假设检验
一、假设概念
假设总体均值为μ,那么实际抽样的均值离μ越近意味着假设越合理,相反,实际抽样均值离μ越远意味着假设越不合理。其中,实际抽样结果与假设的差异“程度”可以用概率值表示,概率值越大意味着越无差异。在实际中往往认为设定一个P-value的阈值将差异程度判断为有差异或者无差异,这就是显著性水平。
二、假设检验基本步骤
- 提出原假设和备择假设
- 确定适当的检验统计量
- 规定显著性水平
- 计算检验统计量的值
- 做出决策
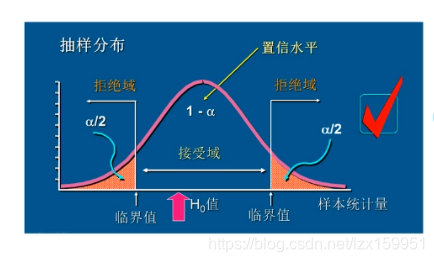
三、显著性水平与拒绝域
四、单样本t检验
- 假设样本服从t分布,原假设为总体均值等于μ0
- 备择假设为总体均值不等于μ0
- 先计算样本均值x,样本标准差σ
- 检验统计量如下为t = (x-μ0)/(σ/√n)
- 根据计算出来的P值来判断是否拒绝原假设,例如P值大于原显著水平,则无法拒绝原假设,否则拒绝原假设,接受备择假设。显著性水平可以理解为拒绝原假设的概率。这里以0.05作为判断标准,若p值大于0.05 则表示接受原假设,否则拒绝原假设。
代码实战:
import pandas as pd
import statsmodels.api as sm
#单样本t检验
tips = pd.read_csv('tips.csv')
print(tips['tip'].mean())#输出该组数的均值
dl = sm.stats.DescrStatsW(tips['tip']) #首先定义要描述的组数据
lenth = len(tips['tip'])
result = dl.ttest_mean(3)#参数为假设的样本值
print(result,lenth)
结果:
2.99827868852459 #计算的均值
(-0.01943264142291187, 0.9845119176410584, 243.0)
结果1 为t值,结果2为p值,结果3为数据长度-1
从结果中我们可以看到,p值大于0.05 所以,接受原假设,也就是之前咱们所填的参数 3。说明3 可以作为该数据的均值。
五、双样本t检验
- 单样本t检验是比较假设的总体平均数与样本平均数的差异是否显著
- 双样本t检验是比较两个样本的均值的差异是否显著
- 在数据分析中,双阳本t检验往往用于检验某二分类变量区分下的连续型变量是否有显著差异
- 例如,男女收入水平是否有显著差异、河南河北人均收入是否有显著差异。
双样本t检验步骤
- 假设样本服从t分布
- 计算两组样本的均值
- 进行方差齐性检验
- 若方差齐,进行方差齐的双样本检验,若不齐,进行方差不齐的双样本检验。
上代码:
#双样本t检验 检测男女获得小费的关系
tips = pd.read_csv('tips.csv')
tip_count = tips.groupby('sex').mean()['tip']
gender0 = tips[tips['sex']=='Female']['tip']#获取女性的小费数据
gender1 = tips[tips['sex']=='Male']['tip']#获取男性的小费数据
result = stats.levene(gender0,gender1)#对两组数据进行方差齐性检验
result2 = stats.ttest_ind(gender0,gender1,equal_var=True)#equal_var=True 表示方差齐,为False 方差不齐
print(result)
print(result2)
结果:
LeveneResult(statistic=1.9909710178779405, pvalue=0.1595236359896614) #这个pvalue>0.05表示两个方差齐
Ttest_indResult(statistic=-1.3878597054212687, pvalue=0.16645623503456763)#这个pvalue>0.05表示两个变量没有明显差异。
也就说明男女所获得的小费并无明显的差异,也就是获得小费与性别没有明显关系。
