文章目录
Jagannatha, A. and H. Yu “Structured prediction models for RNN based sequence labeling in clinical text.”
abstract
序列标记是一种广泛应用于非结构化自然语言数据中命名实体识别和信息提取的方法。在临床领域,序列标记的一个主要应用涉及从电子健康记录叙述中提取医疗实体,如药物、适应症和副作用。序列标记,在这个领域,提出了自己的一套挑战和目标。在这项工作中,我们使用递归神经网络实验了各种基于CRF的结构化学习模型。我们扩展了先前研究的LSTM-CRF模型,对成对电位进行了显式建模。我们还提出了一个具有RNN势的跳跃链CRF推理的近似版本。我们将这些方法用于结构化预测,以提高对各种医疗实体的准确短语检测。
- LSTM_CRF
- 具有RNN势的跳跃链CRF推理的近似版本
- 原文code
1. Introduction
医院收集的患者数据分为两类:结构化数据和非结构化自然语言文本。研究表明,出院总结、病程记录等自然文本医疗数据是药物不良事件、药物处方、诊断信息等医学相关信息的丰富来源。从这些天然文本文件中提取的信息可用于多种用途,从药物疗效分析到不良反应监测。
广泛应用的信息提取序列标记方法是对非结构化自然语言数据进行命名实体识别和信息提取的一种常用方法。在临床领域,序列标记的一个主要应用涉及从电子健康记录叙述中提取医疗实体,如药物、适应症和副作用。序列标记,在这个领域,提出了自己的一套挑战和目标。在这项工作中,我们使用递归神经网络实验了各种基于CRF的结构化学习模型。我们扩展了先前研究的LSTM-CRF模型,对成对电位进行了显式建模。我们还提出了一个具有RNN势的跳跃链CRF推理的近似版本。我们将这些方法用于结构化预测,以提高对各种医疗实体的准确短语检测。
最近,递归(RNN)或卷积神经网络(CNN)模型越来越多地用于各种NLP相关任务。然而,这些神经网络本身并不把序列标记看作是一个结构化的预测问题。不同的神经网络模型使用不同的方法来合成每个单词的上下文向量。这个上下文向量包含当前单词及其邻近内容的信息。在CNN的例子中,相邻词由相同大小窗口的单词组成,而在双向rnn (Bi-RNN)中它们包含整个句子。
- RNN中:窗口是整个句子(上下文)
图形模型和神经网络各有优缺点。虽然图形模型可以联合预测整个标签序列,但它们通常需要特殊的手工特性来提供良好的结果。另一方面,神经网络(尤其是递归神经网络)已被证明在从噪音文本数据中识别模式方面非常擅长,但是他们仍然独立地预测每个单词的标签,而不是作为一个序列的一部分。
简单来说,RNN受益于识别周围输入特征的模式,而CRF等结构化学习模型受益于邻近标签预测的知识。近期的命名实体识别研究(Huang et al., 2015)等将神经网络与CRF的优点结合起来,将CRF的一元势函数建模为神经网络模型。他们将两两配对的电位模型化为一个矩阵[a],其中Ai、j分别对应从标签i到标签j的转移概率.在神经网络模型中加入CRF推理有助于通过强制成对约束来标记各种命名实体的精确边界。
- RNN受益于识别周围输入特征的模式,
- 而CRF等结构化学习模型受益于邻近标签预测的知识。
- l两者结合更好。(在神经网络模型中加入CRF推理有助于通过强制成对约束来标记各种命名实体的精确边界。)
这项工作的重点是在电子健康记录的非结构化临床记录中标注医疗事件(药物、指征和不良药物事件)和事件相关属性(药物剂量、用药途径等)。稍后在第4部分中,我们将显式定义我们所评估的医疗事件和属性。为了简单起见,对于本文的其余部分,我们使用广义的术语“医疗实体”来指代我们感兴趣的所有医疗相关信息
在医疗文件中检测医疗实体,如由临床医生编写的电子健康记录笔记,与在NLP中类似的序列标记应用(如命名实体识别),呈现出一些不同的挑战。这种差异部分是由于医学领域的关键性质,部分是由于医学文本和其中实体的性质。首先,在医学领域,准确的医学短语的提取是非常重要的。医学实体的名称通常遵循多项式命名法。如葡萄膜黑色素瘤或毛细胞白血病等疾病名称需要准确识别,因为部分名称(毛细胞或黑色素瘤)可能有显著不同的含义。此外,重要的医疗实体可能是电子健康记录中相对罕见的事件。例如,在我们的语料库中,每600个单词中就会出现一次药品不良事件。之前引用的NN模型的CRFs推理确实改进了短语的精确标注。然而,对CRFs的成对势函数进行建模的更好方法可能导致在标记稀有实体和检测精确短语bondaries方面的改进。
- 上面是对于医学特性的要求(挑战一)
- 下面是挑战二(要长期标签依赖建模)
- CRF(短期依赖)+RNN的长期依赖
该领域的另一个重要挑战是需要对长期标签依赖关系进行建模。例如,在“患者表现为A继发于B”这句话中,A的标签与B的标签预测有很强的相关性。如果B是药物或诊断,A既可以被标记为药物不良反应,也可以被标记为症状。传统的线性链CRF方法只执行局部成对约束,可能不适合对这些依赖关系进行建模。可以认为,RNNs可能通过相邻单词的输入特性中的模式隐式地建模标签依赖关系。
在这项工作中,我们探讨了使用基于RNN的特征提取器进行结构化学习的各种方法。我们使用LSTM作为我们的RNN模型。具体来说,我们使用神经网络来模拟CRF成对电位。我们还对一个近似版本的跳跃链CRF进行建模,以捕获前面提到的长期标签依赖关系。我们证明,与具有相同数量可训练参数的标准LSTM或CRF-LSTM模型相比,这些改进的框架提高了性能。据我们所知,这是唯一一项专注于使用和分析基于RNN的结构化学习技术的工作
2.相关工作
正如前面所提到的,神经网络和条件随机域都被广泛地用于NLP中的序列标记任务。特别地,CRFs (Lafferty et al., 2001)在一般情况下被用于各种序列标记任务,特别是命名实体识别方面有着悠久的历史。早期的一些著名作品包括McCallum等人(2003),Sarawagi等人(2004)和Sha等人(2003)。Hammerton等人(2003)和Chiu等人(2015)使用长短时记忆(LSTM) (Hochreiter和Schmidhuber, 1997)进行命名实体识别。
最近在基于图像和文本领域的一些工作中,使用了结构化推理来提高基于神经网络的模型的性能。在NLP中,Collobert等(2011)使用了卷积传统的神经网络来模拟一元势。Lample等人(2016)和Huang等人(2015)专门针对递归神经网络,使用LSTMs对CRF的一元势进行建模。
在生物测定的命名实体识别中,有几种方法使用带有实体(如蛋白质或基因名称)注释的生物语料库。settle(2004)使用条件随机字段提取蛋白质、DNA和类似的生物实体类。Li et. al.(2015)最近使用LSTM进行命名实体识别或生物创造语料库中的蛋白/基因名称。Gurulingappa等人(2010)对现有的各种生物医学词典进行了评估,以从Medline摘要语料库中提取不良反应和疾病。
我们的工作使用一个真实世界的电子健康记录的临床语料库注释了各种医疗实体。其他使用真实世界医学语料库的作品包括Rochefort等人(2015),他们研究的是叙述性放射学报告。他们使用一种基于svm的分类器和一袋单词的特征向量来预测深静脉血栓和肺栓塞。Miotto et. al.(2016)使用去噪自编码器构建电子健康记录的无监督表示,可用于患者健康的预测建模
3.方法
我们使用Bi-RNNs作为单词序列的特征提取器。我们评估了三种不同的结构化学习方法。基线是一个双向递归神经网络,如3.1节所述。
3.1 Bi-LSTM (baseline)
- embedding+BiLSTM+softmax
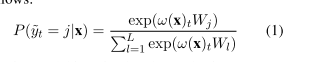
- loss:交叉熵
3.2BiLSTM+CRF
- BiLSTM如上
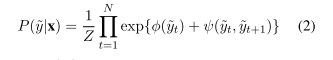
- BiLSTM的输出经过tanh层得到矩阵A(LXL)
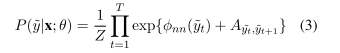
- 损失函数log-likelihood
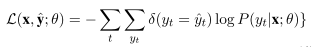

3.3 BiLSTM_CRF with pairwise modeling
在前一节中,成对的电位是通过一个转移概率矩阵来计算的[A],而与当前的上下文或单词无关。由于第1节中提到的原因,这可能不是一个有效的策略。一些医疗实体相对少见。因此,从外部标签到医疗标签的转换可能无法通过固定的参数矩阵有效地建模。在这种方法中,成对电位是通过一个依赖于当前词汇和上下文的非线性神经网络来建模的
- 这里用
–
- LSTM->CNN(1-D,2size 的卷积)->tanh
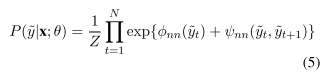
- LSTM->CNN(1-D,2size 的卷积)->tanh
3.4 Approximate Skip-chain CRF
- 线性链CRF的变种
跳跃链模型是对线性链crf的修改,允许通过使用跳跃边来实现长期的标签依赖关系。这些基本上是标签位置之间不相邻的边的相互关系。由于这些跳跃边缘,跳跃链CRF模型(Sutton和McCallum, 2006)显式地对标签之间的依赖关系建模,这些标签之间可能有不止一个位置的距离。在解码最佳标签序列时,将这些依赖项的联合推理考虑在内。然而,跳跃链CRF中的循环图使得精确推理变得难以处理。在这样的模型中,推理的近似解需要多次重复的循环信念传播(BP)。由于对于合并的RNN-CRF模型,每次梯度下降迭代都需要重新计算边缘,因此这种方法在计算上非常昂贵。Lin et. al.(2015)提出了一种缓解这一问题的方法,该方法直接对用于图像分割的二维网格CRF的消息传递推理中的消息进行建模。这绕过了对势函数建模的需要,以及使用loopy BP计算图上的近似消息的需要。
**近似CRF消息传递推理:**Lin等人(2015)利用输入图像特征的神经网络,直接对变量消息的因子进行估计。他们的基本推理是,从因子F到标记变量yt(用于任何循环BP的迭代)的因子到变量的因子到变量的消息可以近似为所有输入变量和作为该因子一部分的先前消息的函数。他们只对一个循环的BP进行建模,并通过经验表明,这将显著提高性能。这允许他们将消息建模为仅作为输入变量的函数,因为消息传递的第一次迭代的消息仅使用势函数计算。
在我们的跳跃链模型中,我们采用了类似的方法来计算可变边值。然而,我们不是估计单个因素到变量的消息,而是利用我们的问题中的序列结构并估计因素到变量的消息组。对于任何标签节点yt,第一组包含了与在句子中yt之前发生的节点相关的因子(从左至右)。第二组因素到变量的消息对应于涉及到句子后面出现的节点的因素。我们使用像LSTM这样的递归计算单元分别从左和右输入因子。来估计log因子到变量的和
我们现在假设使用跳跃边将当前节点t连接到前面的m个节点和后面的m个节点。每条边(跳跃或不跳跃)都由一个因子表示,该因子包含边的二进制势和连接节点的一元势。如前所述,我们将与节点t相关的因素分为两个集,FL(t)和FR(t)。其中FL(t)包含了{yt m,…, 1}和。因此,我们可以用FL(t)中的因子来表示组合后的信息

- FR(t)中包含从yt+1到yt+m变量的因子组合信息可以表示为:
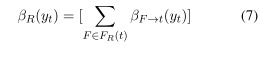
与Lin et. al.(2015)类似,为了限制网络复杂度,我们只使用一个消息传递迭代。在我们的设置中,这意味着从邻近变量yi到当前变量yt的一个变元到因子的消息只包含yi的一元势和yi、yt之间的二元势。因此,我们可以看到

- Modeling the messages using RNN:
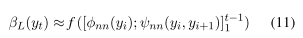
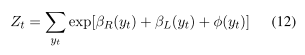
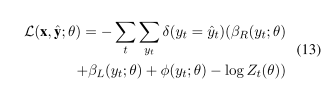
.
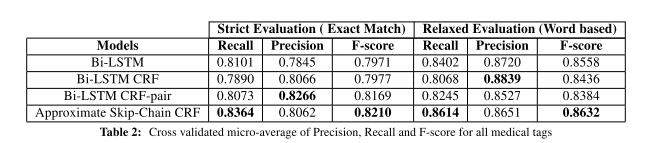
5.实验
- embedding:skip-gram
- dropout=0.5
- batch norm(层间)
- adagrad with mmentum
- BIO
- ten-fold
- early-stoping
