
Ma, X. and E. Hovy “End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF.”
abstract
最先进的序列标记系统传统上需要大量的手工特征和数据预处理的特定任务的知识。在这篇论文中,我们介绍了一种新的中立网络架构,它利用双向LSTM、CNN和CRF的组合,自动地从字级和字级表示中获益。我们的系统是真正的端到端的,不需要特征工程或数据预处理,因此适用于广泛的序列标记任务。我们用两个数据集来评估我们的系统,这两个数据集分别用于两个序列标记任务:Penn Treebank WSJ词性标记语料库(POS)和CoNLL 2003命名实体识别语料库(NER)。我们获得了最先进的性能,这两个数据集的准确性为97.55%的POS标签和91.21%的F1为NER。
- 利用双向LSTM、CNN和CRF的组合,自动地从字级和字级表示中获益
- 端到端,无需特征工程或数据预处理
1.introduction
摘要语言序列标记是语言深层理解的第一个阶段,如词性标记和命名实体识别,其重要性已被自然语言处理界所认识。自然语言处理(NLP)系统,如句法分析(Nivre and Scholz, 2004;McDonald等人,2005;辜朝明和柯林斯出版社,2010年;马和赵,2012a;马和赵,2012b;陈和曼宁,2014;(Ma and Hovy, 2015)和实体共引用解析(Ng, 2010;Ma et al., 2016),正变得越来越复杂,部分原因是利用POS标记或NER系统的输出信息。
大多数传统高性能序列标签模型是线性统计模型,包括隐马尔科夫模型(HMM)和条件随机域(CRF) (Ratinov和罗斯,2009;Passos et al ., 2014;罗et al ., 2015),严重依赖于手工特性和taskspecific资源。例如,英语POS涂画者受益于精心设计的单词拼写功能;正字法的特性和外部资源等地名表广泛应用于ner。然而,这样的特定于任务的知识是昂贵的开发(马和夏,2014),使序列标签模型难以适应新的任务或新领域。
- 传统:HMM,CRF,手工特征代价昂贵
近年来,以分布式词表示为输入的非线性神经网络(又称词嵌入)被广泛地应用于NLP问题,并取得了很大的成功。Collobert等人(2011)提出了一种简单而有效的前馈中性网络,通过在固定大小的窗口内使用上下文独立地对每个单词的标签进行分类。最近,循环神经网络(RNN) (Goller and Kuchler, 1996)及其变体,如长短时记忆(LSTM) (Hochreiter and Schmidhuber, 1997;Gers等人(2000)和门控递归单元(GRU) (Cho等人,2014)在序列数据建模方面取得了巨大成功。针对语音识别(Graves et al., 2013)、词性标注(Huang et al., 2015)和NER (Chiu and Nichols, 2015)等序列标记任务,提出了几种基于rnn的神经网络模型;(Hu et al., 2016),实现与传统模式的竞争绩效。然而,即使是使用分布式表示作为输入的系统,也会使用它们来增强而不是取代手工制作的功能(例如单词拼写和大小写模式)。当模型仅仅依赖于神经嵌入时,它们的性能会迅速下降。
- 目前都是用nn来增强手工特征,而非取代。
- 仅依靠nn,性能会迅速下降。
本文提出了一种用于序列标记的神经网络结构**它是一个真正的端到端的模型,不需要特定于任务的资源、功能工程或数据预处理,只需要在未标记的语料库上预先训练好的词嵌入即可。因此,我们的模型可以很容易地应用于不同语言和领域的序列标记任务。我们首先使用卷积神经网络(convolutional neural networks, CNNs) (LeCun et al., 1989)将一个单词的字符级信息编码到它的字符级表示中。然后,我们将字符级和字级表示相结合,并将它们输入到双向LSTM (BLSTM)中,以对每个单词的上下文信息进行建模。在BLSTM之上,我们使用一个连续的CRF来联合解码整个句子的标签。**我们在Penn Treebank的两个语言序列标记任务上对我们的模型进行了评估(Marcus et al., 1993),和NER对CoNLL 2003共享任务的英语数据进行了评估(Tjong Kim Sang和De Meulder, 2003)。我们的端到端模型优于之前的先进系统,POS标签的准确率为97.55%,NER标签的准确率为91.21%。本工作的贡献在于(i)提出了一种用于语言序列标记的新型神经网络结构。(ii)对两个经典NLP任务的基准数据集对该模型进行实证评价。(iii)采用真正的端到端系统,达到最先进的性能。
- 它是一个真正的端到端的模型,不需要特定于任务的资源、功能工程或数据预处理,只需要在未标记的语料库上预先训练好的词嵌入即可。因此,我们的模型可以很容易地应用于不同语言和领域的序列标记任务。
- 我们首先使用卷积神经网络(convolutional neural networks, CNNs) (LeCun et al., 1989)将一个单词的字符级信息编码到它的字符级表示中。
- 然后,我们将字符级和字级表示相结合,并将它们输入到双向LSTM (BiLSTM)中,以对每个单词的上下文信息进行建模。
- 在BiLSTM之上,我们使用一个连续的CRF来联合解码整个句子的标签。
2.Architecture
CNN+BiLSTM+CRF
2.1 CNN for Character-level Representation
(Santos和Zadrozny, 2014;Chiu和Nichols, 2015)的研究表明,CNN是一种从单词字符中提取形态学信息(如单词的前缀或后缀)并将其编码成神经表征的有效方法。图1显示了我们用来提取给定单词的字符级表示的CNN。CNN与Chiu和Nichols(2015)的CNN类似,只是我们只使用字符嵌入作为CNN的输入,没有字符类型特征。在向CNN输入字符嵌入之前应用一个dropout层(Srivastava et al., 2014)。
- CNN
- 输入:字符嵌入
- dropout层(CNN之前)

2.2 BiLSTM
2.2.1 LSTM单元

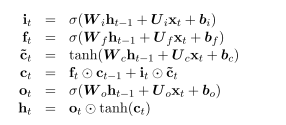
2.2.2BiLSTM
对于许多序列标记任务,同时访问过去(左)和未来(右)上下文是有益的。然而,LSTM的隐藏状态ht只从过去获取信息,对未来一无所知。一个优雅的解决方案是双向LSTM (BLSTM),它的有效性已经被以前的工作所证明(Dyer et al., 2015)。基本思想是将每个序列向前和向后呈现为两个独立的隐藏状态,分别捕获过去和未来的信息。然后将这两个隐藏状态连接起来,形成最终的输出。
- 双向链接起来就行。
2.3CRF
对于序列标记(或一般的结构化预测)任务,考虑邻域内标签之间的相关性,共同解码给定输入语句的最佳标签链是有益的。例如,在词性标注中,形容词后面紧跟名词的可能性比动词大,而在带有标准BIO2注释的NER中(Tjong Kim Sang和Veenstra, 1999), I-ORG不能跟I-PER。因此,我们联合使用条件随机域(CRF)对标签序列进行建模(Lafferty et al., 2001),而不是单独对每个标签进行解码。
- 可以进行约束。
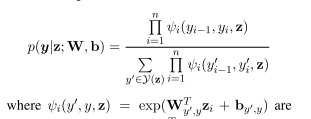
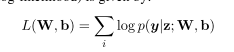
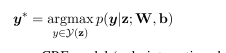
- 用贪婪的维特比解码
2.4BiLSTM-CNNs-CRF

3.训练
- word-embedding:tanford’s publicly available GloVe 100-dimensional embeddings
