Abstract
神经网络已经在句子和文档模型上获得巨大成就,CNN和RNN是两大方法,本论文结合了这两个网络,获得的网络叫C-LSTM,用来表示句子和文本分类。C-LSTM使用CNN抽取高级的短语表示,然后输入到LSTM获得句子表示,C-LSTM可以捕获短语的局部特征,句子的语义信息,
代码:https://github.com/zackhy/TextClassification
1 Introduction
NLP中,句子模型主要是用有意义的特征来表示句子,为情感分类服务,传统的句子模型使用BOW模型,这导致维灾难,others use composition based methods instead, e.g., an algebraic operation over semantic word vectors to produce the semantic sentence vector.
这些方法性能不太好,因为丢失了词的位置信息。
表示句子的模型分为两类:
- 基于序列的模型
- 基于树结构的模型
基于序列的模型考虑词之间的先后关系获得句子表示
基于树结构的模型把每个词作为语法分析树的节点,从叶子到根的循环特定获得句子的表示
CNN和RNN通常作为获得表示的模型
因为CNN可以抽取局部的空间或短时间的结构关系,在CV,SR和NLP获得很好的效果,对于句子模型,CNN对于抽取句子中不同位置的n-元特征具有很好的能力,并且可以通过pooling操作学习获得短范围和长范围的关系,CNN已经成功结合了基于序列和基于树结构获得句子模型,
temporal data:时序数据
spatial data:空间数据
CNN对于序列数据抽取特征能力差,而RNN却比较好,但是无法抽取特征,
本论文的模型,一层的CNN获得特征输入到LSTM里,CNN在预先训练好的数据获得高级n元模型的表示,CNN获得的特征映射重新组织为序列式窗口的特征作为LSTM的输入,我们首先转换每个连续的n元特征来避免句子的因素变化。选择序列式的输入而不是语法树作为输入,所以我们的模型不依赖外部知识和复杂的预处理。
从情感分类和问题分类来验证C-LSTM模型,结果表示比单独的LSTM和CNN好,并且LSTM可以从高级的表示学习长期依赖的信息。
2 Related Work
通过神经网络学习分布式的句子表示要求较少的外部知识,并且在情感分类和文本分类获得好的结果。
在一些句子的表示学习中,神经网络模型对输入的词序列和语法树进行处理,这些方法中CNN和LSTM是比较受欢迎的。
通过pooling在抽取高级关系时捕获局部特征可以使CNN自然地模拟连续的文本窗口。
由于RNN模拟时间序列的能力好,所以用来句子模拟。
现有的工作是使用多层的CNN,或是多个RNN。
我们的模型,使用CNN处理文本数据,然后转成连续的窗口特征,输入到LSTM,而且LSTM可以从高级特征学习长期依赖的知识,
3 C-LSTM Model

该模型包含两部分:CNN和LSTM
CNN:捕获词的高级特征
LSTM:捕获长期依赖信息
3.1 N-gram Feature Extraction through Convolution

3.2 Long Short-Term Memory Networks

4 Learning C-LSTM for Text Classification

4.1 Padding and Word Vector Initialization
采用maxlen表示训练集中句子的长度,卷积层需要固定长度的输入,短的句子采用pad方式增加到maxlen,pad在句子尾部,对于长于maxlen的句子,cut就好,
4.2 Regularization
dropout避免自拟合,L2归一化
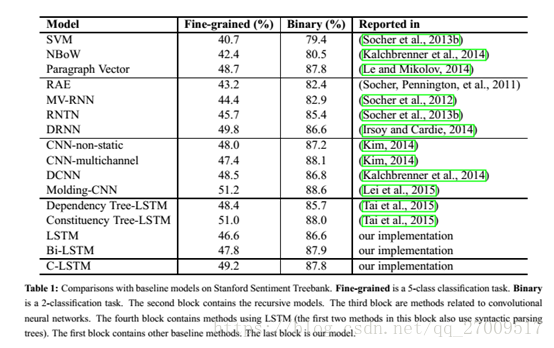
5 Experiments
数据:
- 情感分类:Stanford Sentiment Treebank (SST)
- 问题分类:TREC、location,human, entity, abbreviation,description and numeric.
5.1 Datasets
5.2 Experimental Settings
6 Results and Model Analysis