台湾大学李宏毅老师的机器学习课程是一份非常好的ML/DL入门资料,李宏毅老师将课程录像上传到了YouTube,地址:NTUEE ML 2016 。
这篇文章是学习本课程第22-24课所做的笔记和自己的理解。
Lecture 22: Structured Learning - Linear Model
Problem 1: Evaluation
上节课说到,Structured Learning的Unified Framework有三个问题:
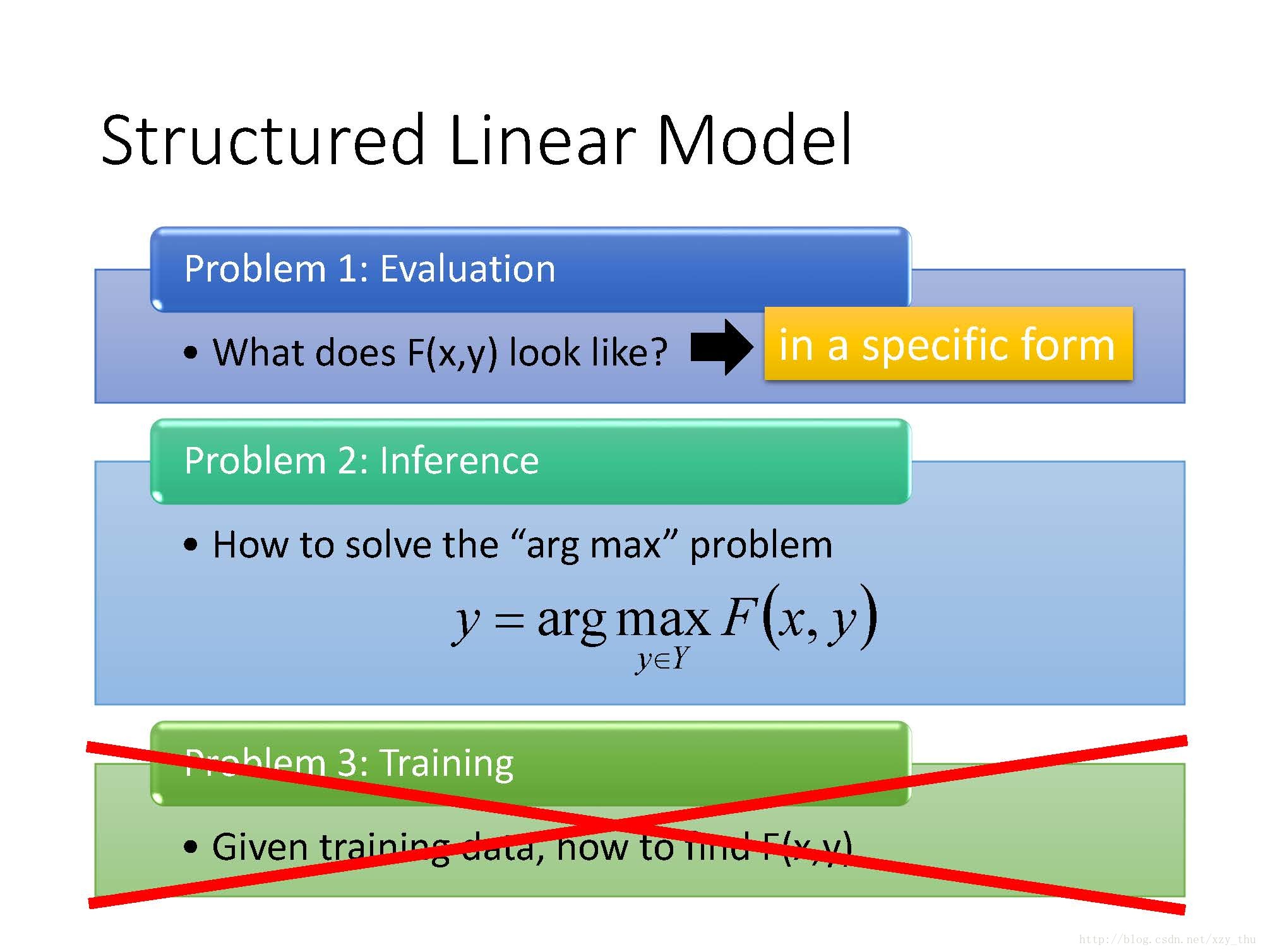
如果

这个“特定形式”的
我们用一组特征
这样,

具体来讲,对Object Detection这个任务,x是image,y是bounding box,vector
feature是由人来找还是由model来抽呢?由于
Problem 2: Inference

这里我们假设Problem 2已经解决了。
Problem 3: Training

训练时,给定训练数据,要找的是
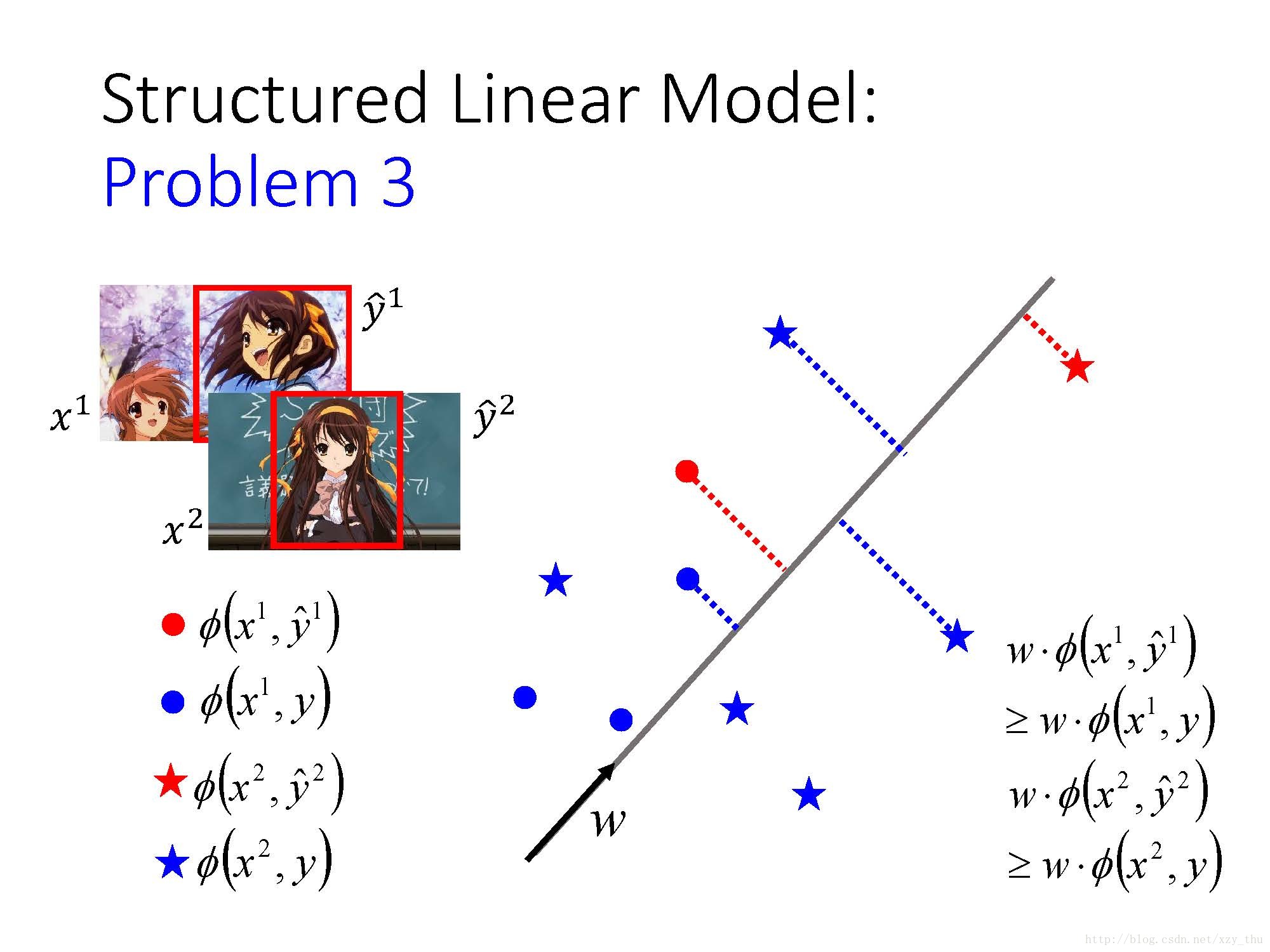
举例来讲,以Object Detection为例,对红色圈圈代表对
这个问题没有想象中那么难,只要符合要求的

说明:如果
下面形象地解释一下这个算法的过程:
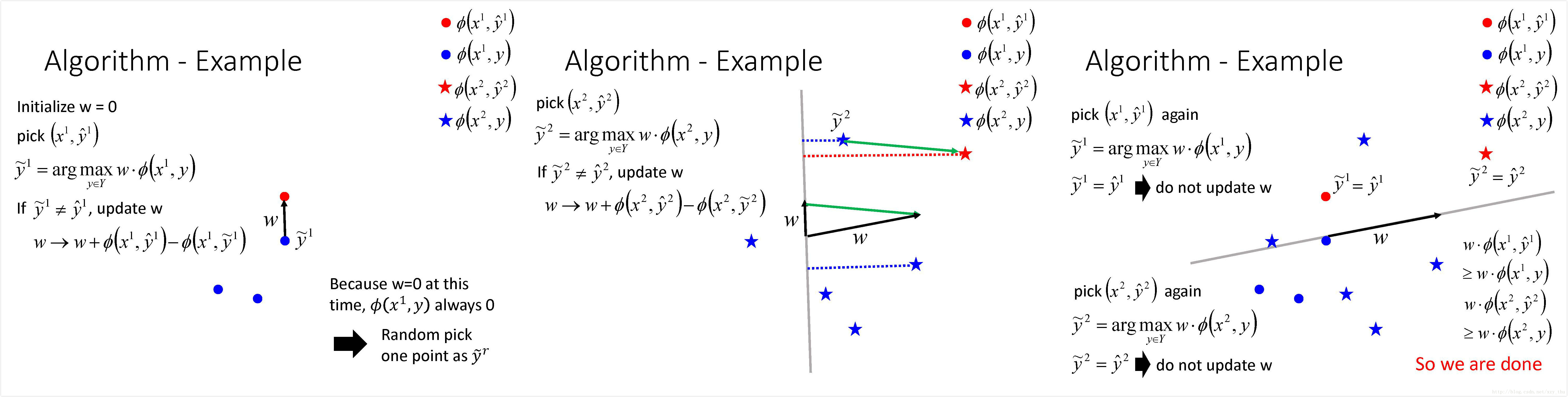
可以证明,上述算法是会结束的,与蓝色点的数目没有关系。这个证明与感知机算法的收敛性证明[李航,Chapter 2.3.2] 是很类似的。
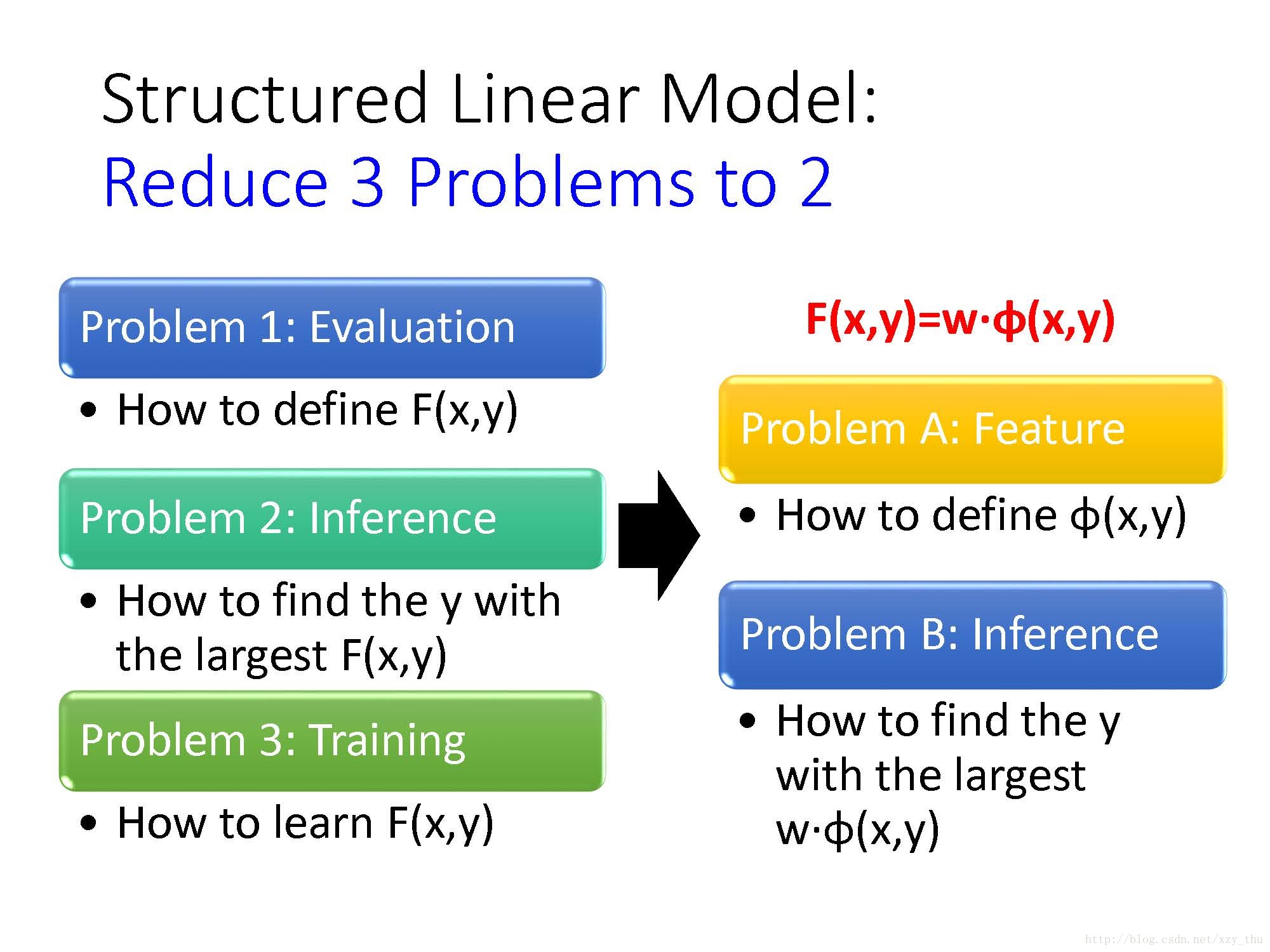
总结一下Structured Linear Model:
Lecture 23: Structured Learning - Structured SVM
本节课先简要回顾了Structured Learning的概念、Unified Framework以及要使用Unified Framework需解决的三个问题。并给出了两个开放问题:1、在Problem 1中如果
简单介绍了Problem 2中解决argmax问题的可能选项,对Object Detection, 有Branch and Bound algorithm, Selective Search; 对Sequence Labeling, 有Viterbi Algorithm. 采用哪种算法是与任务有关的,甚至在同一个任务中,
以下假设Problem 2已解决,只关注Problem3.
本讲Outline:
Separable case
对上讲中的算法(Structured Perceptron)的收敛性做了证明,由于与感知机算法的收敛性证明[李航,Chapter 2.3.2] 很类似,这里不再贴图。本课程的slides在这里。
Non-separable case
现实中很少有Separable case,因此要考虑Non-separable case。
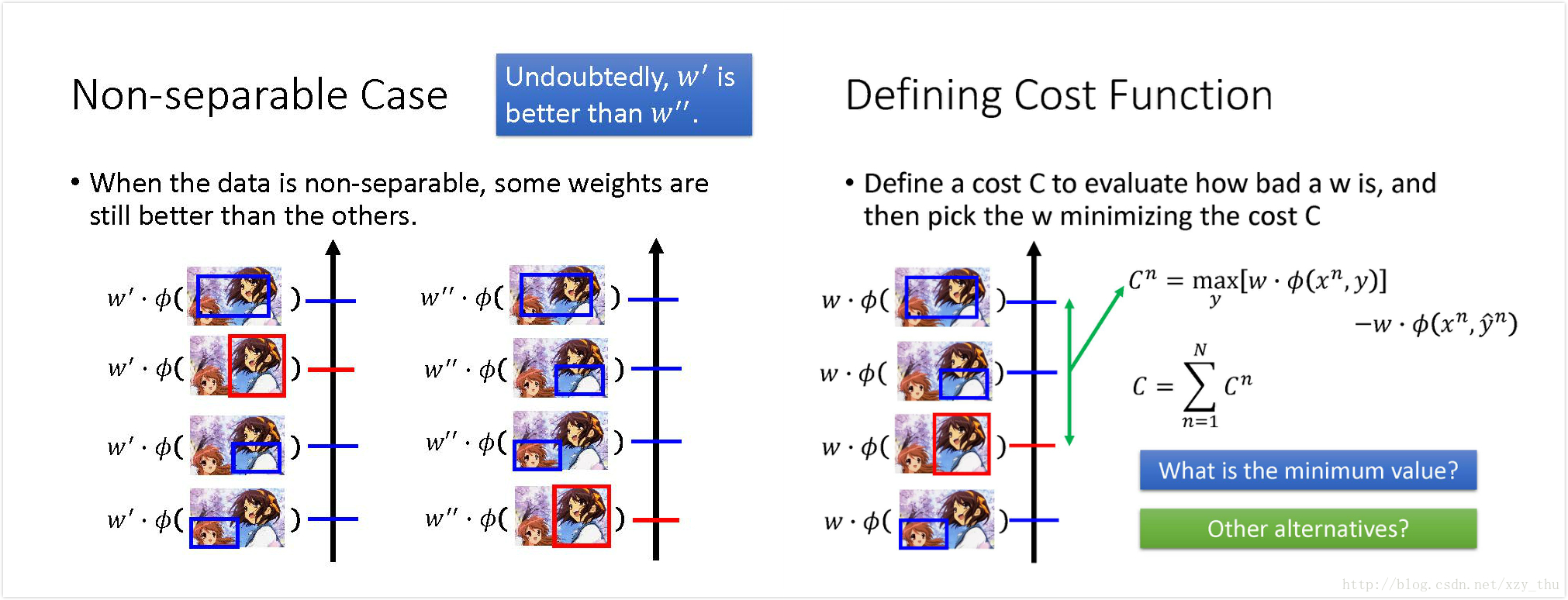
就算数据是Non-separable 的,一些
用SGD找到最小化C的
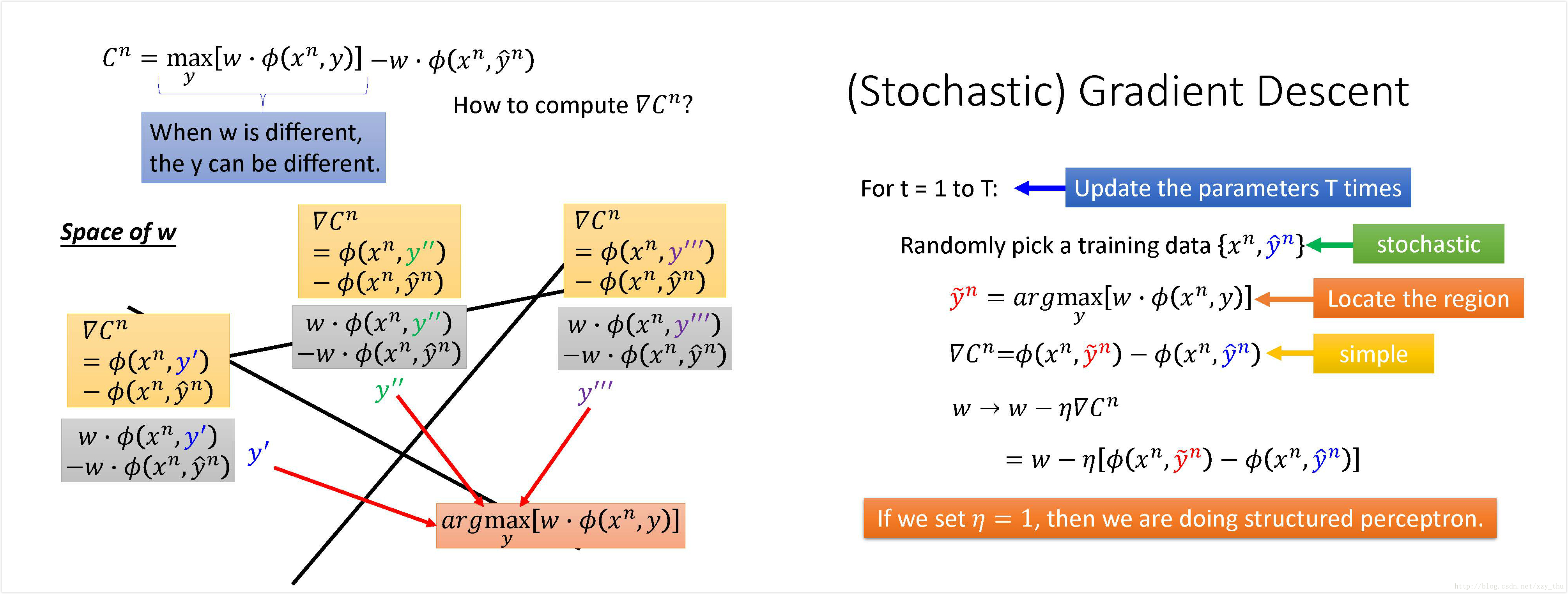
可以求出梯度就可以用SGD了,SGD过程如图所示,如果学习率设为1,就是Structured perceptron. (w减去错的feature, 加上对的feature)。
Considering Errors
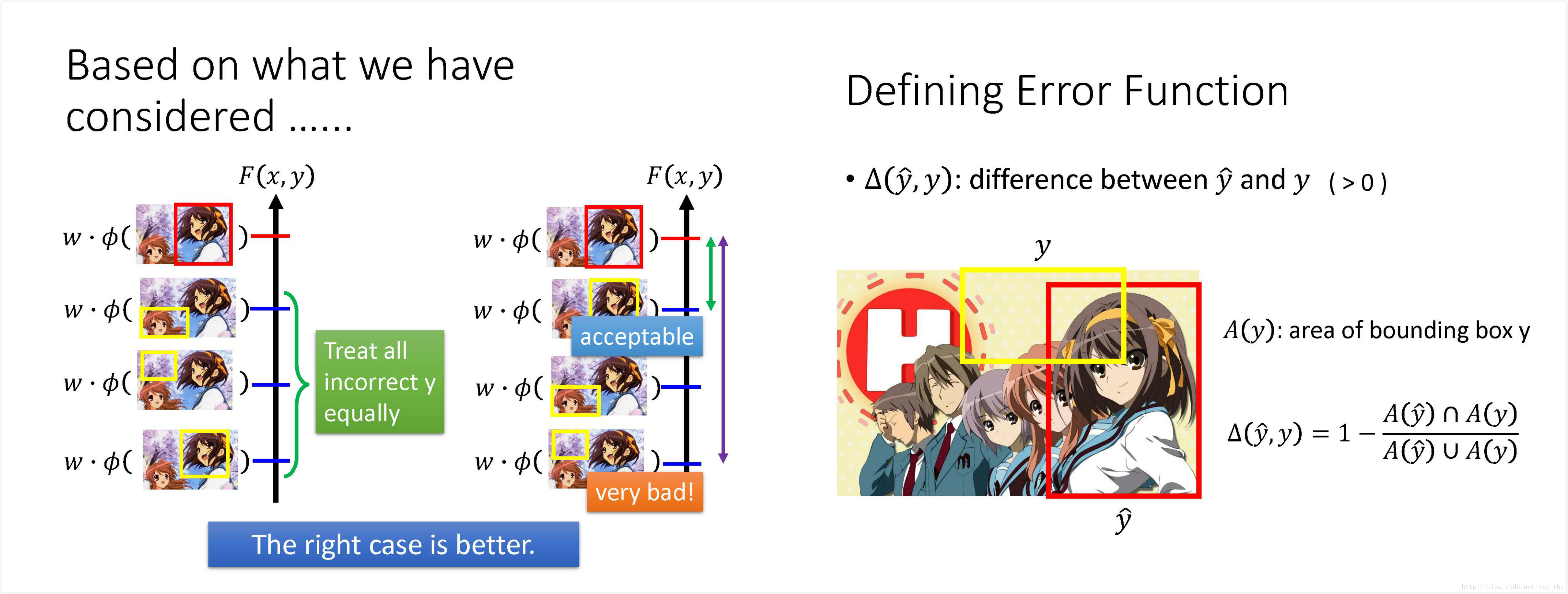
现在要修改一下刚才的Cost function, 因为错误是有不同等级的,在training的时候应考虑到这一点。若y可接受,则w应使y的得分
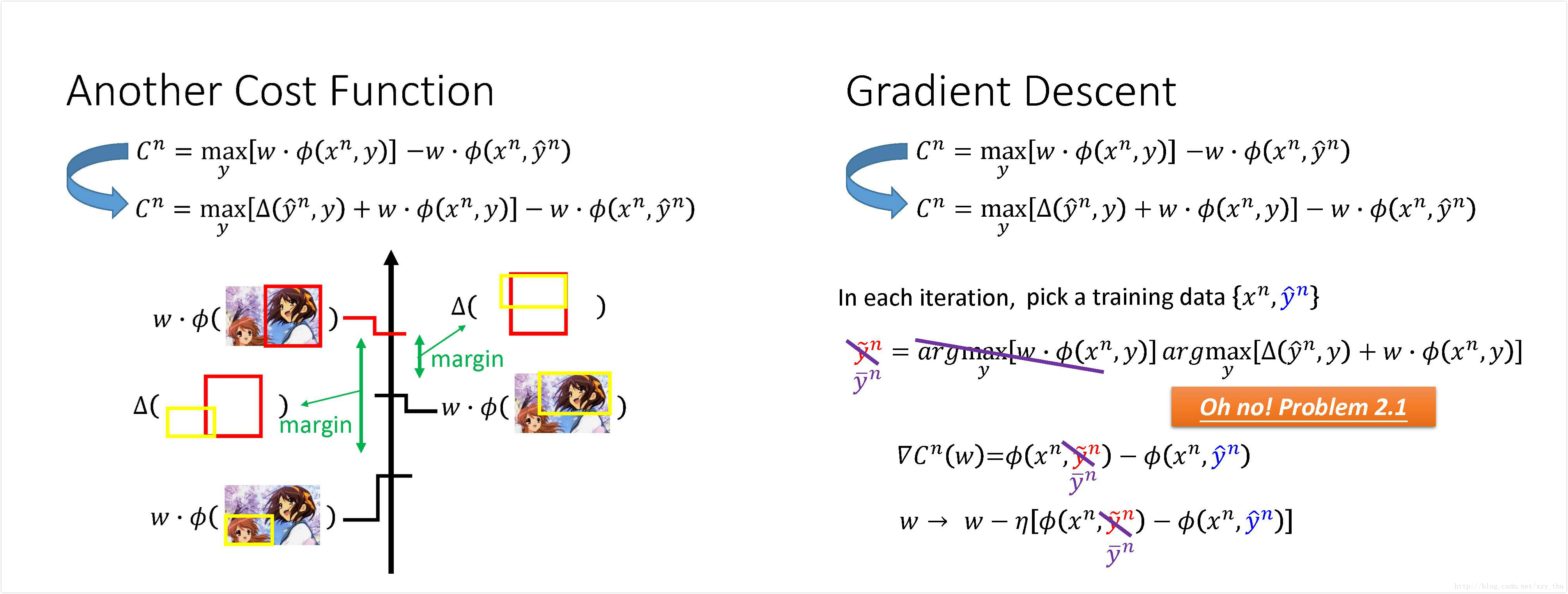
这样,衡量错误y的分数的标准就在刚才的基础
其精神在于,希望
或者可理解为
在定义
改变
从另外一个观点解释新的cost function:

这个观点是说,新的cost function 是训练误差的upper bound,最小化upper bound不代表error一定会变小,但error有可能跟着变小。
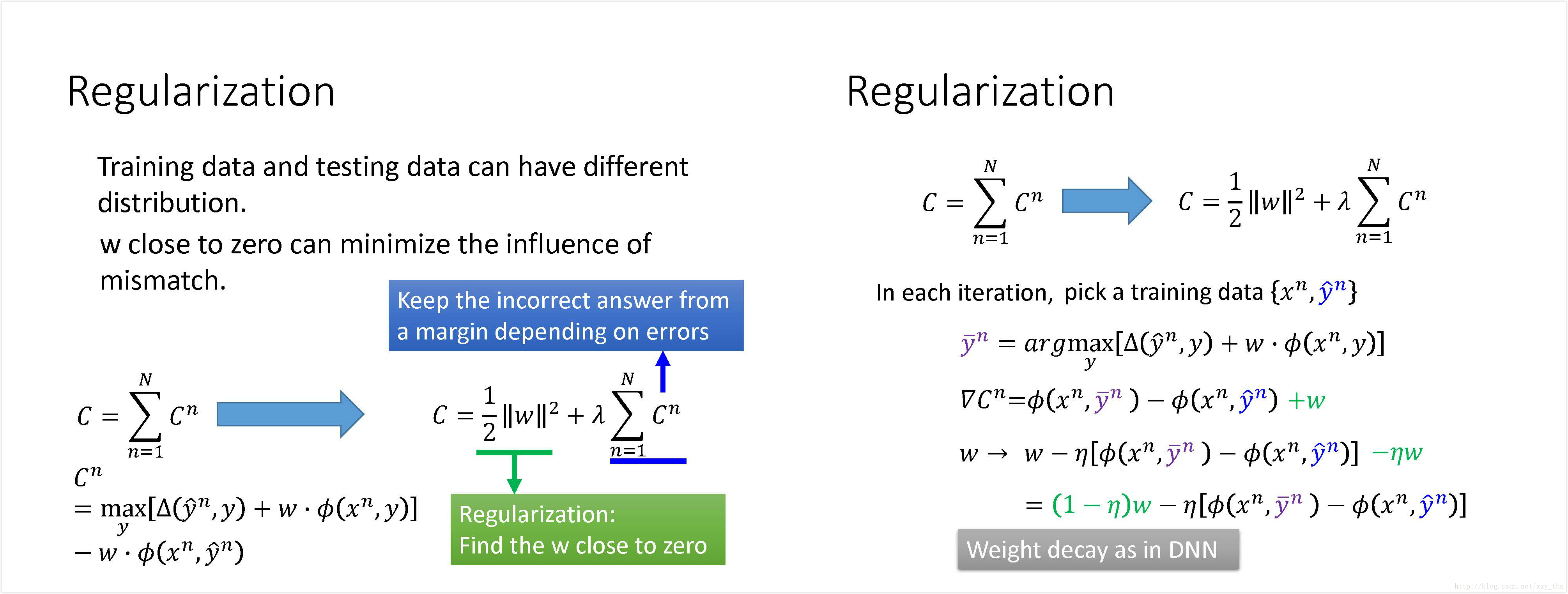
Regularization
由于训练数据和测试数据有mismatch的问题,所以加上正则项让
加上正则项之后,参数
Structured SVM

回答图中Are they equivalent?的问题:
二者本不等价,但是加上“minimizing C”之后就等价了。
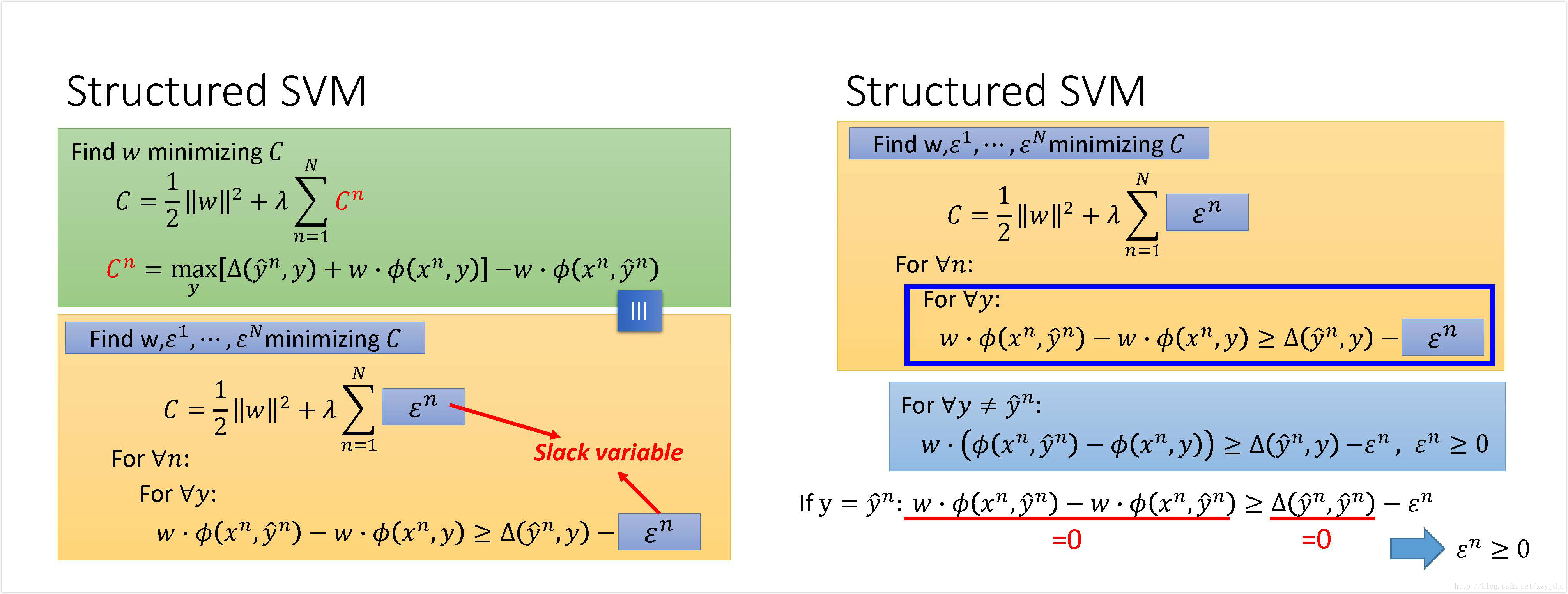
在问题的原来形式中,定好
在问题变化后的形式中,将
因此要将原来的叙述“Find
简单的将
对Structured SVM的一个直观解释:
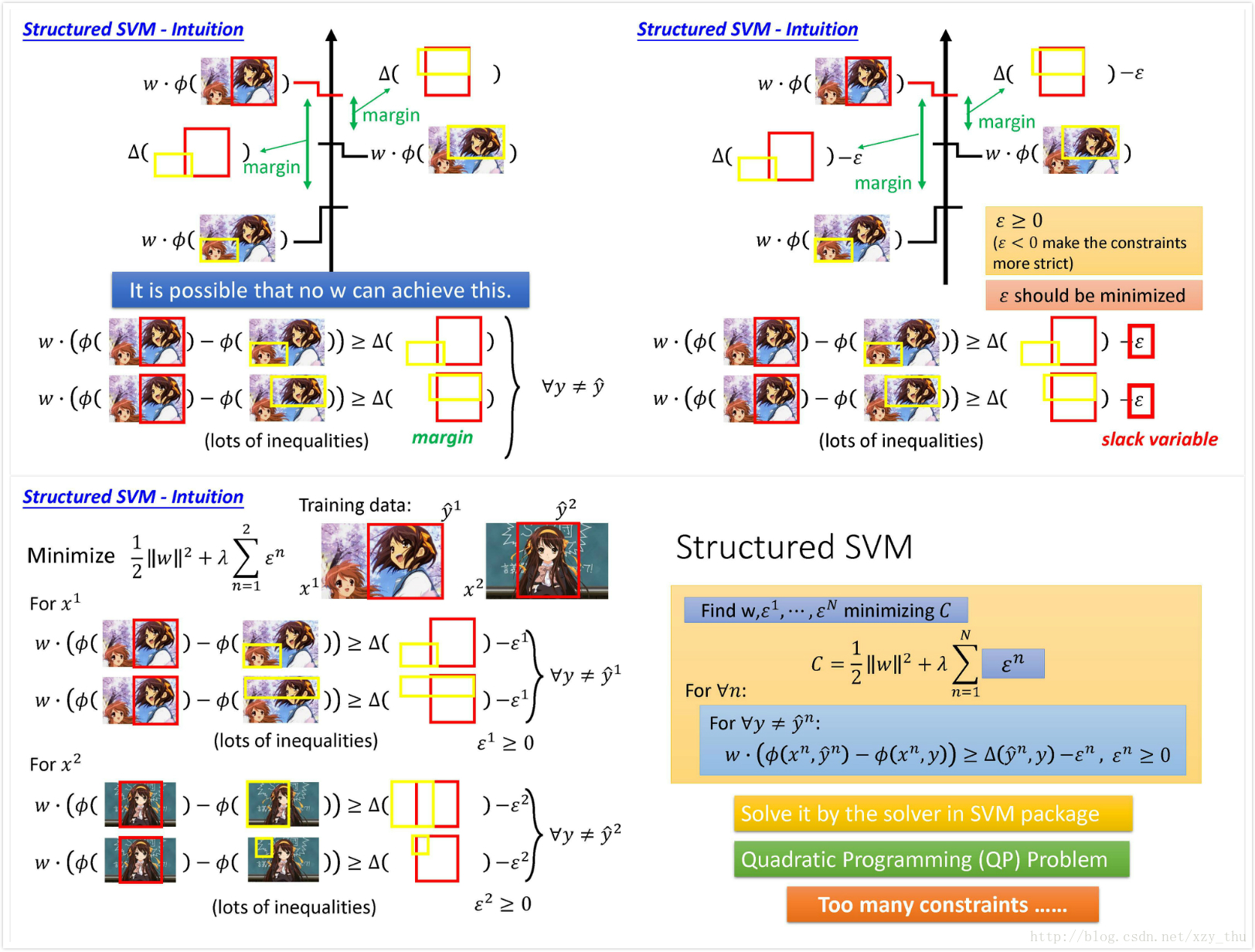
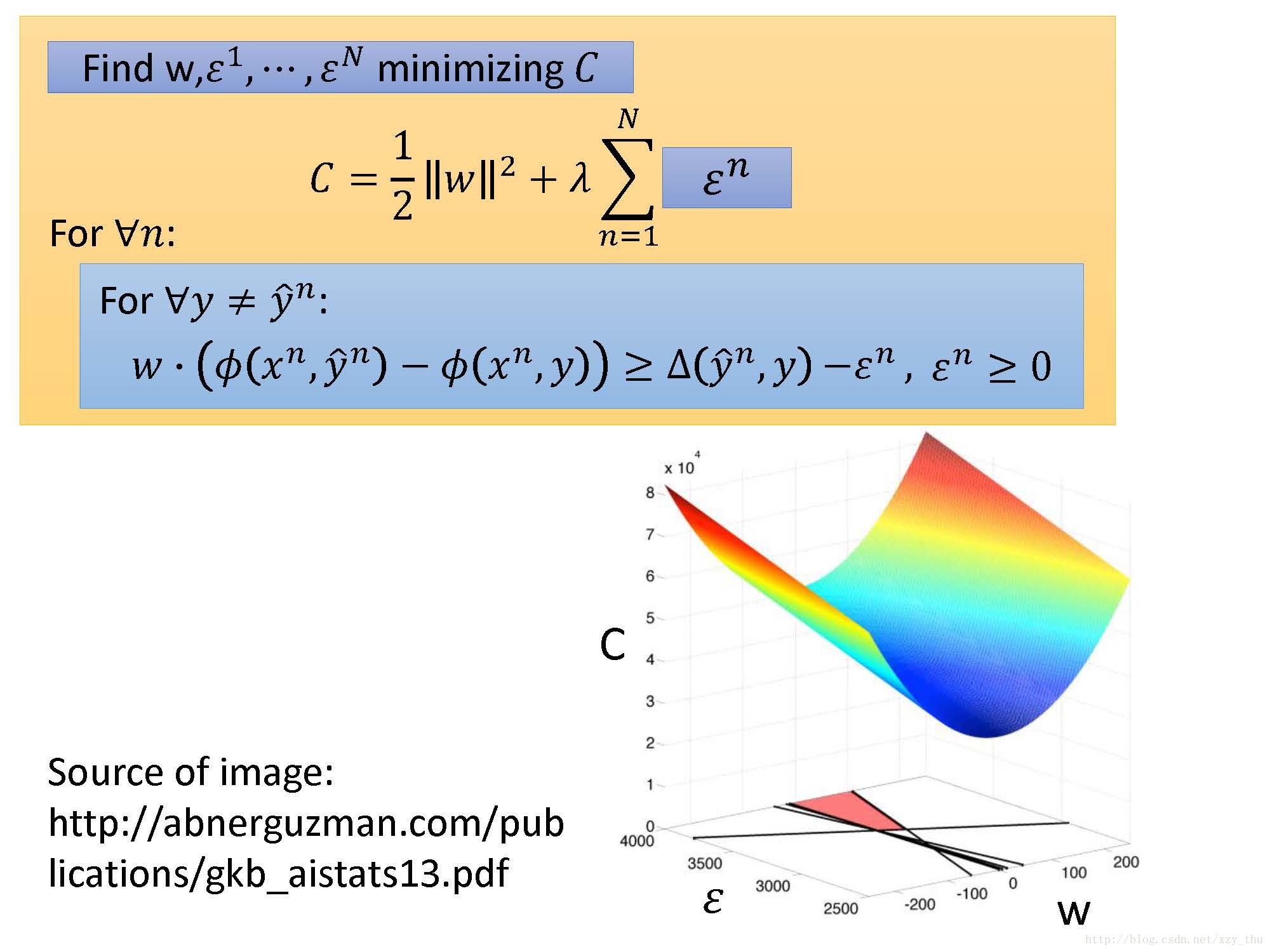
由于施加约束的不等式太多,如果不加松弛因子的话,可能不存在同时满足这些不等式的
因此要加入松弛因子,松弛因子显然是非负的(不然就不起“松弛”的作用了),但又希望它尽量小。
最后得到一个二次规划问题。
但是现在约束太多了……
Cutting Plane Algorithm for Structured SVM
先不管不等式约束,假设
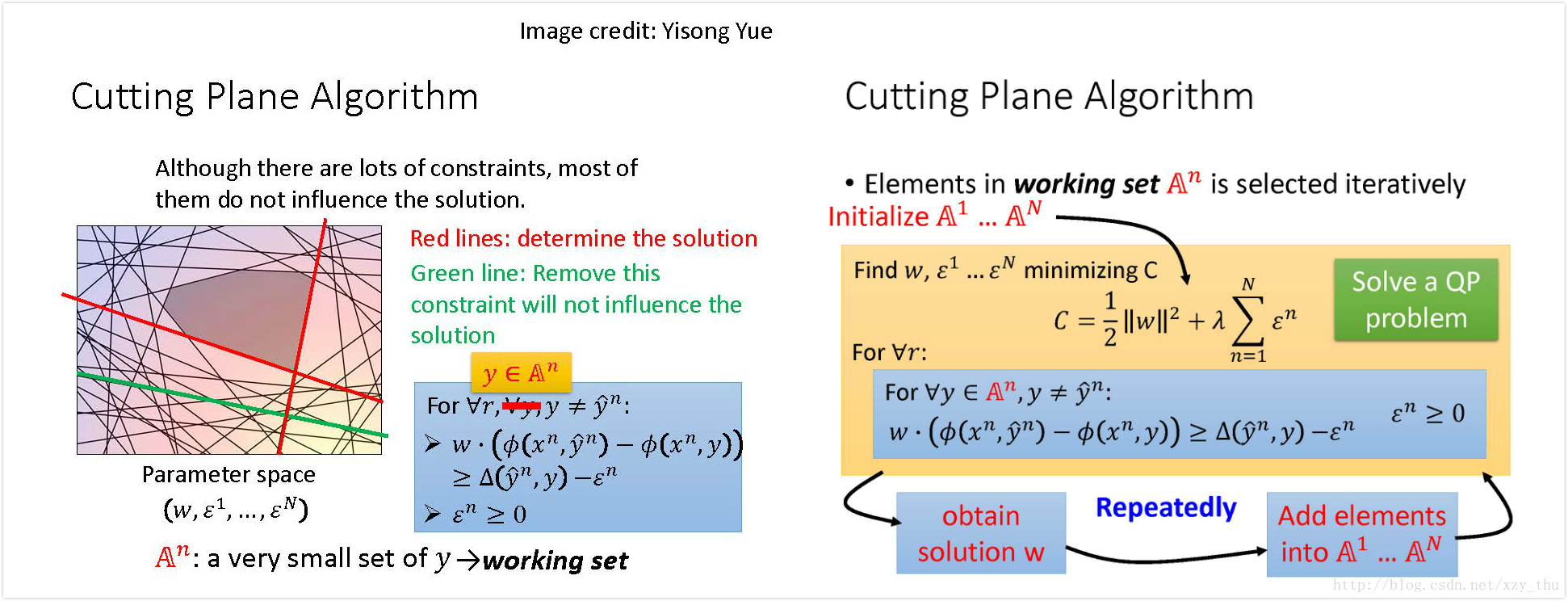
对每个example,很多个不等式约束给出了一个交集,在众多不等式约束中,只有很少的几个是起决定作用的,而其他约束是去掉之后不改变结果的。起决定作用的不等式约束所对应的y的集合,叫做working set, 每个example都有一个working set.
先初始化working set, 然后解二次规划问题(y∈working set),解得

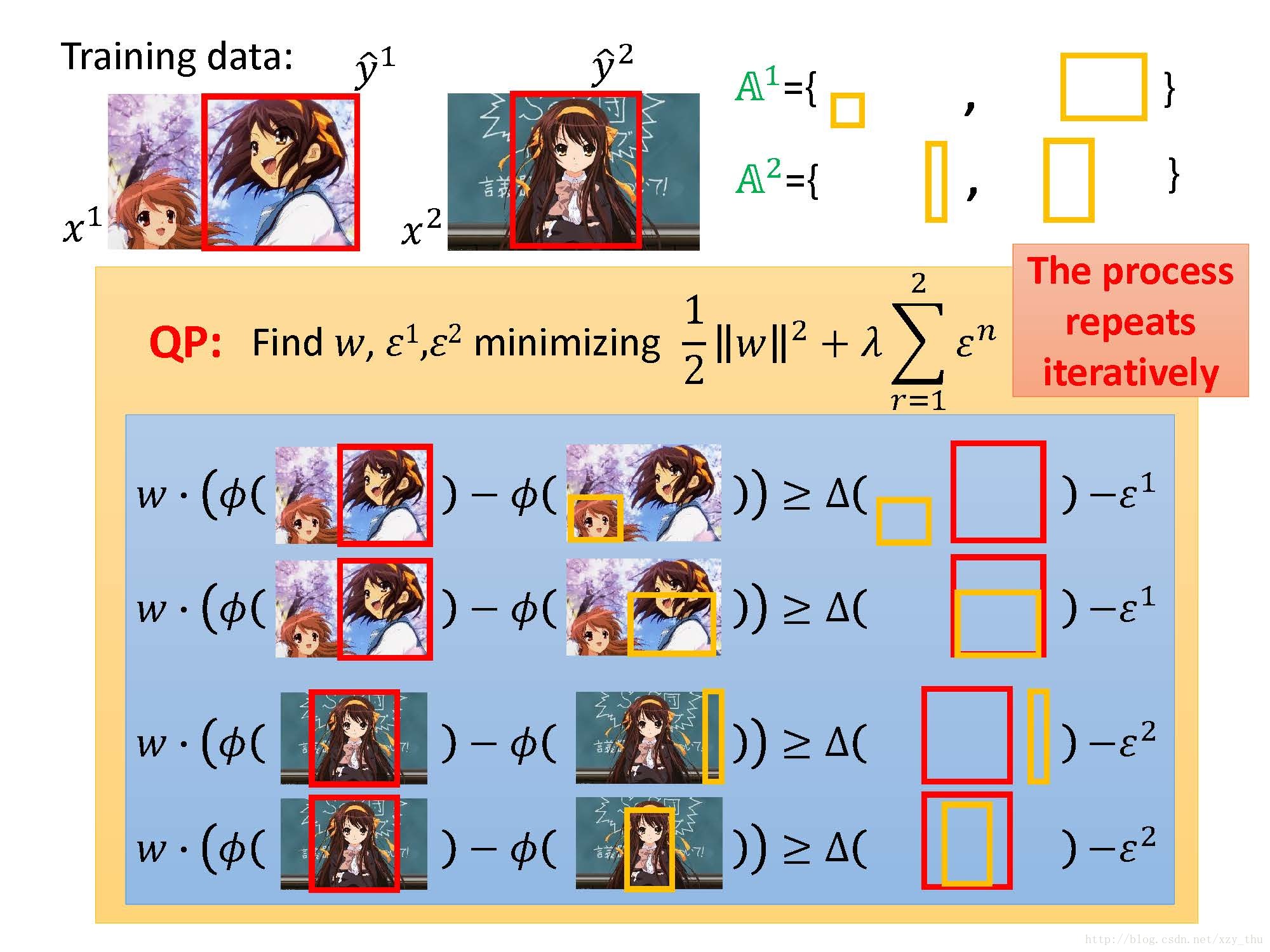
所以,Cutting Plane Algorithm for Structured SVM的过程就是:

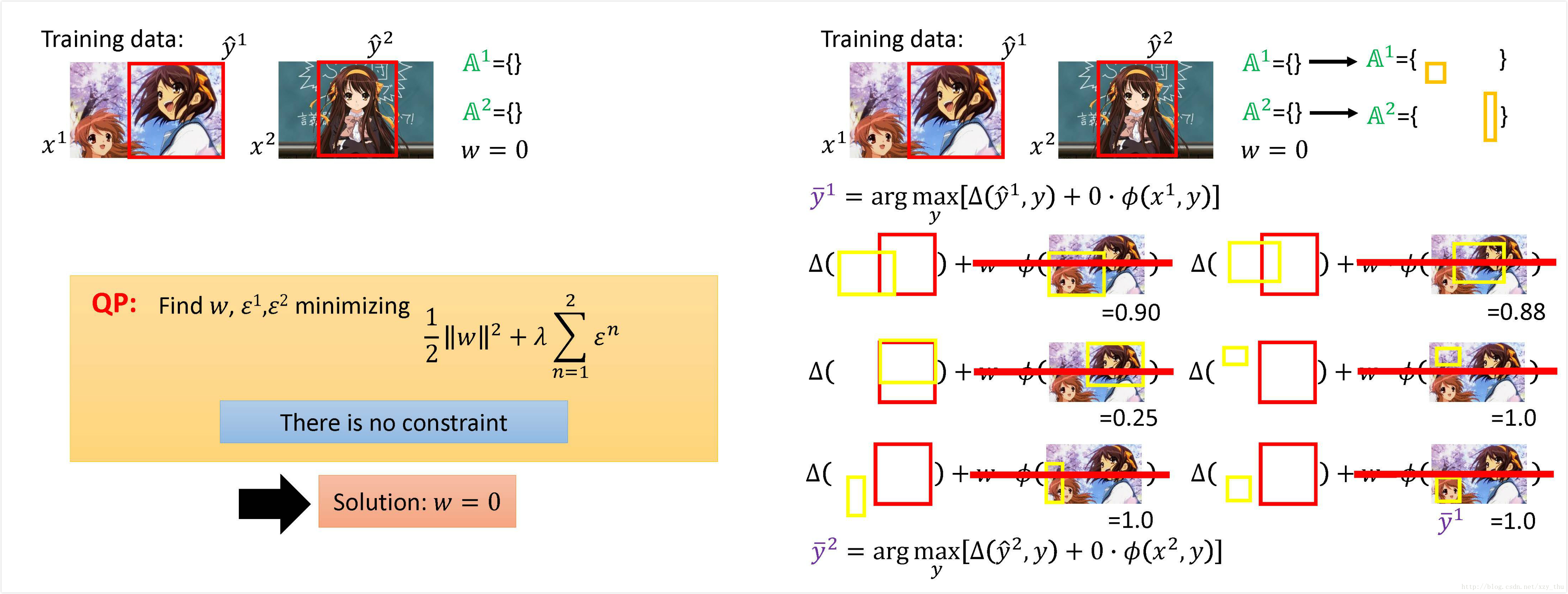
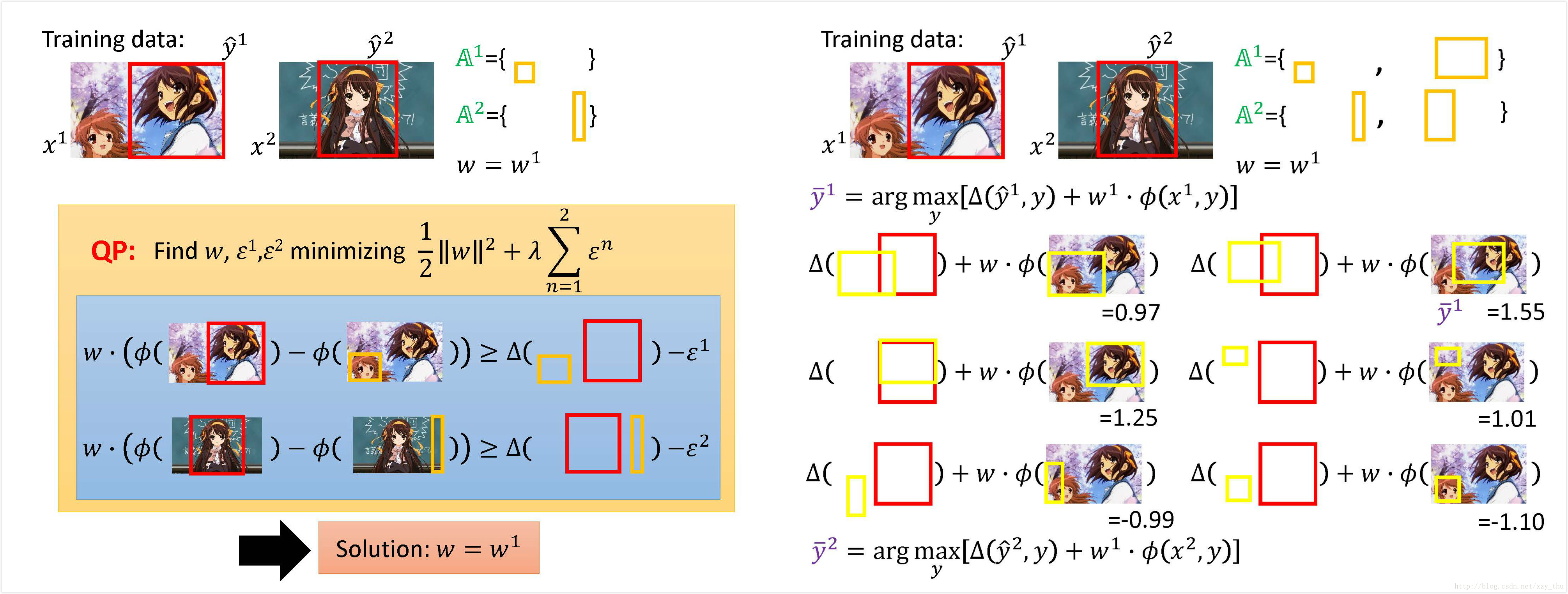
用例子形象的说明这一过程:
Multi-class and binary SVM


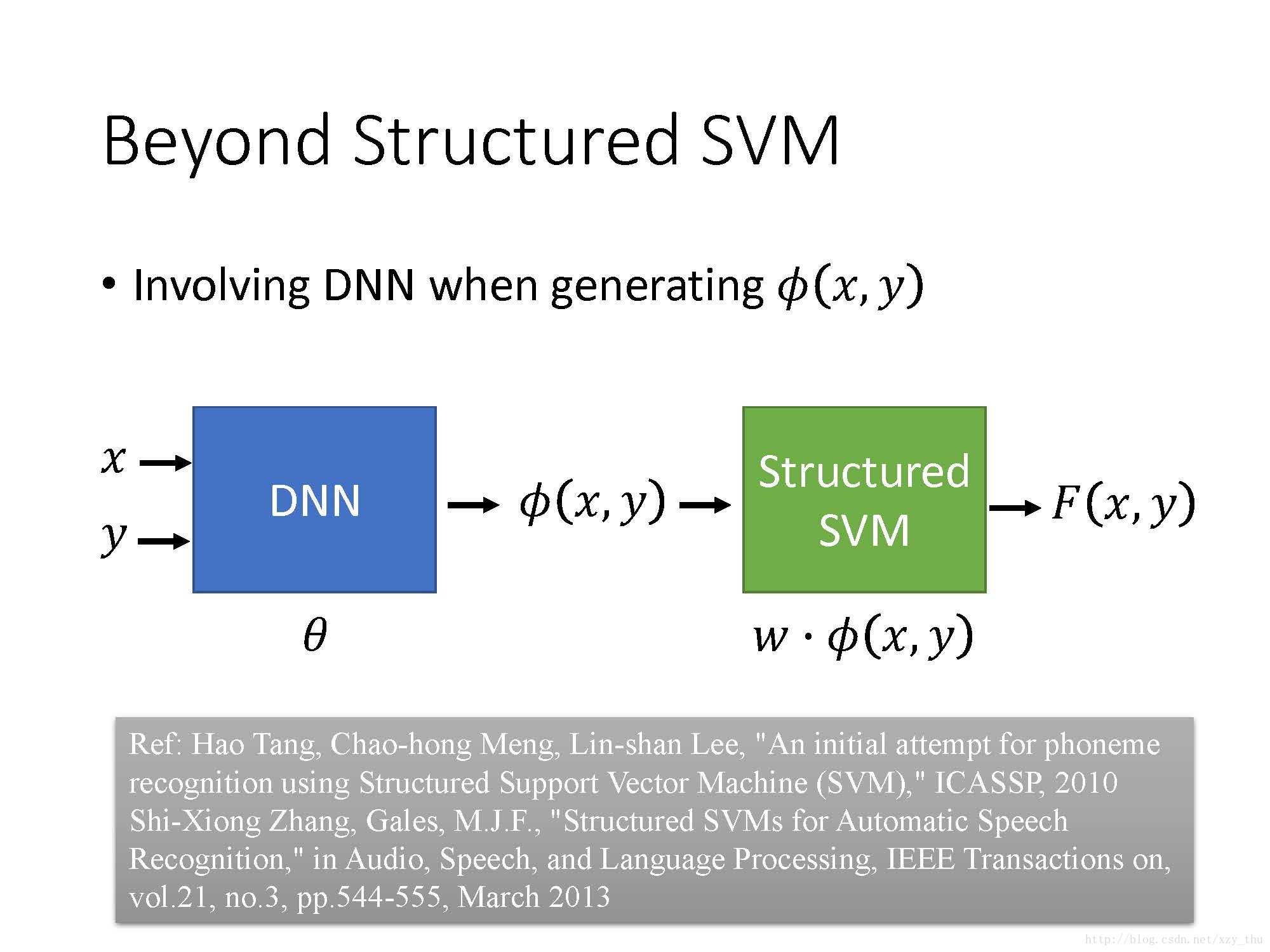
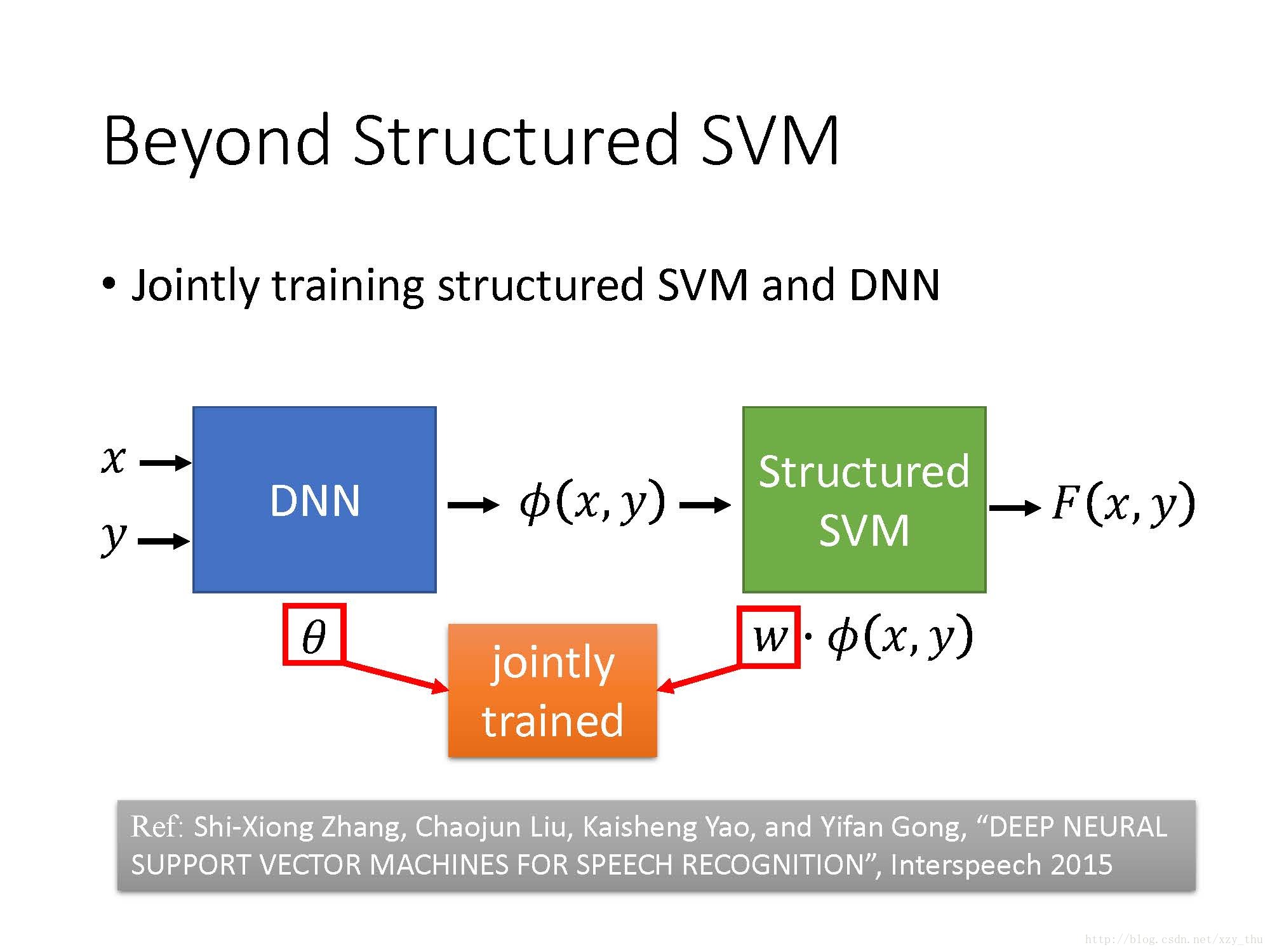
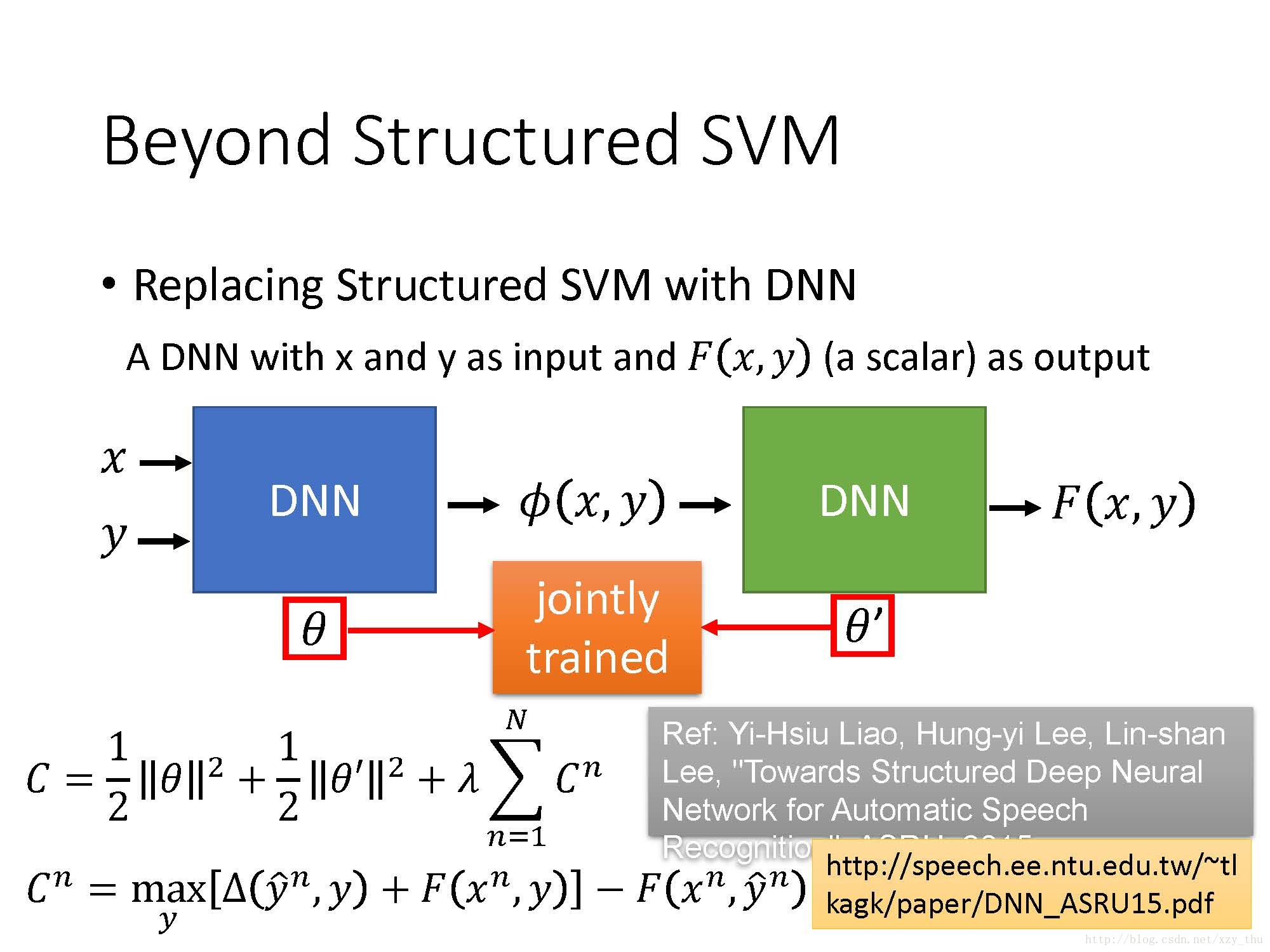
Beyond Structured SVM (open question)
Structured SVM是linear的,要让它表现很好的话需要把feature定得很好,这对人来讲较难。
Lecture 24: Structured Learning - Sequence Labeling
本讲介绍Structured Learning的一个具体问题, Sequence Labeling 。 Sequence Labeling 的输入输出都是序列,这里先假设两个序列的长度相等。RNN可以完成 Sequence Labeling 的任务,但是也有一些基于Structured Learning的方法。本讲以词性标注(POS tagging)作为Structured Learning的例子来说明问题。
本讲Outline:
Hidden Markov Model (HMM)
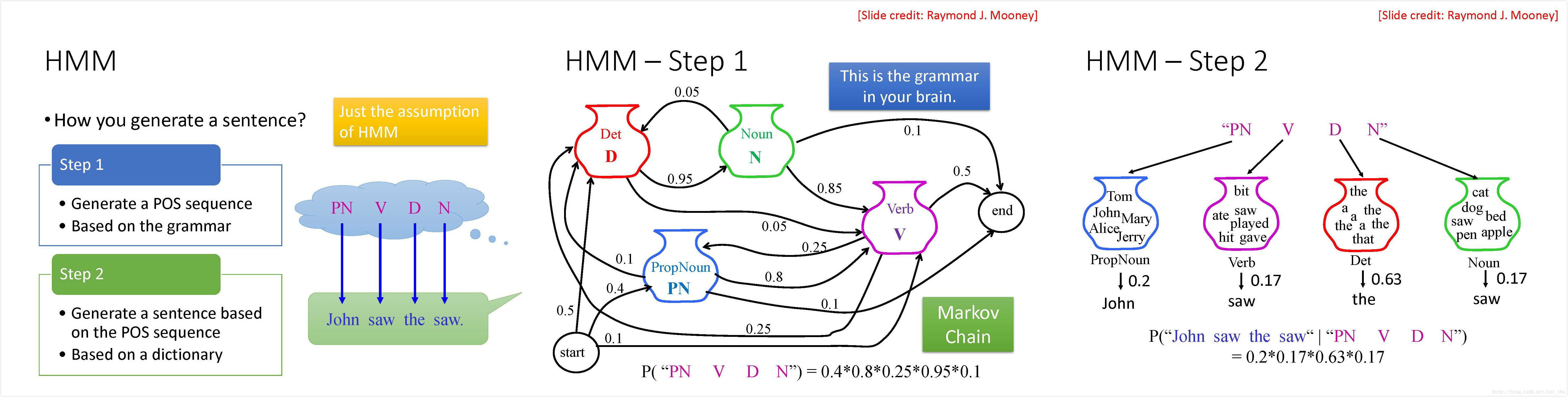
HMM假设经过如下两个步骤产生句子:根据语法,产生词性序列;根据词性序列和词典,产生句子。
语法表现为马尔科夫链的形式,可得产生词性序列的概率。从各词性集合中采样得到句子,相应的得到在给定词性序列的条件下,产生句子的条件概率。
对这两个步骤给出数学上的一般化的表达:

公式中的概率是用统计的方法得到的,而在台大数位语音处理课程中,HMM中的概率是用EM算法求的,这是因为在语音识别中有隐变量。

要做POS Tagging, 就是要根据观察到的句子

HMM也是Structured Learning的一种方法,所以也要回答三个问题。
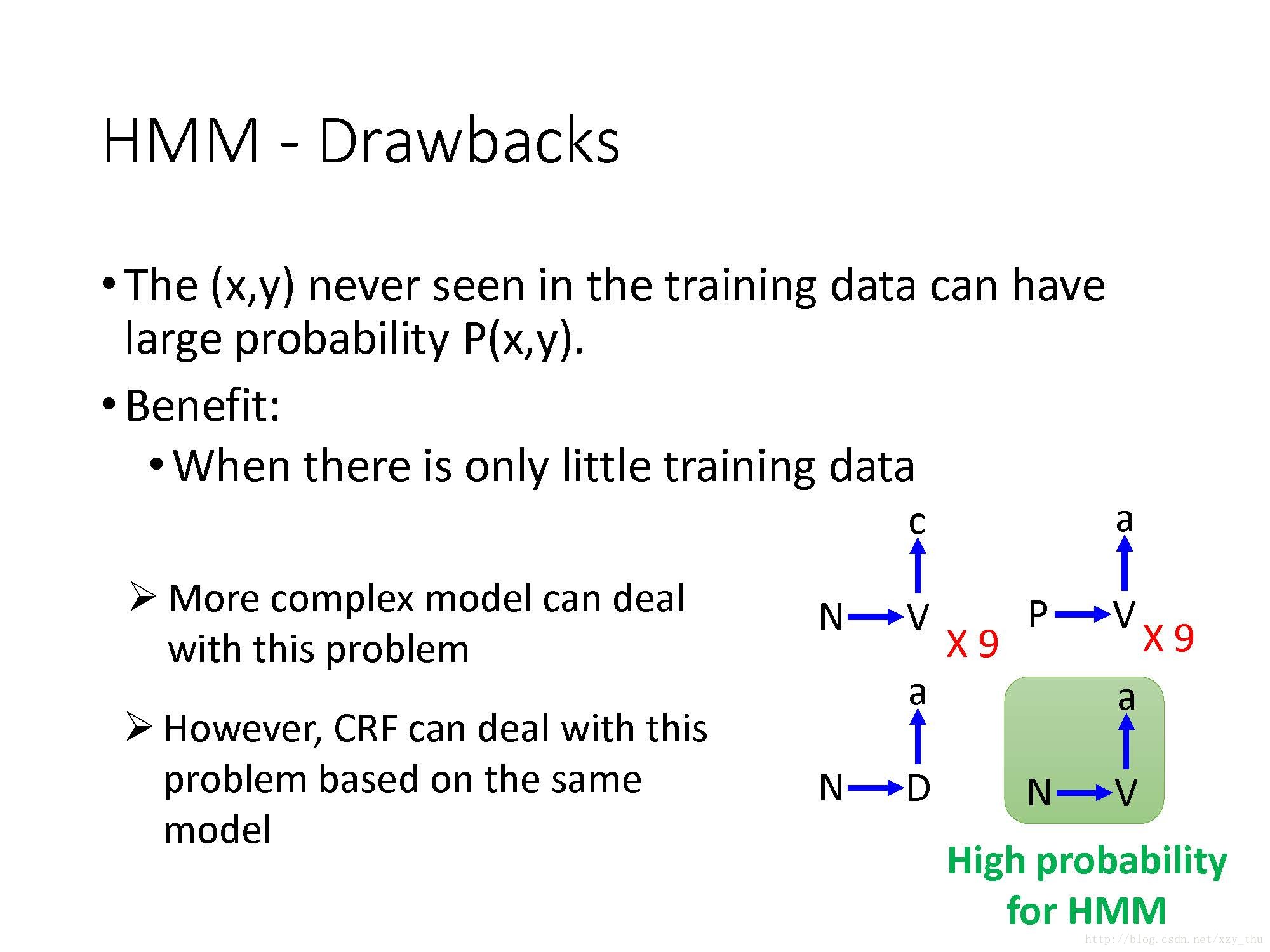
HMM存在着如下问题:
假设训练数据为
之所以HMM会脑补,是因为在HMM中假设transition probability和emission probability是独立的。
要想解决脑补问题,可以使用更复杂的模型(假设两个概率之间不是独立的)来模拟两个序列之间的概率。但模型太复杂、参数太多会有过拟合的问题。
而CRF用与HMM相同的模型(假设transition probability和emission probability是独立的),却可以解决“脑补”问题。
Conditional Random Field (CRF)
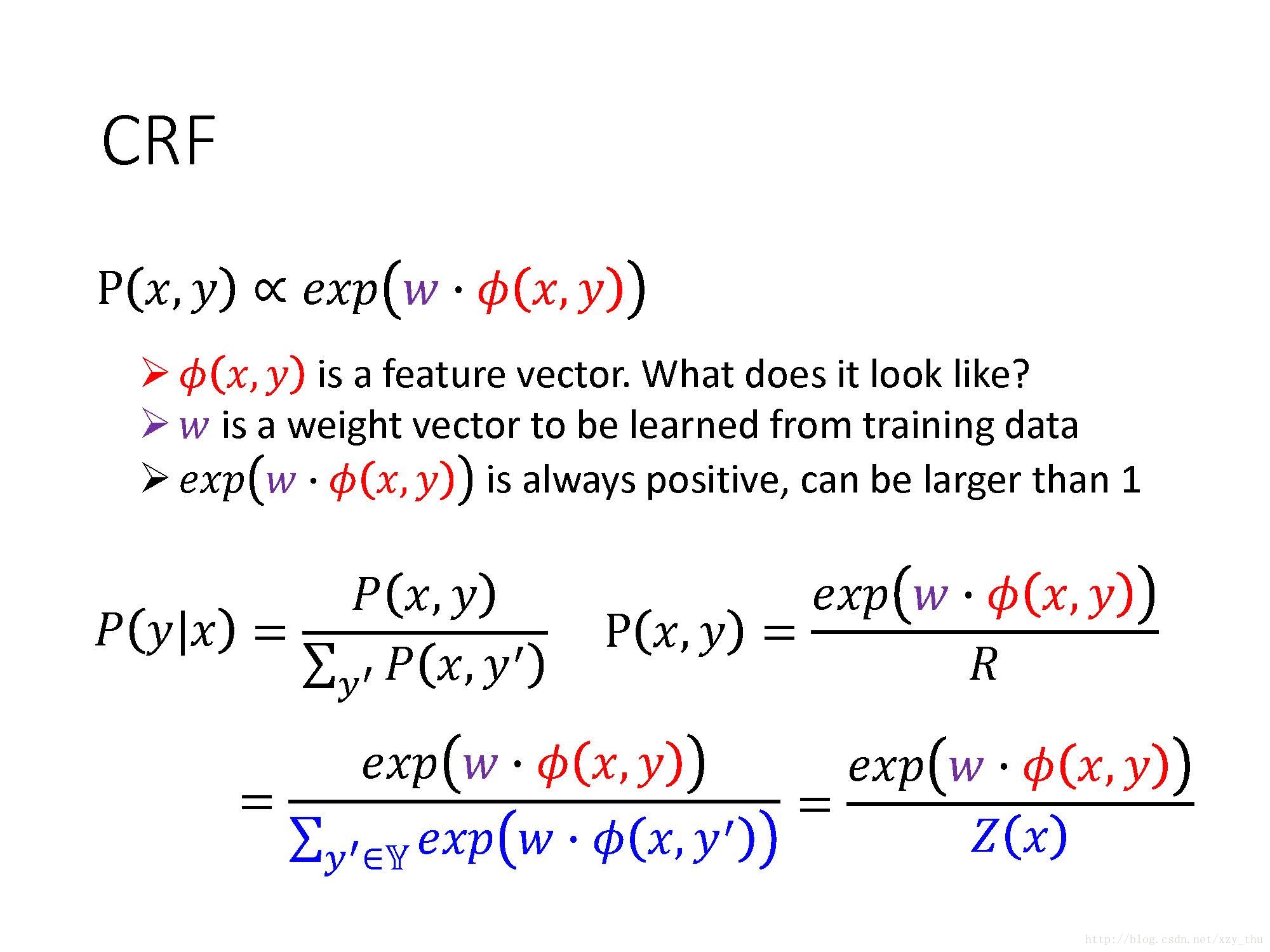
CRF不在意
CRF与HMM的model其实是一样的,只是在training的时候不同。

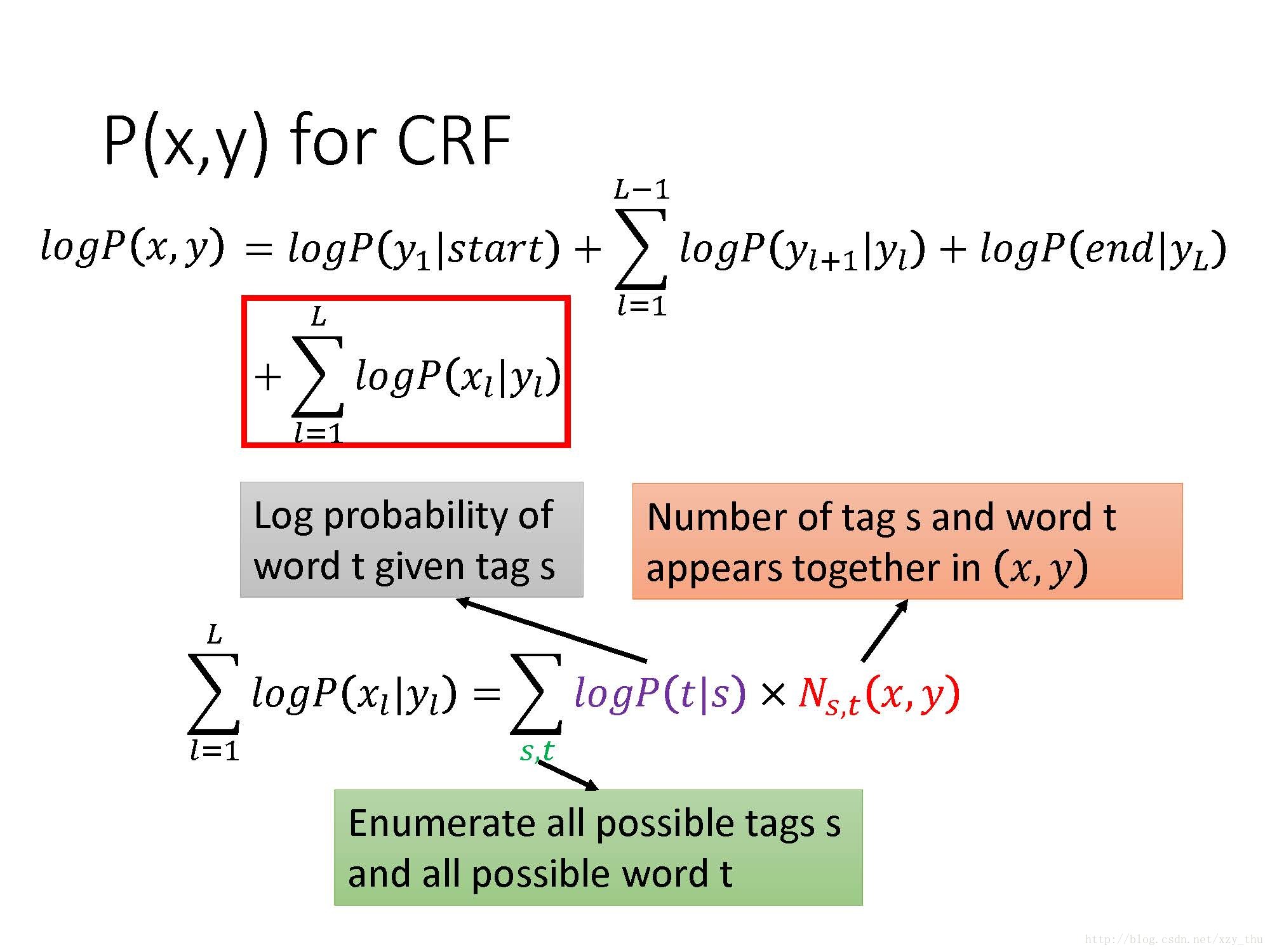

这样,得到

CRF里的feature vector
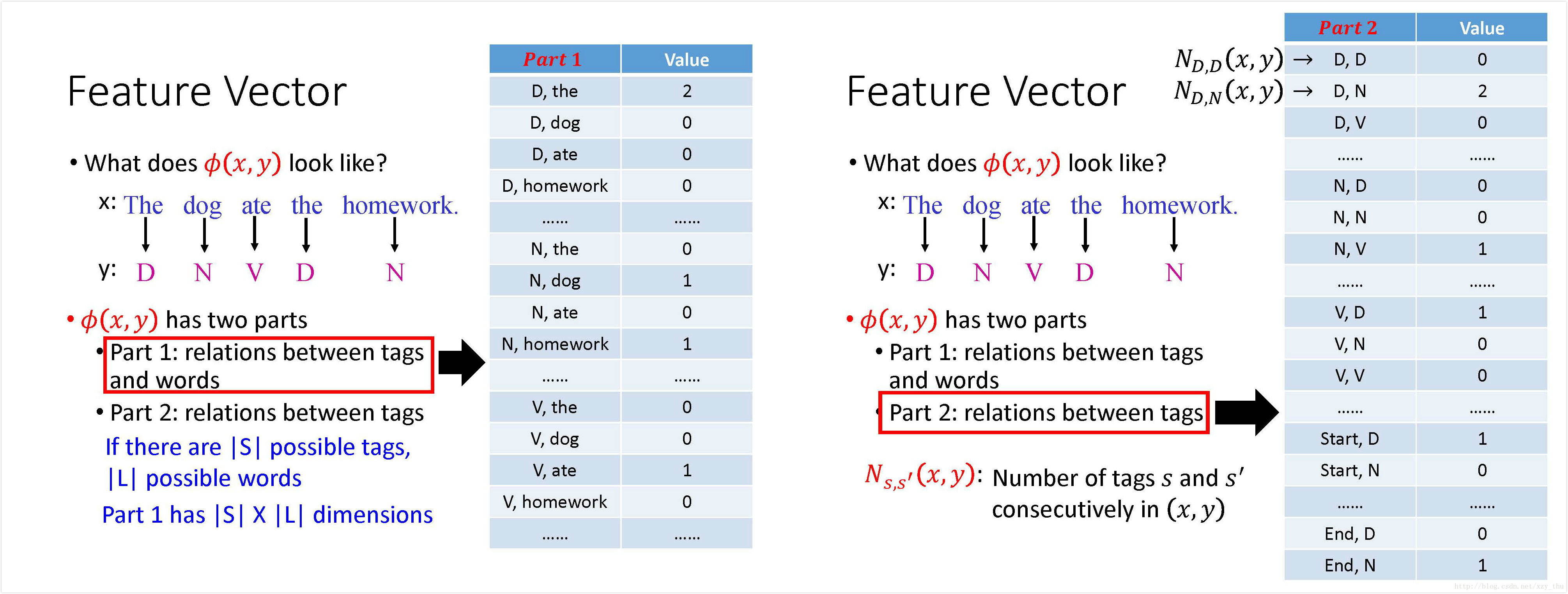
CRF的training

根据训练数据,定义目标函数(给定

经过数学计算,每一笔
得到随机梯度上升的参数更新公式,求出
CRF的Inference

CRF v.s. HMM

HMM给出的结果V直接是从统计来的,而CRF完全不care这些统计数据(N接V几次,从V产生c几次),CRF只是调参数使正确的(x,y) pair的分数高,可能调来调去就会把
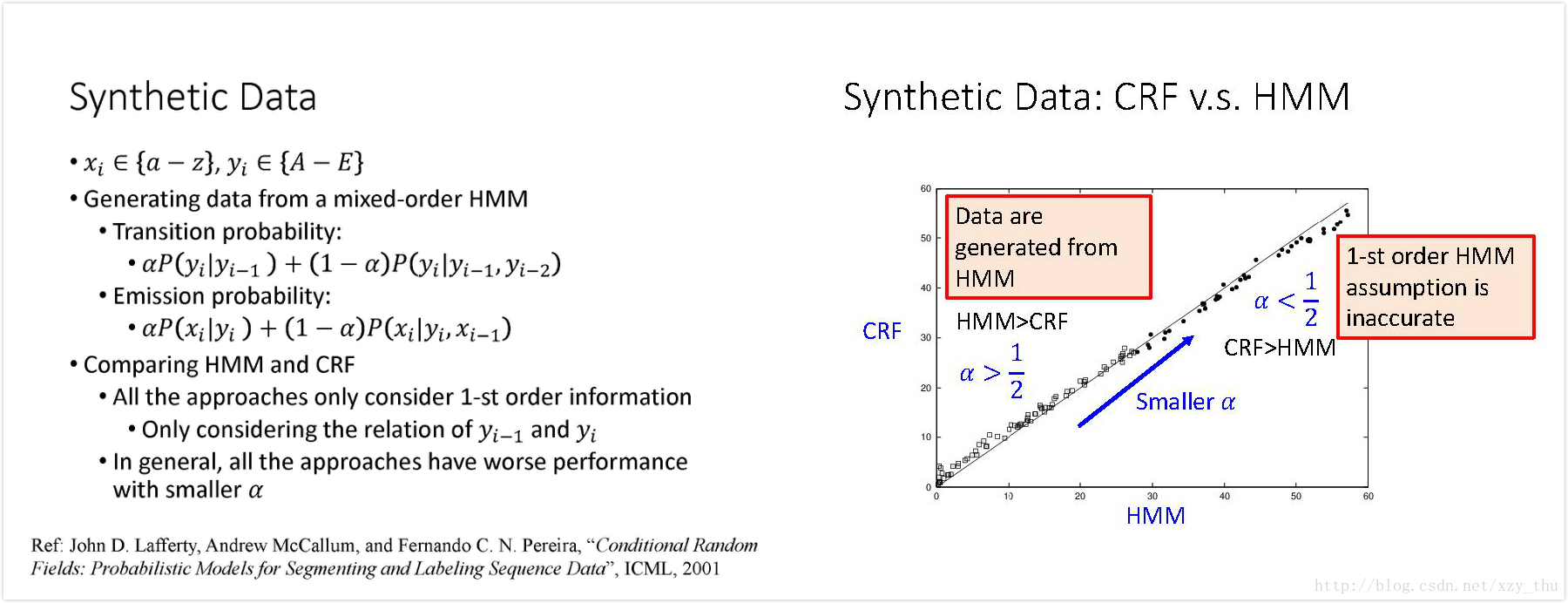
在提出CRF的论文里的实验:数据由mixed-order HMM产生,看HMM和CRF哪个对数据fit得更好。右图横轴表示HMM的错误率,纵轴表示CRF的错误率。在
Summary
CRF也是Structured Learning的一种方法,它也解决了三个问题。
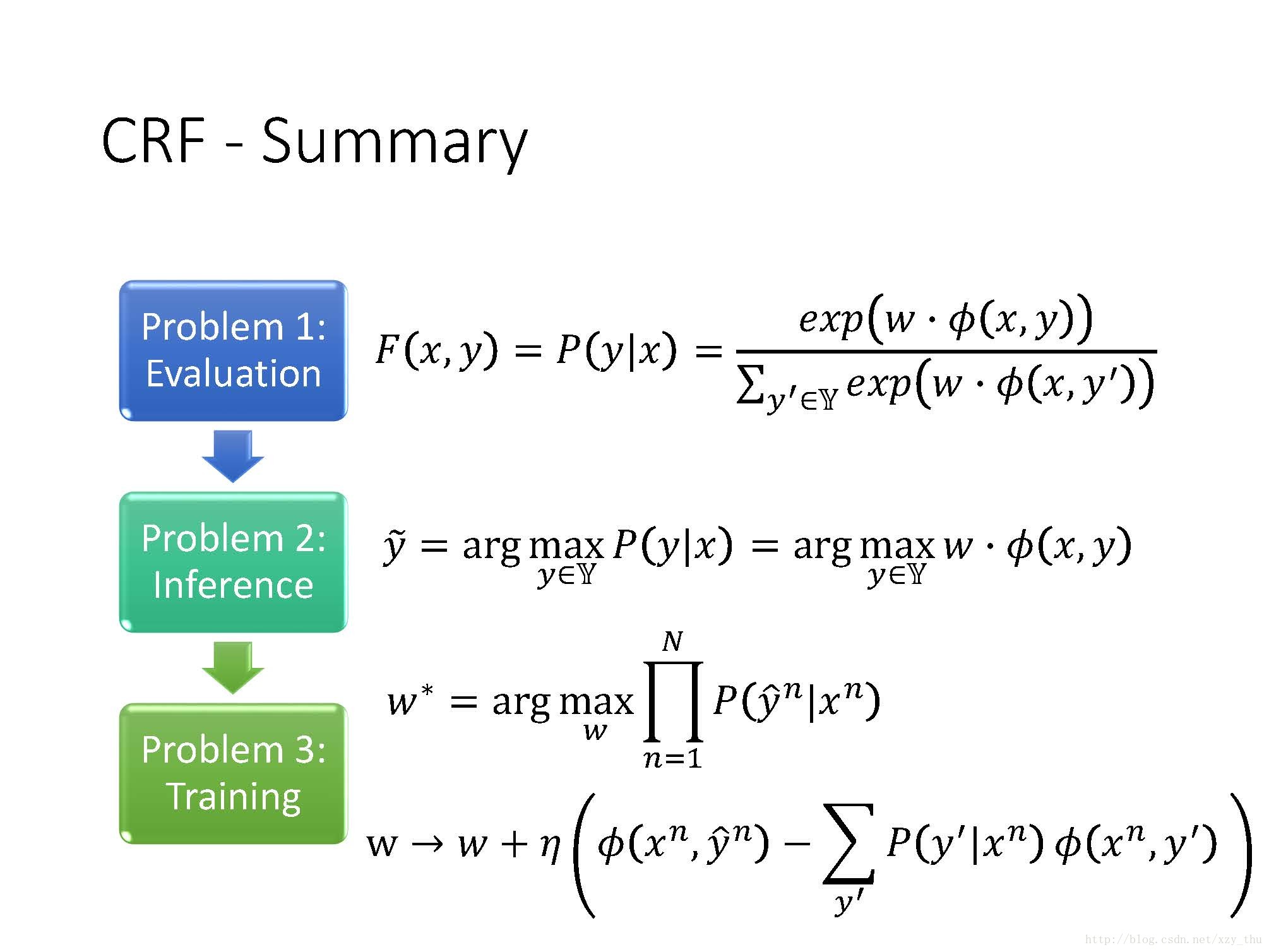
Structured Perceptron/SVM
这部分讲Structured Perceptron/SVM 怎么用在Sequence Labeling上面。
Structured Perceptron是Structured Learning的一种方法,它也解决了三个问题。
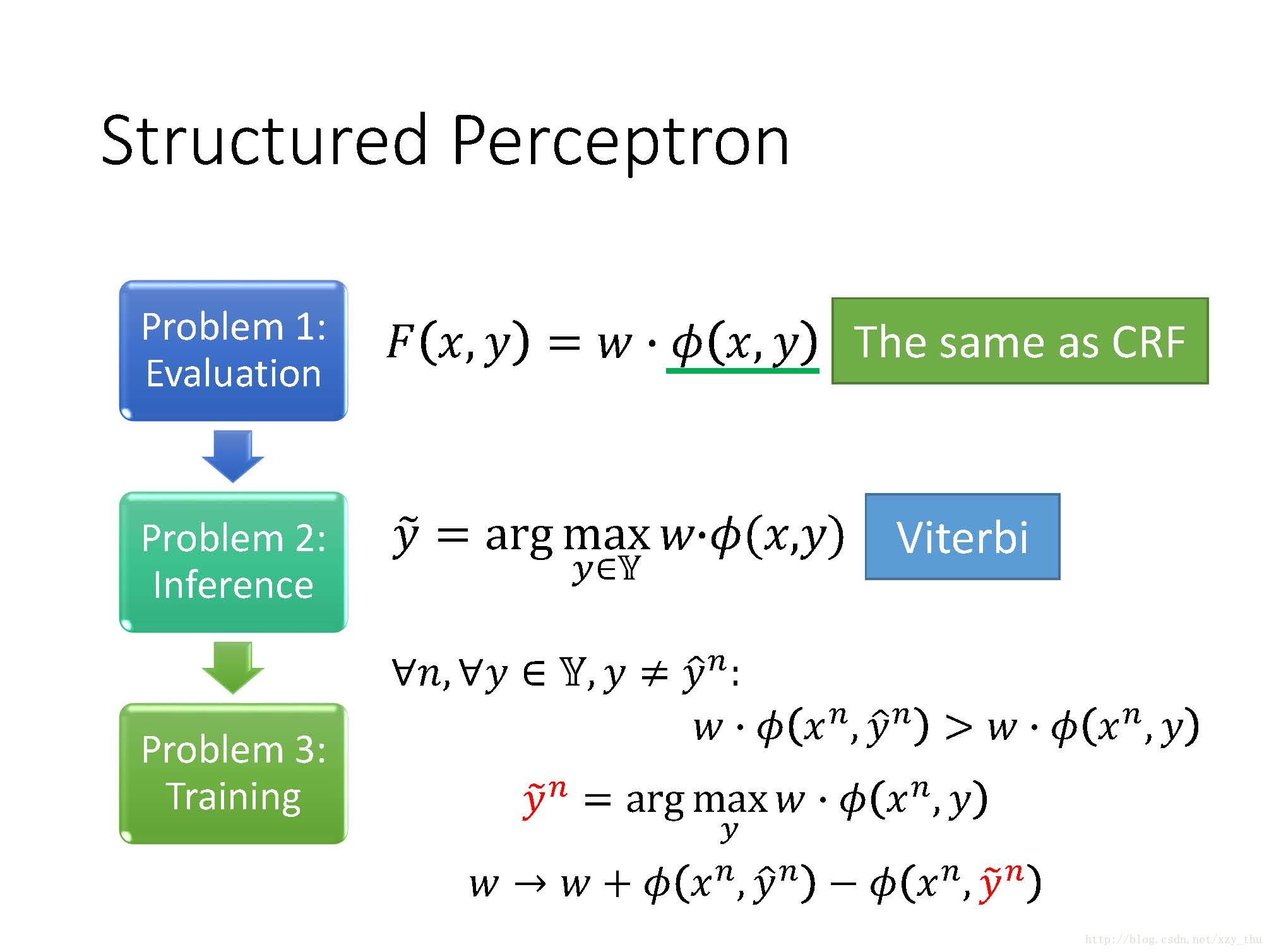
在Sequence Labeling上,Structured Perceptron与CRF十分相似,只是在training的时候有一点区别:
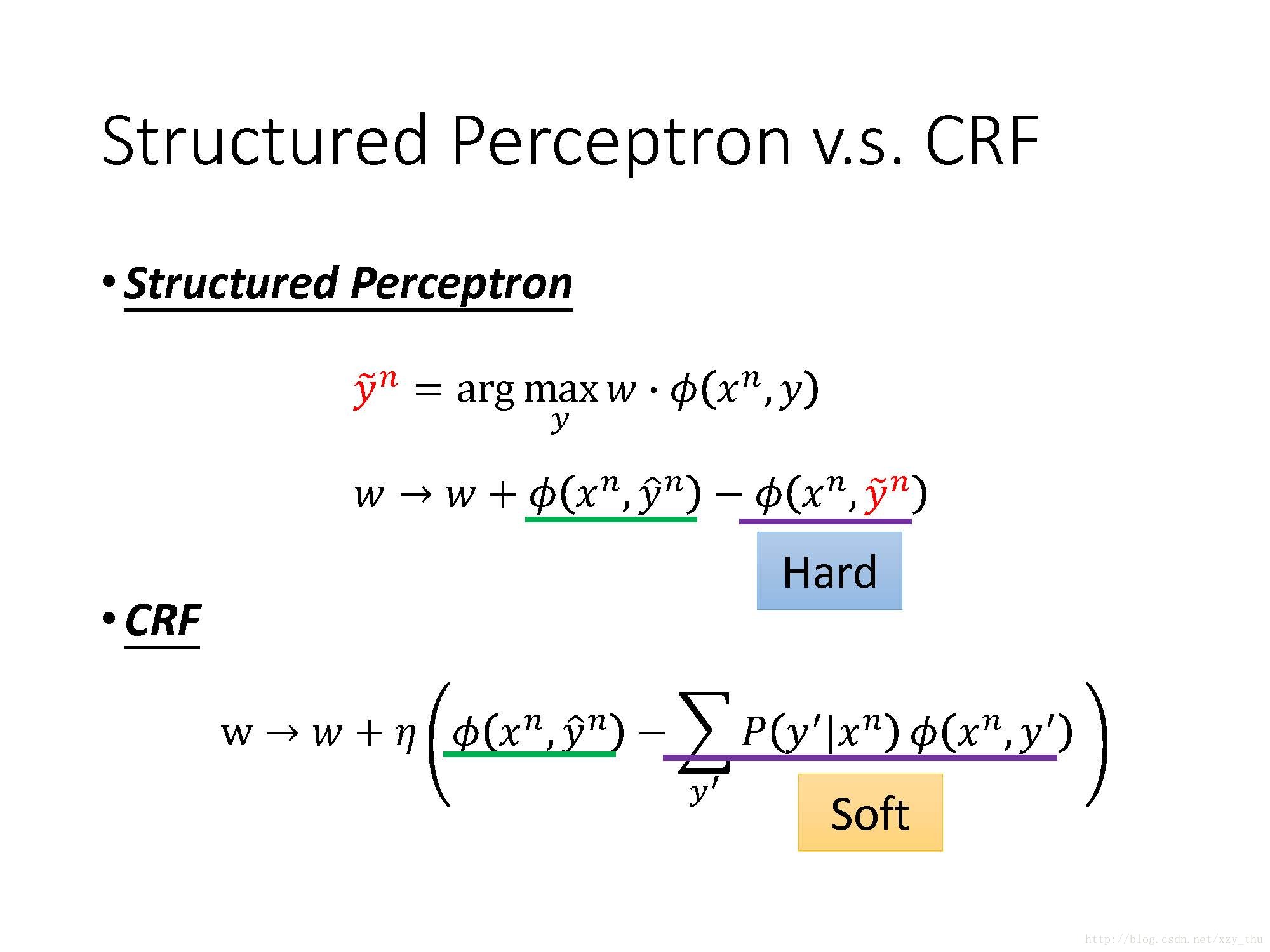
Structured SVM的Problem 1,2 都与Structured Perceptron相同,在training时加上了margin的概念和error的概念。

Towards Deep Learning
为什么不用RNN?

Sequence Labeling的问题,可以用RNN或LSTM来解,也可以用HMM, CRF, Structured Perceptron/SVM 来解,用哪个比较好呢?
RNN, LSTM有一个缺点是,如果用单方向的RNN, LSTM,那么在做决定时并没有看完整个sequence,即在产生时刻t的output时只考虑了时刻1~t的input, 没有考虑时刻t之后的input。而HMM, CRF, Structured Perceptron/SVM 在做Inference的时候,用的是Viterbi算法,看过了整个sequence。那么用双方向的RNN, LSTM会怎样呢?不知道,没看到相关文献。
HMM, CRF, Structured Perceptron/SVM 的另一个有点是,可以明确地考虑output sequence中的label dependency(label与label之间的关系)。假设知道在output sequence中某些元素是不可能出现的,那么可以把这件事塞到Viterbi算法里面去(穷举所有sequence时只穷举符合constrain的sequence)。如果RNN, LSTM有足够多的训练数据的话,或许也可以把label dependency学进来。明确的约束或许要胜过学到的。
RNN, LSTM的另一个问题是,它的cost 和 error 不见得是有关系的。而HMM, CRF, Structured Perceptron/SVM 的 cost 是 error 的 upper bound,cost减小的时候error很可能也会跟着减小,train的时候更安心。
不过,RNN, LSTM的无可比拟的优点是,它可以Deep。
综合来看,RNN, LSTM要胜过HMM, CRF, Structured Perceptron/SVM。
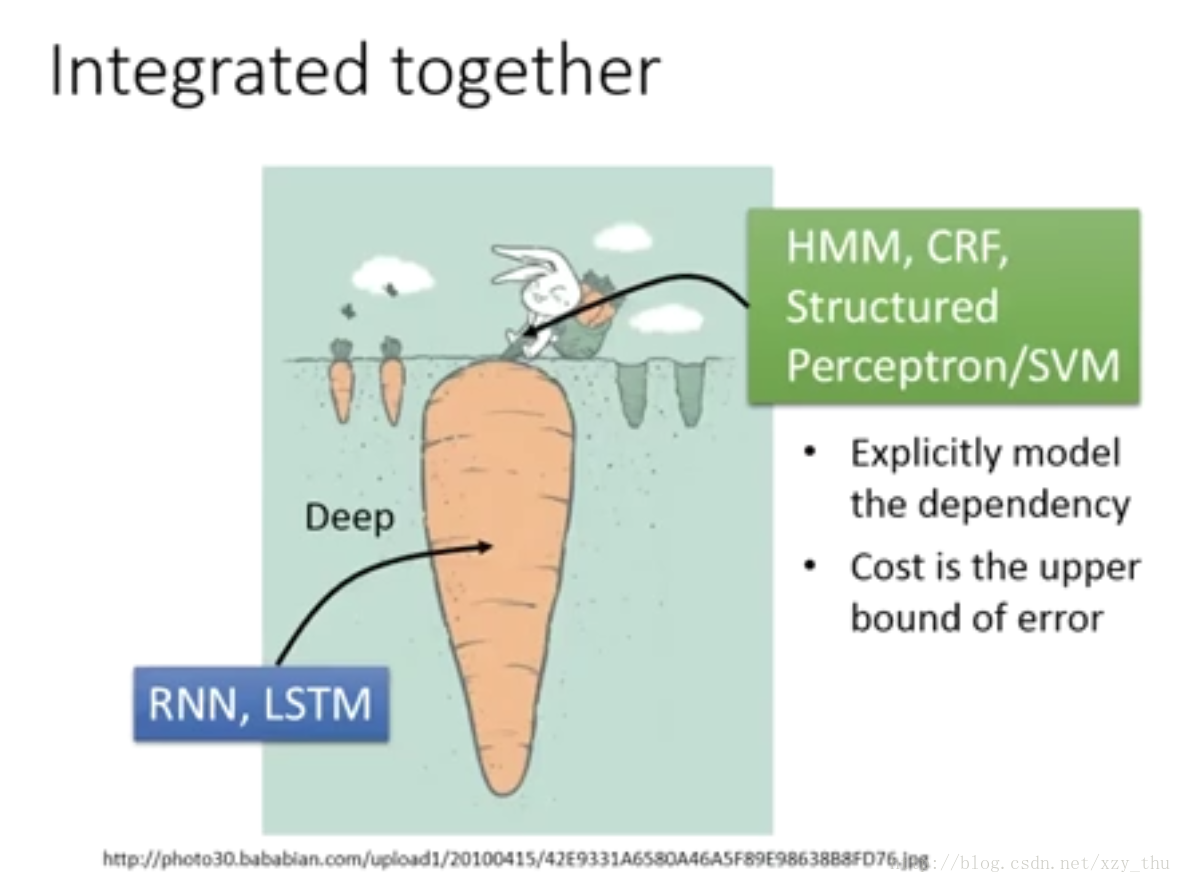
不过,我们可以将RNN, LSTM与 HMM, CRF, Structured Perceptron/SVM 结合起来:model的底层是RNN, LSTM(deep),后面接HMM, CRF, Structured Perceptron/SVM (明确描述label dependency, cost 是 error 的upper bound)
结合的例子:
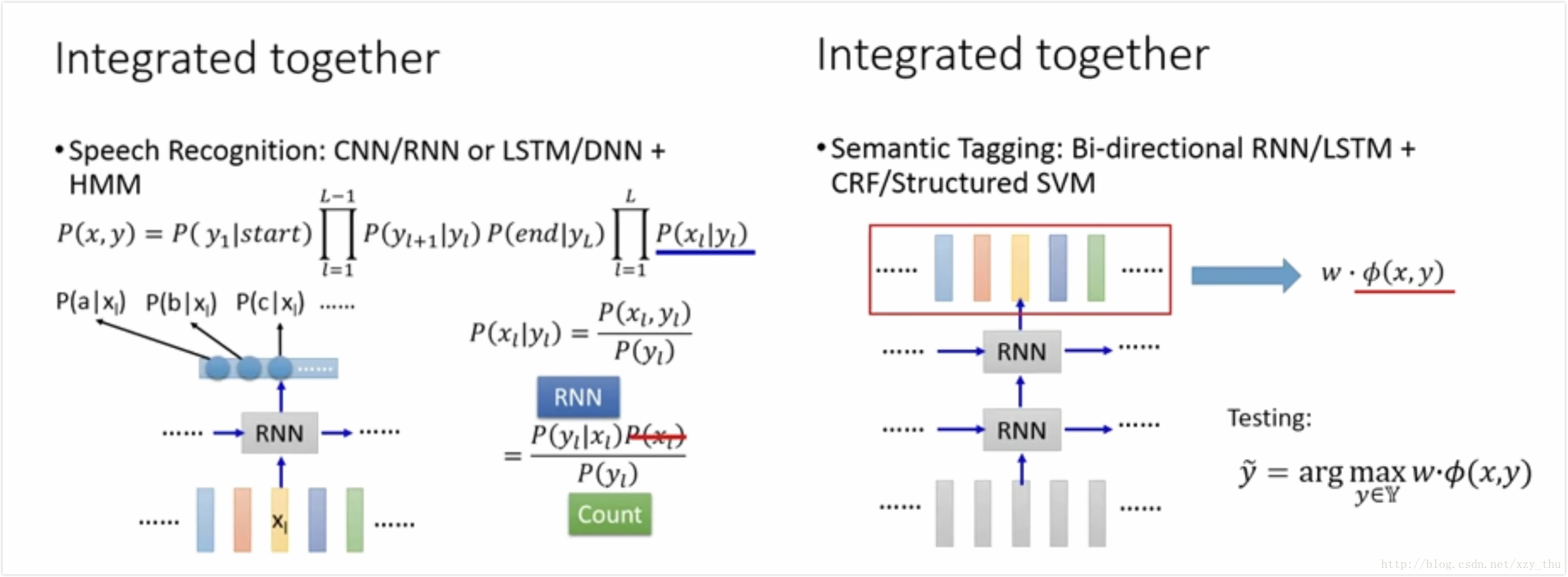
右图中RNN的output作为
Concluding Remarks

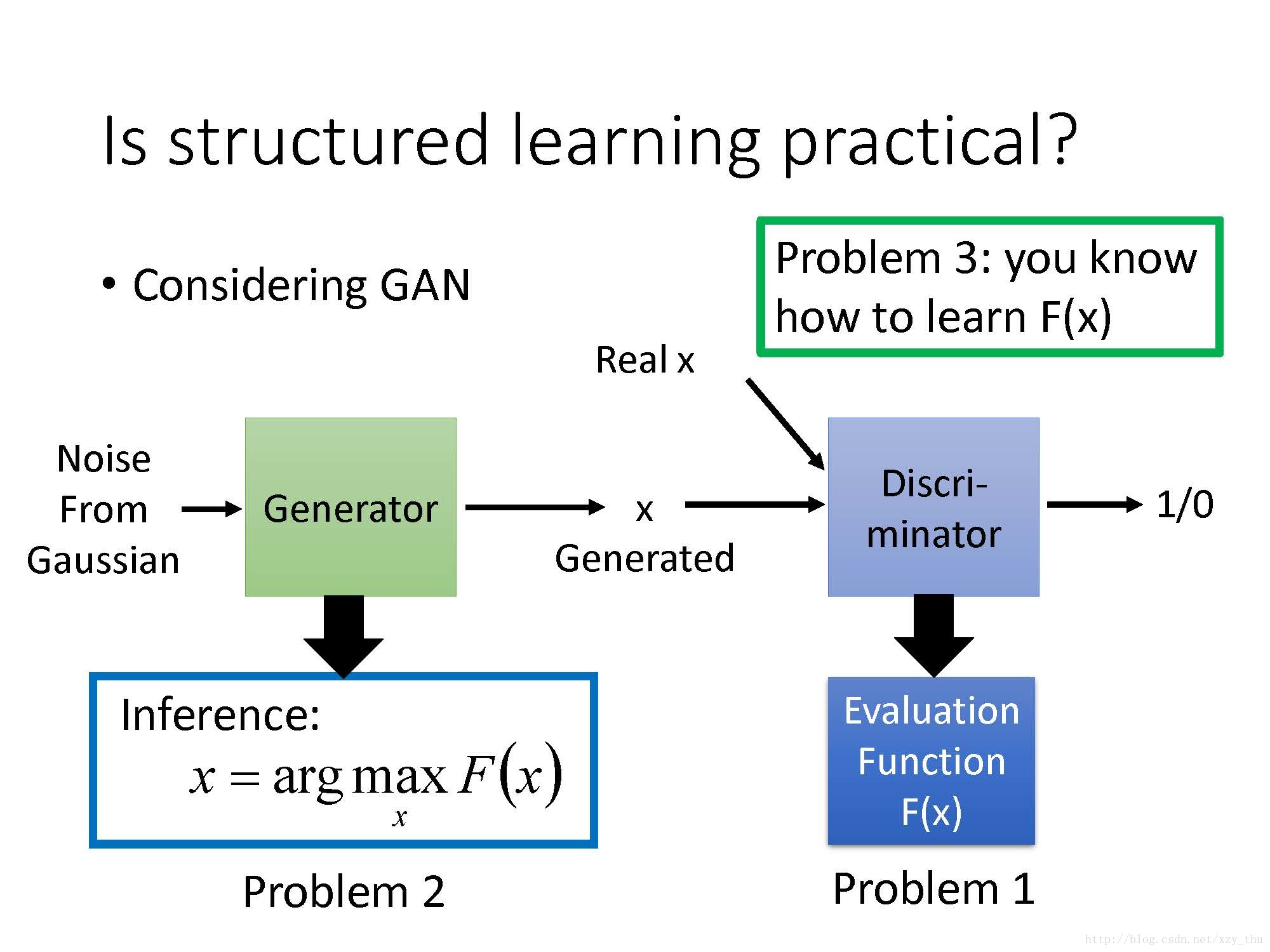
GAN与Structured SVM
GAN中的Discriminator可以看作是Evaluation Function,
GAN中的Generator可看作在解Inference问题,
怎么训练GAN,就是Problem 3的solution。
GAN的训练与Structured SVM的训练有异曲同工之妙:Structured SVM的训练中每次要找出最competitive的那些example,希望正确的example的Evaluation Function的分数大过competitive example, 然后update model,重新选择competitive example……GAN的训练类似,正确的example (Real x)让Evaluation Function (Discriminator) 最大,然后用Generator得出最competitive的x,再去训练Discriminator(对Real x给较大的值,对Generated x给较小的值),……
李宏毅机器学习课程笔记
李宏毅机器学习课程笔记1:Regression、Error、Gradient Descent
李宏毅机器学习课程笔记2:Classification、Logistic Regression、Brief Introduction of Deep Learning
李宏毅机器学习课程笔记3:Backpropagation、”Hello world” of Deep Learning、Tips for Training DNN
李宏毅机器学习课程笔记4:CNN、Why Deep、Semi-supervised
李宏毅机器学习课程笔记5:Unsupervised Learning - Linear Methods、Word Embedding、Neighbor Embedding
李宏毅机器学习课程笔记6:Unsupervised Learning - Auto-encoder、PixelRNN、VAE、GAN
李宏毅机器学习课程笔记7:Transfer Learning、SVM、Structured Learning - Introduction
李宏毅机器学习课程笔记8:Structured Learning - Linear Model、Structured SVM、Sequence Labeling
李宏毅机器学习课程笔记9:Recurrent Neural Network
李宏毅机器学习课程笔记10:Ensemble、Deep Reinforcement Learning