首先声明,虽是原创文章,但是站在了巨人的肩膀上进行创作的,借鉴了车哥AI蜗牛车的一些总结,加上了自己的补充和整理完成。
1. 写在前面
今天分享的这篇论文是nips2015年上的一篇paper, 也是论文阅读系列第一篇文章,这篇文章估计现在看起来有点老了吧,但是它里面提出了一种非常重要的结构:Convolutional LSTM, 这种结构非常擅长捕捉空间关系,所以在时空序列预测研究上起到了非常关键的作用,后面的几篇时空序列预测的文章,都是基于这个结构上进行改进的,所以这一篇文章还是得好好的整理整理, 理解过程中也参考了车哥(微信公众号AI蜗牛车的作者)的思路分享,哈哈,在这里也得感谢一下车哥的关于这篇论文的总结
这篇文章的亮点如下:
- 提出了ConvLSTM网络结构: 善于捕捉空间相关性
- 提出了一种Encoding-Forecasting Structure结构:类似Encoding-Decoding Structure,把编码和预测分开,互不影响
论文下载:https://arxiv.org/pdf/1506.04214.pdf

分享大纲如下:
- PART ONE : Abstract
- PART TWO: Preliminaries
- PART THREE: The Model
- PART FROE: Experiments And Results
- PART FIVE: Conclusion
2. Abstract
在摘要方面,主要是说了三个事情:
- Prediction nowcasting
降水临近预报的目的是在较短的时间内预测局部地区未来的降水强度, 本文作者从机器学习的角度出发,把降水预报问题转换成了时空序列预测的问题。 - Extending the full connected LSTM
在全连接的LSTM的基础上提出了卷积LSTM(ConvLSTM)结构,并利用它建立了降水临近预报问题的端到端(Encoding-Forecasting Structure)可训练模型。 - Experiments
基于上面提出的模型,在移动的数字数据集和雷达回波数据集上做了实验,验结果表明,ConvLSTM能够较好地捕获时空相关性,并始终优于当前先进的算法。
3. Preliminaries
3.1 降水预报问题的阐述
在这一块,作者主要在讲这个问题到底本质上是什么问题,或者说这个问题属于什么大类?常见的对于图片来说有识别、分类、检测等等,拿降水预报问题算什么问题呢?
在真正的应用中主要是利用雷达回波图去进行降水预报,问题大多是用以前观察得到的雷达回波图去预测将来一段时间内的雷达回波图。一般来说雷达回波图都是6min一张或者12min。在这里,作者把这个问题转成了一个时空序列预测的问题

那是怎么转换的呢?
我们知道,降水预报问题无非就是每隔一段时间搜集某块区域内的雷达回波图,然后传回来分析,根据前面的图去预测未来一段时间的降水情况。
我们还知道,图片是一个个的像素表示出来的,假设图片的大小是M * N的,我们把像素点用网格给划分开,这样,就有M * N个格子。 每一个像素点,通过一定的物理映射是可以得到该点的一些物理特征的,所以假设每一个像素点可以映射的物理特征有P个(基于这些物理量我们就可以进行预测了),那么就出现了上面公式里面的X属于MNP的三维序列了。
下面这个图片可能更好理解一些:
这里的时空序列问题,就是给定过去J个时刻采集的序列(每一个时间是一个三维张量)X-J+1, …Xt。去预测接下来的K个时刻的序列Xt+1…Xt+K。
这就说明了为什么可以利用图片直接进行时空序列预测的问题能够最终预测一个区域的降水量

还要注意一个事情,就是时空序列预测和时间序列预测是不一样的,时空序列预测的序列,会涉及到时间和空间两个维度,预测的时候,我们不仅要考虑时间,也要考虑空间。 而时间序列预测只是单纯的考虑时间维度上的特征就可以了。
3.2 全连接LSTM
在介绍ConvLSTM之前,作者首先介绍了一下之前做时间序列预测的结构模型LSTM, 这也是一种非常重要的结构,常用于处理一维的时间序列,LSTM我更愿意解释成有记忆特性的神经网络。所以,在这里先介绍一下这种结构吧。
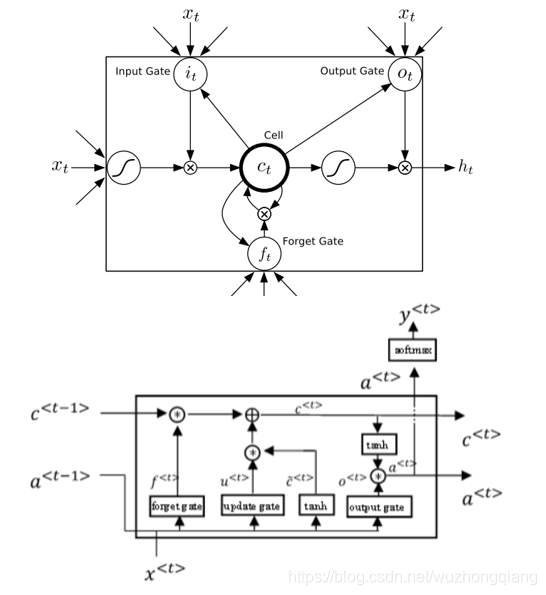
这是找到两个LSTM单元的结构图像,虽然看起来不一样,但是异曲同工。
LSTM提出的初衷就是因为循环神经网络在处理时序数据的时候(比如句子翻译这样的问题的时候)会存在一个问题就是,如果输入的句子非常的长的话,RNN在处理后面的句子时,很容易就忘了靠前的单词的特征,即RNN捕捉的当前时间步的特征,不能长时间往下传递。
所以,为了解决这样的问题,引入了LSTM的单元结构,这种结构可以采用门控单元来控制,当前时间的输入特征是否要保留下去,工作原理类似这样, 看下面的公式:
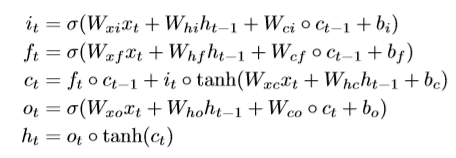
it, ft, ot分别是输入门,遗忘门和输出门,ct是一种记忆细胞,这里面要么保留当前输入的特征,要么维持前面某个时刻输入的特征往下传递。 而这个取决于输入门和输出门的打开或者关闭。 ht是当前隐藏态的值。 圆圈表示矩阵的对应位置相乘, 而Whi ht-1这种表示的矩阵乘法。
看上面的式子,如果我当前时刻的输入特征非常重要,那么我就令遗忘门为0, 输入门为1, 那么ct就把当前时刻的输入给记住了。 传到后一个时刻,我想依然保留前面时刻的那个状态,那么就令输入门为0, 遗忘门为1, 这样ct=ct-1,就保留了前面时刻的特征。 就是这么个原理,就可以把前面时刻的输入一直往后传下去。
上面简单的说了一下LSTM的工作原理。如果想了解更多的LSTM和GRU的知识,可以参考下面的车哥写的两篇文章:
多个LSTMs可以被堆叠起来,并在时间上连接起来,形成更复杂的结构。这些模型已被应用于解决许多实际的序列建模问题, 类似下面这样:
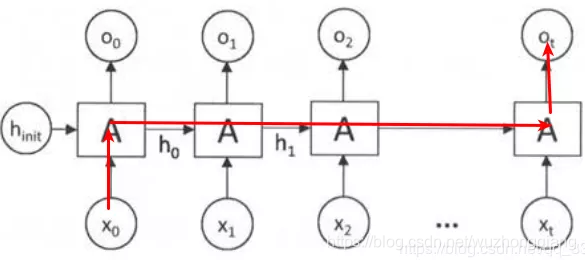
对于FC-LSTM的input是1D数据,每一个A单元是LSTM单元。
4. The Model
上面提到了多个LSTMs可以被堆叠起来,并在时间上连接起来,形成更复杂的结构。这些模型已被应用于解决许多实际的序列建模问题。 但是有一个问题就是这样的模型,对于捕捉时间特征时非常擅长的,而不擅长捕捉空间特征,即空间中的位置关系没法捕捉到,因为上面也说过,FC-LSTM 的input是1D数据,这种数据没法反应空间的状态信息。所以FC-LSTM在处理时空序列数据上表现并不是很好。
4.1 Convolutional LSTM
所以,基于上面这个问题,本文作者提出了一种新的结构ConvLSTM。
FC-LSTM 相当于在input-to-state and state-to-state 传递的时候都用的全连接,而现在采用卷积操作,全连接意味着对于整体的图像信息直接全部相乘等于一个值,这样无法对时空信息做一个提取特征的作用,而改为卷积操作, 就有一个卷积核在考虑空间区域的位置特征,并且对于卷积而言,如果卷积核大,捕捉到的偏向于更快的动作,如果卷积核偏小,捕捉到的偏向于更慢的动作。
所以公式就变成了下面这样:
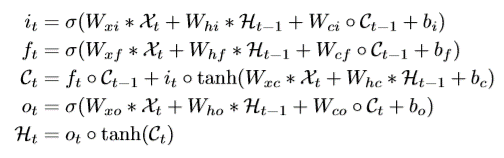
能看出和上面的区别吗? 唯一改的就是input-to-state 和state-to-state这里,把原来的矩阵乘法变成了*, 也就是卷积运算。
对比起来看一下吧:
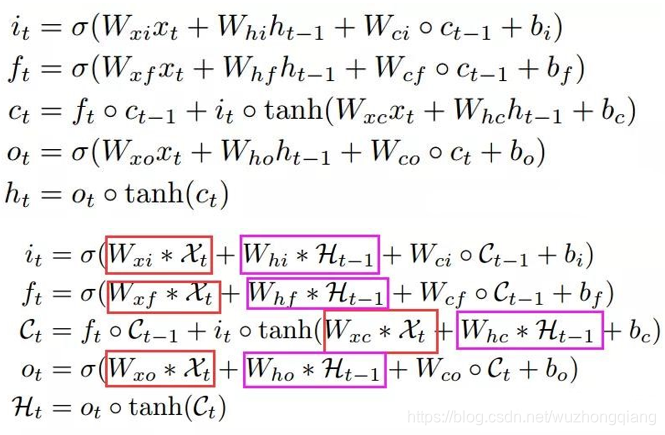
红框的就代表input-to-state, 而紫色框的就代表state-to-state。
FC-LSTM 其实就可以看成是ConVLSTM的输入和输出state以及状态h都为3D而最后两维都是1而已。
基于上面的解释,就可以看一下ConvLSTM的内部结构了:
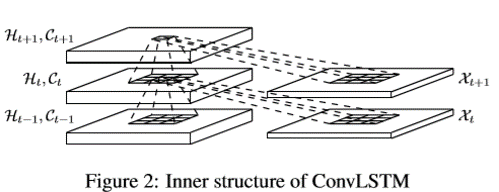
这个能看明白啥意思吗? 如果看不明白,我把它旋转一下,如果再看不明白,我把FC-LSTM的堆叠也放在一块,哈哈,原来没有对比就没有明白啊。
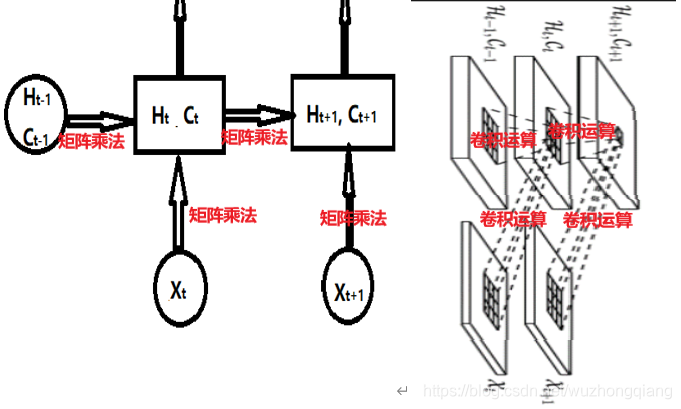
左边这个是FC-LSTM, 右边这个是ConvLSTM的内部堆叠结构,这样应该明白了吧,然后就恍然大悟: 原来ConvLSTM做的改动就是把input-to-state和state-to-state的矩阵乘法变成了卷积,输入序列也从1维的数据变成了三维的数据。 嗯嗯,其实没什么神秘的。但是这样的一个改动,就能把复杂的空间状态给考虑进去了。
最后还有一个细节就是为了保证输出的C和H 与 input X 保持一样的维度,需要做卷积中的padding操作。
这块用了一个很奇妙的想法:

文中的意思大概是 padding之后 边缘上的点可以看作是外面的点,也就是和这个事情没啥关系的点。对于zero-padding来说可以在某些时候来帮助我们一些判断,我们可以对于因为padding的点都为0,来确定边界,对于这个边界有的时候是有效的,比如我们有个墙包围的球,它肯定会来回碰撞之后来回滚,但是我们拍图片的时候序列是没有这个墙的,但是通过zero-padding相当于我们可以假设周围的边缘点就是那个墙。(其实这里就是作者来解释为啥用zero padding,神解释,哈哈)
4.2 Encoding-Forecasting Structure
这也是本文的亮点之一了,常用的端到端模型不过于常用于时间序列预测和NLP的seq2seq了里面采用的是encoding-decoding结构,这篇paper中而是采用 encoding-forcasting结构。
我们先看一下Encoding-Decoding结构:
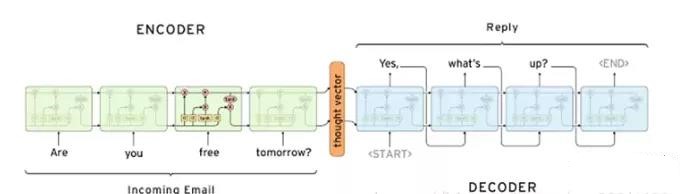
在机器翻译的时候常常会用到这种结构。
再来看一下本文中的结构:
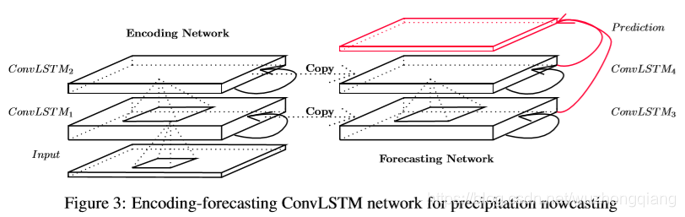
对于时空序列预测问题,作者采用了由编码网络和预测网络组成的结构。预测网络的初始状态和单元输出是从编码网络的最后状态复制而来的。这两个网络都是由若干个对流层叠加而成。由于最后的预测目标具有与输入相同的维数,所以将预测网络中的所有状态连接起来,并将其输入到一个1×1的卷积层中,从而生成最终的预测。
这个图在这里我想好好的解释解释了,可能一下子没有看懂这个图,可能会奇怪,怎么前面那个不太一样了, 好吧,我也把前面那个放这里:
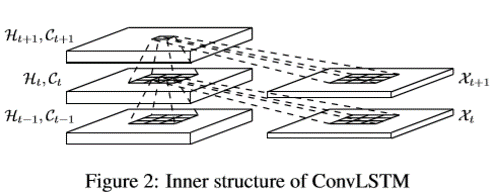
有没有感觉很奇怪了? 注意,这里要解释一下,上面这个Figure2,是一层ConvLSTM, 而上上面的Figure3是多层ConvLSTM结构进行的堆叠,有没有看到ConvLSTM1, ConvLSTM2…ConvLSTM4这些, 两者的关系就是上面的每一个ConvLSTM1…4都是下面Figure2中这样的结构。
好吧,如果还是没听懂,我再给画一下吧:
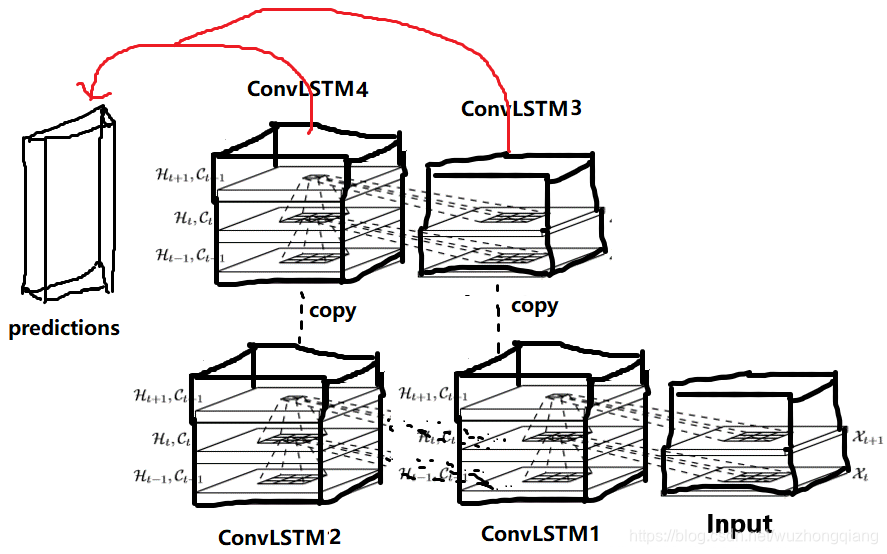
把这个图竖起来就是Figure3, 其实这里是这么个意思的。
为了保证输出维度和输入维度一致, 最后面用了一个1 * 1的卷积运算,如果我想预测多个时间步呢? 那么预测端那些的ConvLSTM就可以往上继续堆叠, 水平层上的进行1 * 1卷积之后得出某个时刻的结果,垂直方向进行堆叠,就可以预测很多个时刻。 这是forcasting端, 负责预测。
而Encoding端,只负责提取输入的时间和空间特征,然后把这些特征送到forcasting端去,只负责提取特征。 这样两个端就可以各司其职,互不干扰了。 所以这种结构还是很厉害的。
最后时空序列的预测问题就变成了下面的公式:
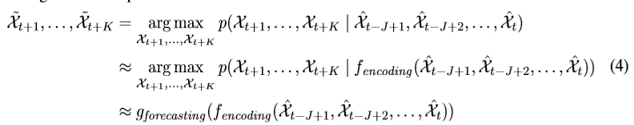
应该很好理解了,在这里就不做过多的解释了。
5. Experiments
5.1 Moving-MNIST Dataset
数据集为图中 有两个数字的时空序列的移动。

大小为64乘以64, 整个序列为20,前十个为输入数据,后十个为预测数据。也就是前十个为前十个时刻的数据,后十个为后十个时刻的数据。具体见下面的说明,很清楚,不多赘述了。

之后作者开始做了对比 所有的模型的均采用cross-entropy交叉熵作为损失函数,用的optimizer为RMSProp, 学习率为0.001并且有0.9的延迟率,并且我们在validation set上采用了 early-stopping整个操作,整体说实话训练的方式是非常传统并且正常的。这里还有个很骚的操作,作者设置一个patchsize,把64乘64的矩阵转换为16乘16乘16的tensor,这个操作我在很多代码中看到了,算是一个时空序列训练的一个小trick.
下面是最后的结果:

从结果中可以得出结论:
- 实验证明ConvLSTM网络要比FC-LSTM要好的多
- 层次越深的模型可以给出更好的结果,尽管2层和3层之间提升的不是那么明显
- 仅用1×1的卷积很难捕捉时空运动模式。
- 更大的状态到状态之间的卷积核更适合捕获时空相关性。
这里你会发现,虽然每一层ConvLSTM隐藏层的层数在变,比如第一个是一个ConvLSTM层有256个隐藏层,第二个是两个ConvLSTM层, 每一层都有128个隐藏层,第三个是3个ConvLStM层,第一层128个隐藏层,第二层和第三层都是64个隐藏层。 下面那个9*9卷积的那个类似。
发现了吗? 就是不管ConvLSTM有多少个,设置的隐藏层的最终层数都是256层,这是为什么?
这是因为我们的输入图片大小是6464的,然后转成1616*16=256的。 即我们要保证输入和输出的维度是一致的。
最后感受一下预测效果:

5.2 Radar Echo Dataset
这才是这篇paper的最大亮点,用在雷达回波图上,做一个降水预测的应用。 看下效果:
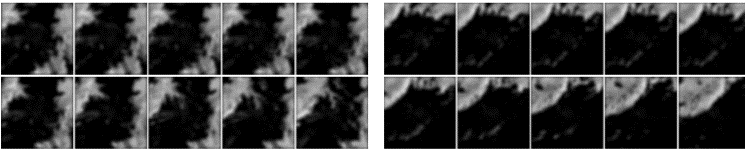
选的数据集为三年的HK的回波图,因为降水问题很特殊,不是每天降水,如果一起使用会出现啥问题呢??就是说可能百分之90都是无雨的情况,最后会出现无雨的全是黑的图片为主要的图片,那模型训练起来会出现把降水当作噪声或者负样本的情况,或者说主要的样本严重失调,很难训练出一个正常的模型,所以作者采用降水量最高的97天作为训练数据。

实验结果如下:
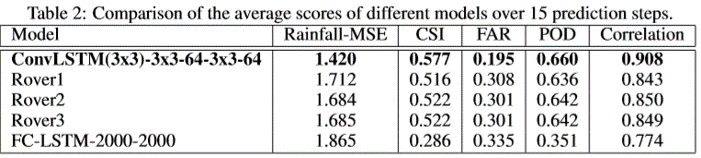
CSI FAR POD 等都是天气中的一些重要测量指标或者常用指标。类似于机器学习里面的评估指标。
CSI类似于查准率,越高越好,FAR类似于错误的占总的比例,这个越小越好,POD也是越高越好。 具体看下面定义:

首先把像素点转换成雷达回波图的雷达反射率的值,之后通过ZR变换, 转换为降水量, 之后通过阈值把整个降水量的矩阵转成0-1矩阵, 之后与label的0-1矩阵进行比较计算的这些值。

最后得出的结论:
- FC-LSTM的效果还是很差,因为雷达回波图上的强烈的空间相关性没有捕捉到,没有ConvLSTM好。
- ConvLSTM比传统的光流法OpticalFlow要好,主要是两个原因: 一个为ConvLSTM能够更好的处理边缘(out-of-domain的能力), 更泛化一些。对于降水的场景,会在边缘突然降雨等。 另外ConvLSTM的Enconding-Forcasting为端到端结构,更为便于使用。
6. 总结

总结这块就不多说了, 还是提出了ConvLSTM的结构,然后提出了Encoding-Decoding端到端的预测框架,实验表明,在移动手写数字识别和降水量预测方面,都比传统的方式要好的多。
当然,这种结构目前也已经过时了,但ConvLSTM的提出也算是时空序列预测的一个里程碑的事件了, 后面的predRNN,以及PredRNN++这些结构都是针对这个ConvLSTM做出的改进。所以先明白了这种结构,才能知道后面这种结构有什么问题? 才能更好的理解后面的那两篇文章。
关于这篇文章的理解也就这么多了,后期会努力复现这里面的这个结构,并应用于其他的任务上。
