首先声明,虽是原创文章,但是站在了巨人的肩膀上进行创作的,借鉴了车哥AI蜗牛车的一些总结,加上了自己的补充和整理完成。
1. 写在前面
今天分享的这篇文章是2017年发表在Nips上的一篇文章,来自于清华的团队。是论文阅读系列的第二篇文章,这篇文章是在ConvLSTM的基础上进行改进的一个版本,所以如果想学习这篇文章,需要先搞懂ConvLSTM的工作原理,可以参考这篇博客:时空序列预测之Convolutional LSTM Network,这是时空序列学习很重要的一种结构,但是存在的问题就是像本篇论文提到的:记忆状态被限制在每个ConvLSTM层并且只能水平传递(时间域内进行更新),层与层之间的记忆单元是相互孤立的,这样带来的一个问题就是底层会完全忽略顶层在之前的时间步骤中所记忆的内容,简单的说就是原来的那种堆叠的ConvLSTM结构,层与层之间是独立的,t时刻的最底层cell会忽略t-1时刻最顶层cell的时空信息,并且层与层各cell之间的时空特征也没法传递。
所以本文对这个问题提出了改进, 亮点如下:
- 提出了一种新的端到端的结构PredRNN, 允许属于不同LSTMS的单元跨层交互
- 设计了一种新的时空LSTM(ST-LSTM)单元,它在一个统一的记忆单元中记忆空间和时间特征,并在垂直层面和水平层面上传递记忆。这种单元是PredRNN的关键部分。
论文下载: http://ise.thss.tsinghua.edu.cn/ml/doc/2017/predrnn-nips17.pdf

分享大纲如下:
- PART ONE : Abstract
- PART TWO: Introduction
- PART THREE: PredRNN
- PART FROE: Experiments And Results
- PART FIVE: Conclusion
2. Abstract
摘要部分,总结了一下全文,说了下面几个事情:
- 时空序列预测学习的目的是通过对历史帧的学习来生成未来的图像,两个关键部分是空间特征和时间变化
- 这篇文章提出了一种新的结构PredRNN,能够同时模拟这两部分
- PredRNN的核心是一个新的时空LSTM (ST-LSTM)单元,该单元同时对时空表象进行提取和记忆。
- 最后在视频预测和运动数字,雷达回波预测做的实验,证明这个结构好。
3. Introduction
3.1 为什么是时空记忆
在这里作者说了一下时空预测学习和时空监督学习区别:

时空预测学习任务中,决定预测系统表现的是两个关键方面:时间和空间。因为我们是根据过去的一段图像去预测未来的一段图像,这可不像时空监督学习做分类那么简单, 在时空预测学习中,时间和空间同样重要, 我们必须记住尽可能多的历史细节,当我们回忆以前发生过的事情时,我们不仅回忆物体的运动,而且回忆从粗糙到精细的视觉现象。这样才能去做图像的预测。
时空监督学习任务里面,时间特征对于分类任务来说足够强大,相反,细粒度的空间外观被证明不那么重要。 毕竟我们一般是根据一段图像去预测行为,在预期的输出中没有复杂的视觉结构需要建模,因此空间表示可以高度抽象。因为这种任务只是输出什么动作即可。
然而,目前最新的RNN或者是LSTM预测方法更加重视对时间建模(物体的运动轨迹),每个LSTM单元内存储的状态会随时间重复更新,这种堆叠式LSTM架构被证明是一种强大的时空监督学习架构, 但在时间预测学习方面表现并不突出,原因就是因为它在空间方面高度抽象了,越到后面,前面底层的一些重要的特征全都忘记了,这样就没法很好的去预测未来图像。
所以基于此,作者才提出了这种新的PredRNN的架构,这也是这篇文章的灵感来源。
3.2时空预测学习
时空预测学习是一个重要的问题,它可以在视频预测与监控、气象与环境预测、能源与智能电网管理、经济与金融预测等多个领域找到关键的、影响深远的应用。
这部分还是先从数学角度给出了时空学习预测的问题定义,还是那个公式:
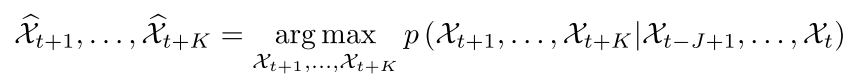
有数学公式,显得更加严谨一些,不懂得看时空序列预测之Convolutional LSTM Network。
然后就是又对施行健博士提出的ConvLSTM做了一点介绍,毕竟是基于这种单元改的, 但是在这里,作者指出了ConvLSTM的不足指出:

加入有四层的ConvLSTM的一个encoding-forcasting结构,输入帧进入第一层,将来的视频序列产生在第四层,在这个过程中,空间维度随着每层的cnn结构被逐步编码,而时间维度的memory cells属于彼此独立,在每个时间步被更新,这种情况下,最底层就会忽略之前的时间步中的最高层的时间信息,这也是ConvLSTM的层与层之间独立mermory mechanism的缺点。简单点说,就是这种简单的并行stacked结构中,堆叠之后层与层之间是独立的,t时刻的最底层cell会忽略到t-1时刻的最顶层cell的时间信息。就是之前提到的。
下面借助车哥画的图体会一下:
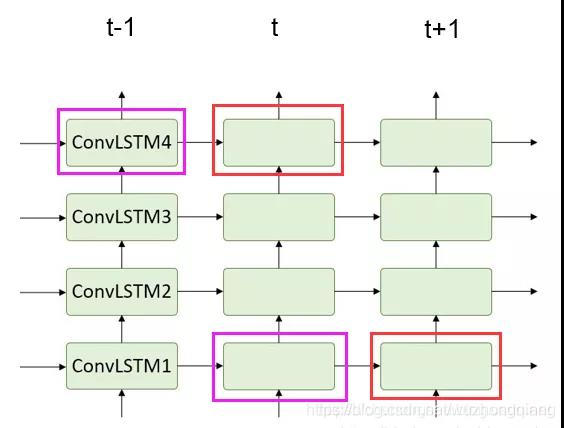
其实就是强调的对应色调的cell之间没有时间信息联系。
4. PredRNN
这部分就主要介绍PredRNN的这种结构,这个结构的启发就是:一个预测性学习系统应该在一个统一的记忆池中同时记忆空间表象和时间变化。
那么如何才能做到这一步呢?

下面就是详细的介绍了。、
4.1 Spatiotemporal memory flow
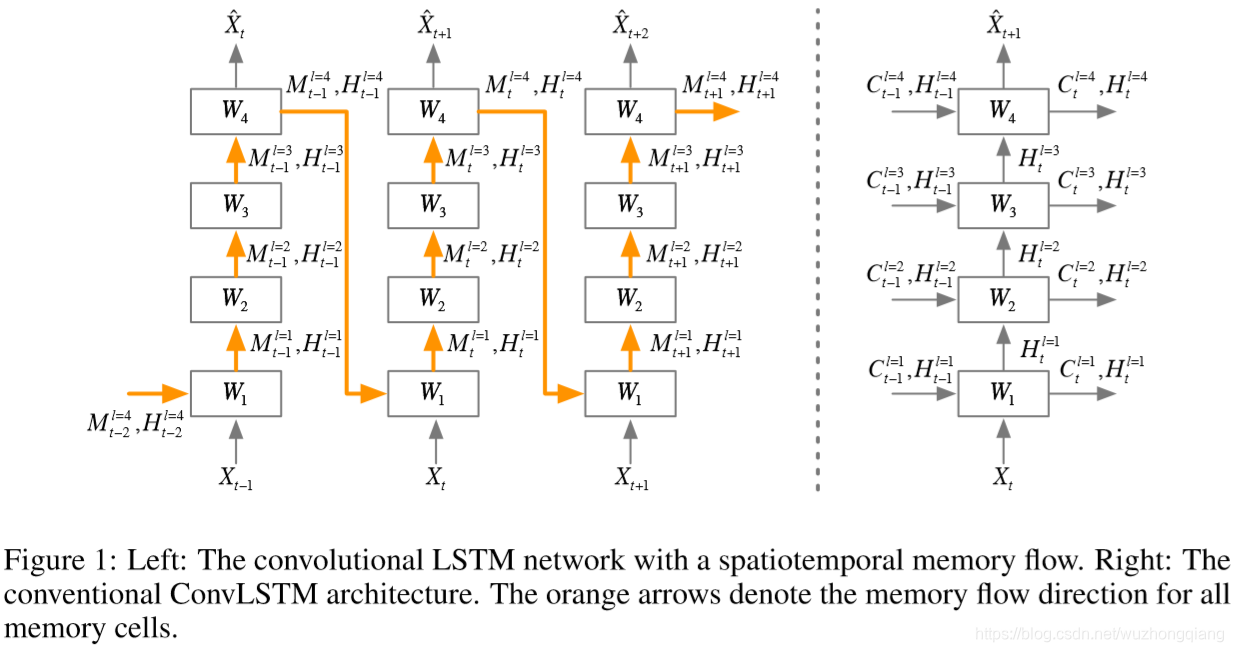
如果感觉之前介绍或者引言里面说的ConvLSTM什么什么不足太抽象的话,这里就是把话说清楚的最佳时间,这里可以看图说话。
我们先分析上面的右图, 这就是传统的堆叠的ConvLSTM结构,如果你看了之前的那篇文章之后,你会发现这个结构是下面这样的:
这里你会发现,每一层与每一层之间,只是单纯的一步一步的往上抽象特征, cell states只在水平方向上进行传递。 也就是同层的不同时间步中会有记忆流的传递,同一时间步不同层之间的这些单元是相互独立的,并没有记忆流传递,那么这时候的空间信息只在hidden state上向上传递,假设万一我t时刻最底层这个空间信息特别重要, 我也没法把这一个单元的空间信息传递到t时刻最顶层的单元中去。因为垂直方向上的单元是独立的,不存在记忆。
作者说这种时间记忆流在时空监督学习中是合理的,因为根据对叠加卷积层的研究,从底层向上隐藏的表示可以越来越抽象,越来越具有类特异性(监督学习中只需要预测类标签,越抽象越容易隐藏细节,越容易得到最终属于哪一类)。然而,我们在时空预测学习中,应该保持原始输入序列中的详细信息。如果我们想看到未来,我们需要学习在不同层次的卷积层中提取的表示。
所以提出的初步改进就是上面的左图结构:
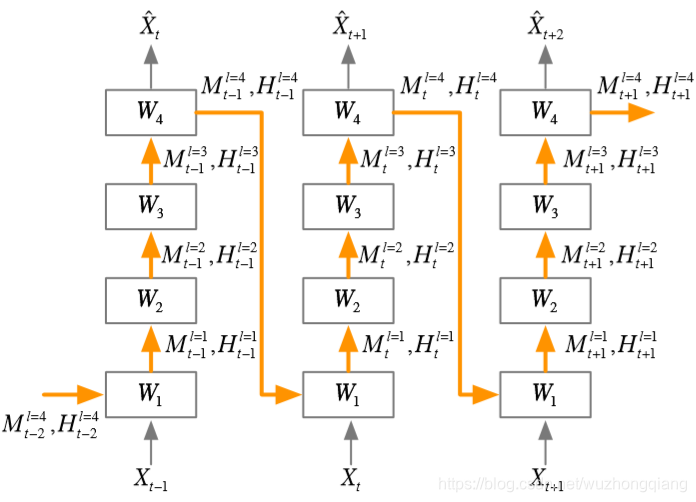
这种结构基于ConvLSTM单元应用了一个统一的时空记忆池,并改变了RNN的连接, 所有的LSTM共享一个统一的记忆流,并沿着之字形方向进行更新。具有时空记忆流的卷积LSTM单元的关键方程如下所示:
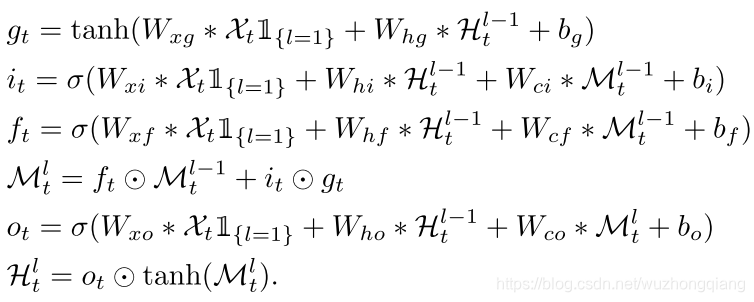
这里的M就是cell out,类似于之前的C,之所以这样标识,是形容一下这个记忆流之字形流动。
突然出现个,可能不知道啥意思了,那么就把原始的ConvLSTM的公式放下来:
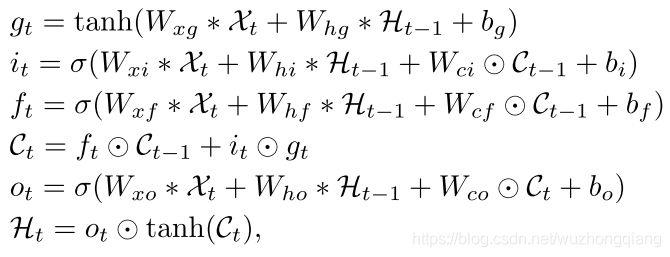
这里输入的hidden state和cell output都是上一个时刻的。
如果再看不懂, 那就再对比一下不同之处,没有对比就没有明白:
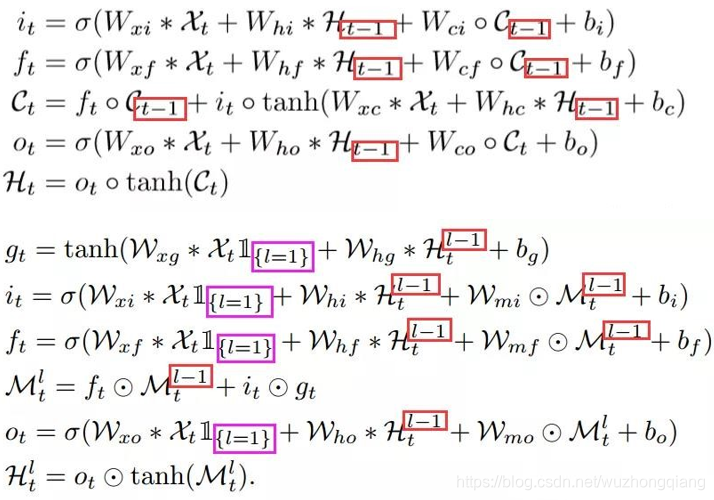
这样应该能看明白了吧, 传统的是同一层不同时间步的记忆传递,而下面的是同一时间步,不同层的记忆传递。
下面这个图里面的红色框表示在非最底层时的单个网络cell的公式变换,输入的hidden state和cell output都是前一层的(L-1) 而图中的的紫色部分说明L=1的时候有特殊情况,即图中的折线top到bottom的传播部分
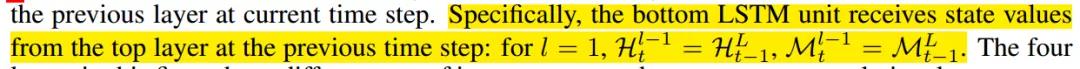
下面这幅图比较直观:
4.2 Spatiotemporal LSTM
上面那一小节提出的初步改进中,时空记忆单元以之字形方向更新,信息首先向上跨层传递,然后随着时间向前传递。
但是这种结构仍然有缺点:
- 去掉了水平方向的时间流, 会牺牲时间上的一致性,因为在同一层的不同时间没有时间流了
- 记忆需要在遥远的状态之间流动更长的路径,更容易造成梯度消失。
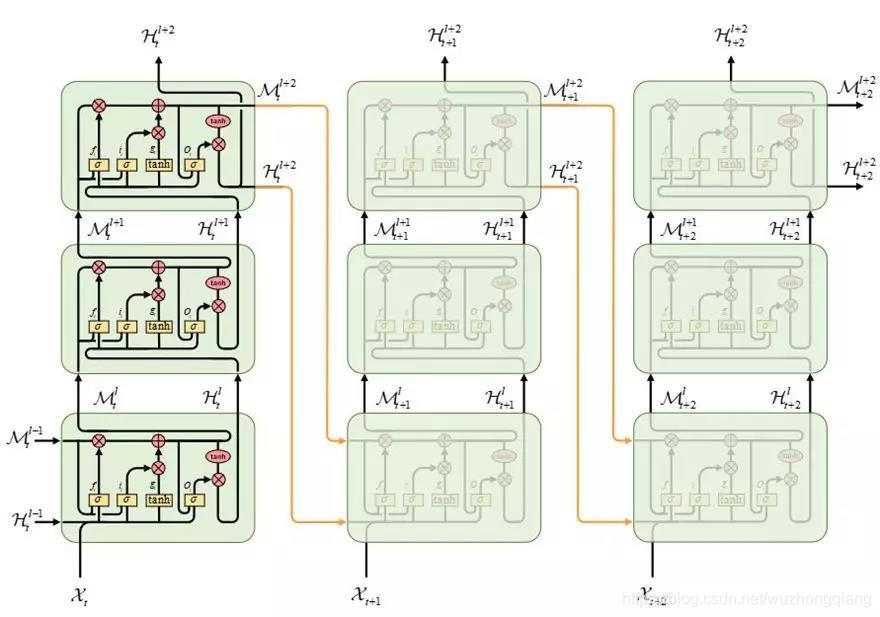
所以作者想知道如果记忆流同时在水平和垂直两个方向传递会发生什么, 就改进了传统的LSTM内部构造,引入了一个新的building blocks为ST-LSTM,并且基于这个单元,形成了一个新的架构PredRNN(主角登场),分别是下面的左边和右边。
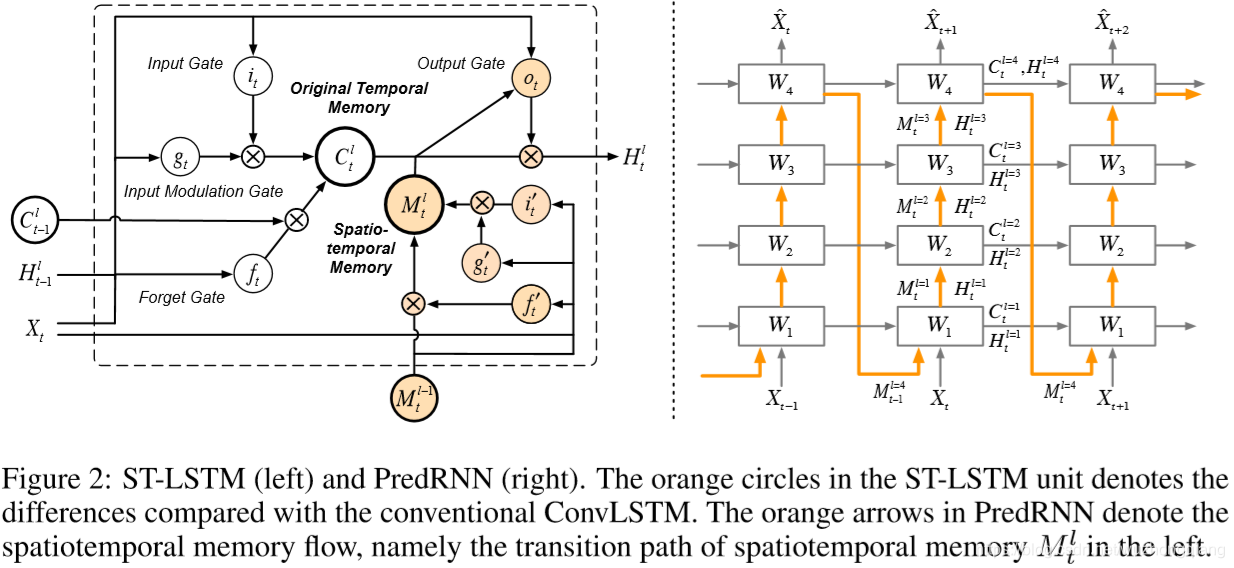
首先,要解释左边这个改进的ST-LSTM结构到底是啥意思?
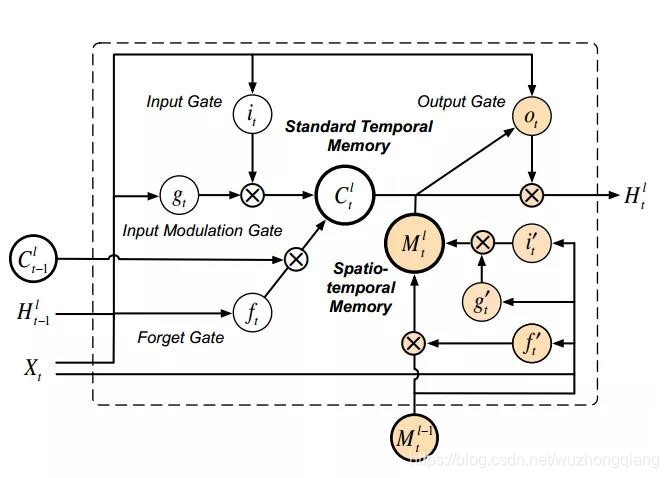
橙色的部分,其实就是新加入的时空记忆模块M,这一块负责层与层之间的时空记忆传递,就是上面说的之字形流动的记忆流,计算公式就是上一小节里面的方程。
白色的那块还是原来的时间记忆模块C,这一块负责横向时间的流传递。
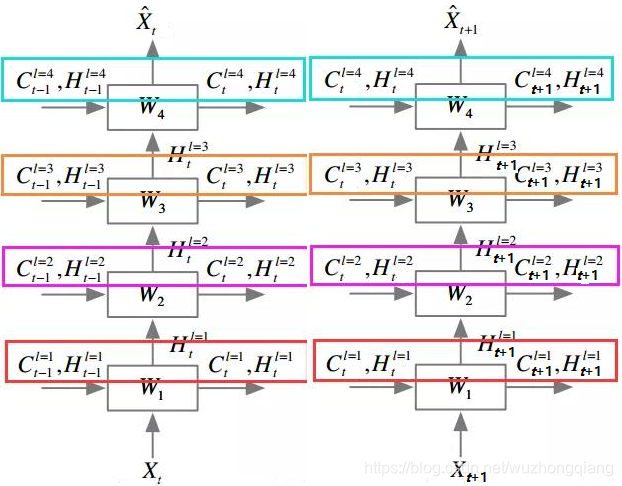
你发现了吗? 这两种结构其实是一样的,看不出来的话,转成下面这种形式:
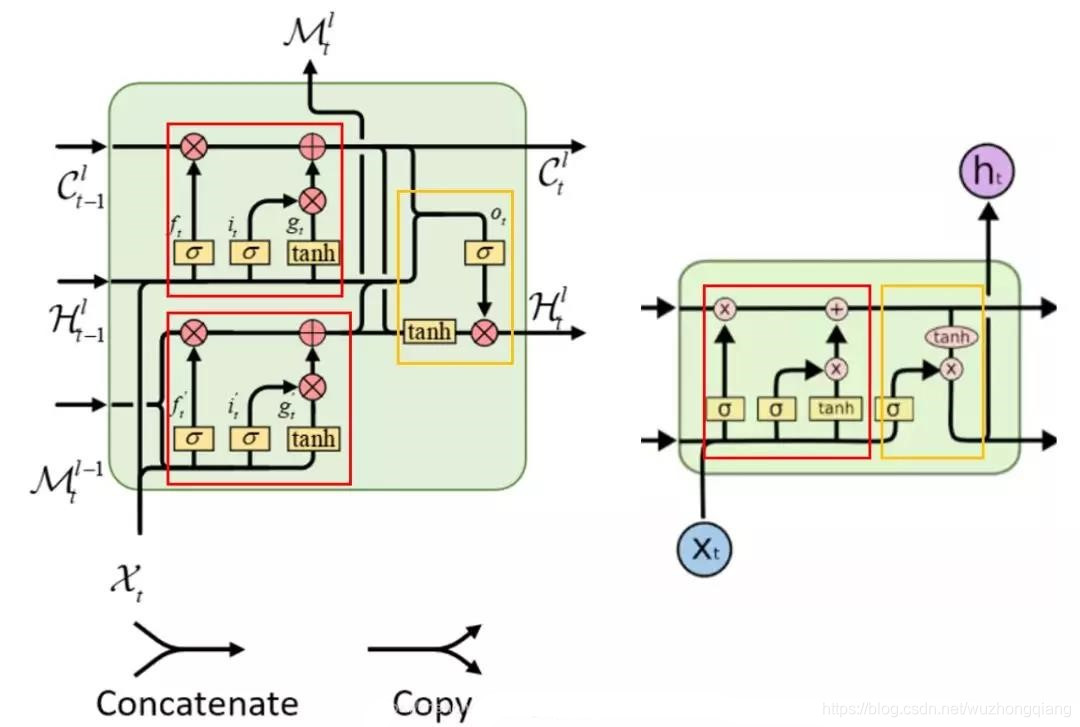
左边这个就是上面的ST-LSTM单元结构,右边的是普通的LSTM,你发现了吗?其实左边是两个完全一样的LSTM结构,只是下面的cell output和hidden state都由M代替了,其他的输出部分其实就相当于把两个LSTM结构的输出整合在一起分别输出计算了。 文中称左图的上半部分"Standard Temporal Memory", 下半部分称"Spatiotemporal Memory"。
懂了这个ST-LSTM内部的这个构造,就很容易看明白ST-LSTM的公式了:

有两种记忆的保留,C还是和之前一样,是前一个时间步到当前时间步的一个记忆传递,而M是时空记忆, 从l-1层的节点到当前l层的节点(相同时间步里面的),该节点的最终隐藏状态依赖于时空记忆的融合。
与简单的记忆拼接不同,ST-LSTM单元对两种记忆类型使用共享的输出门,实现了无缝的记忆融合,可以有效地对时空序列中的形状变形和运动轨迹进行建模。
这样,把下面的图中的两种结构进行合并,就得到了最终的PredRNN结构框架了。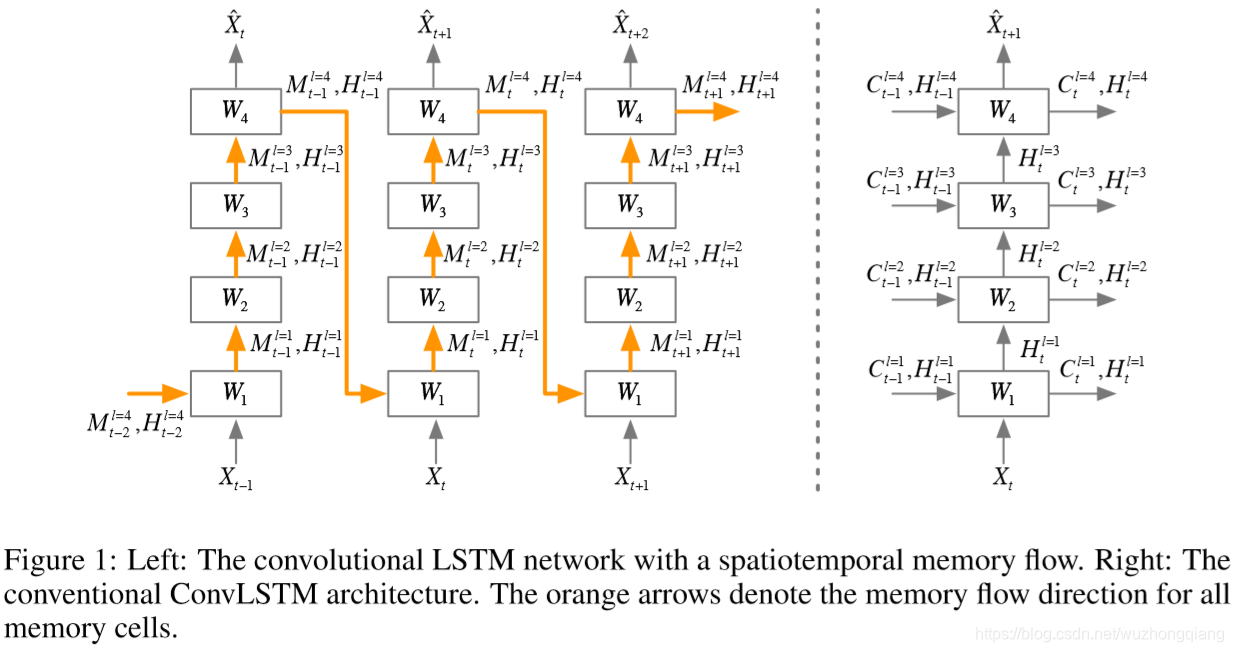
下面这张图也就迎刃而解了。
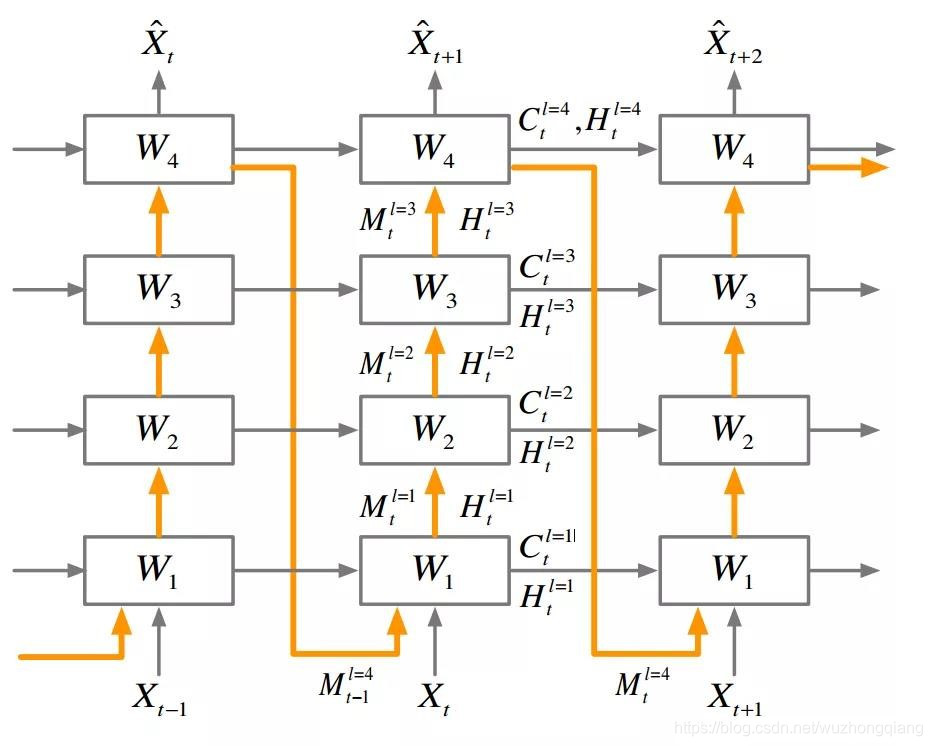
到这,终于说完了这个重要的角色了,这个结构这么复杂,可想而知,肯定功能也是比较强大了吧,哈哈, 下面就是检验这个结构的效果的时刻。
5. Experiments And Results
实验相关配置:

5. 1 Moving MNIST Dataset
Moving MNIST dataset数据集不再过多介绍, 每个序列由20个连续的帧组成,10个用于输入,10个用于预测。每一帧包含两个或三个手写数字跳跃在64*64网格的图像。

对运动的数字给一个速度,和随机的方向, 这个方向是单位圆也就是360°等分的一个角度,之后运动的振幅在3到5之间,并且存在两个数字的位置有覆盖的情况,故理论上可以生成无限数量的训练数据集。

测试集固定,并且模型从来没有见过。作者测试集的用法是每次挑选训练数据中,也就是除去与随机生成的训练数据集中相同的样本以外的测试数据集作为最终的测试数据集。并且用两个数字的训练集训练的模型去预测图中有三个数字的测试集,这也是ConvLSTM中同样用到的测试方法,无非是想测试模型的泛化性和迁移性。
下面是实验结果:
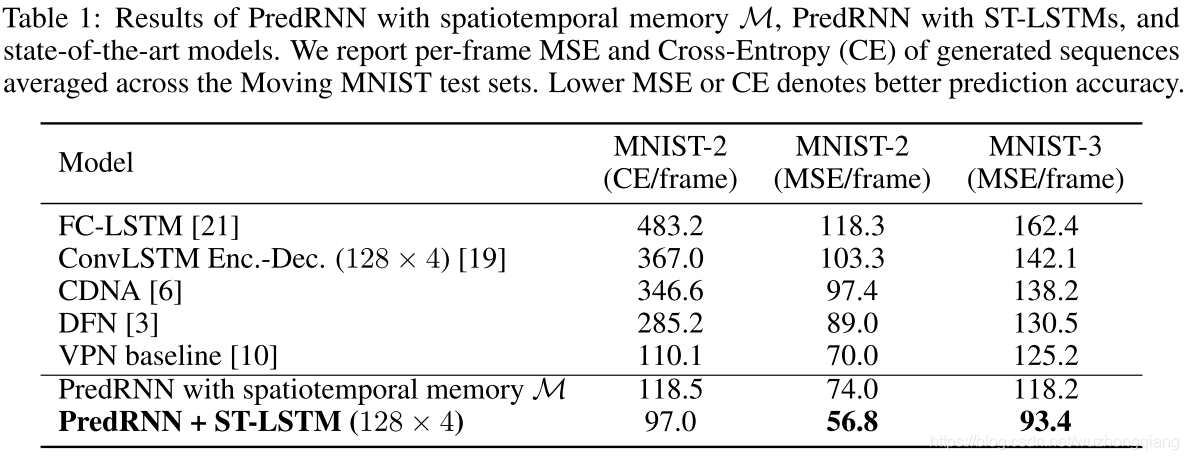
ST-LSTM的PredRNN的效果最好,这里给出的参数最好表现是128的hidden state 维度和4层的stacked结构。

几个模型的结果,很直观的可以看到对于数字没有重叠的情况下,PredRNN与VPN baseline效果差不多,但是在有重叠的情况下,VPN baseline把8预测成了3,文中把这种预测的情况叫成 sharp,说明VPN baseline模型对于复杂的情况还是没法很好的预测,并且整体的模型都是对于长时间的预测随着时间步的越来越长,变得越来越模糊。
5.2 KTH action dataset
KTH动作数据集包含六种类型的人类动作(步行、慢跑、跑步、拳击、挥手和拍手),由25名受试者在四种不同的场景中多次执行:户外、具有规模变化的户外、穿着不同衣服的户外和室内. 视频帧128*128,
所有的模型,包括PredRNN以及基线,在训练集上训练所有六类行动通过生成后续10帧,通过10帧的观察。然后测试集预测未来20帧
108,717个序列的训练集和4,086个序列的测试集
作者使用峰值信噪比(PSNR)和结构相似度指标(SSIM)作为度量来评估预测结果。 PSNR数值越大,预测性能越好。SSIM的值在-1和1之间,分数越大,说明两幅图像的相似度越大。
实验结果如下:
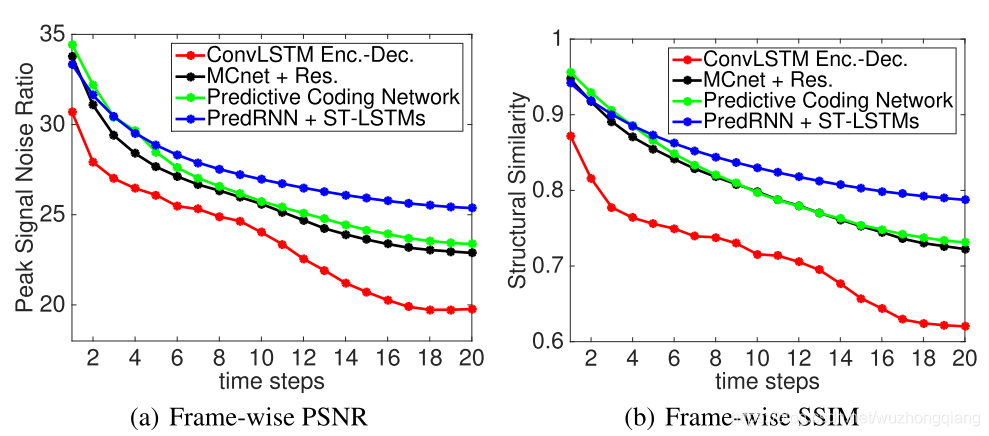
根据上面的图像,也能看出PredRNN的效果是最好的。

5.3 Radar echo dataset
对于雷达数据集的最难的地方就在于它没有所谓的明显的周期性,并且移动的速度也是不固定的,变换也不是极具严格的,比如Moving MNIST dataset数据集运动的对象是数字,这个数字本身空间的信息基本上是不变的,这个和识别问题类似,而雷达数据集会因为各种天气原因,慢慢的积累、消散或变化,或者快速的积累、消散或变化,所以预测问题也是十分艰难的,其实本身数据还有着大量的噪声,因为地形等因素造成的。

首先将雷达强度映射到像素值,用100*100灰度图像表示。然后用一个20帧宽的滑动窗口对连续图像进行切片。每个序列包含20帧,10帧用于输入,10帧用于预测。总共9600个序列被分为一个包含7800个样本的训练集和一个包含1800个样本的测试集。
预测后,将得到的回波强度转换成彩色的雷达图,然后利用Z-R关系计算出这些雷达图每个网格单元的降水量。
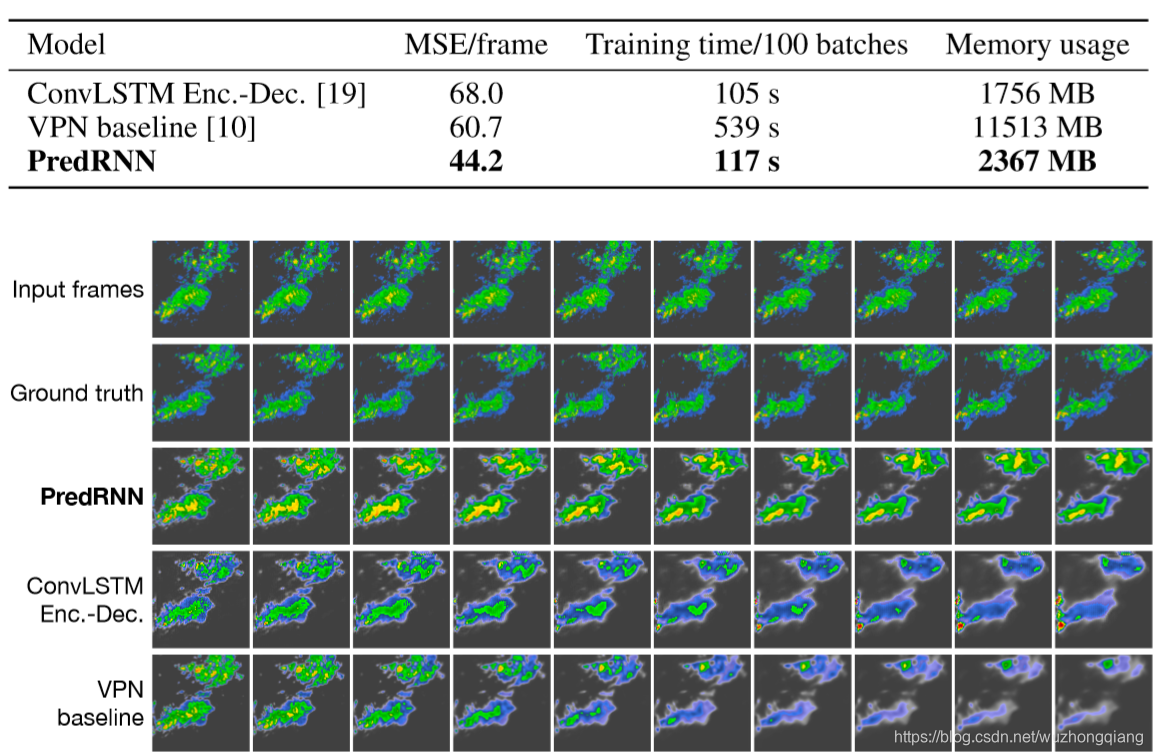
因为降水预测需要实时性,所以这里把训练速度以及占用的内存全都列出来了。可以很直观的看出predrnn的效果确实要较ConvLSTM和VPN baseline要好很多。并且运行速度也不是特别慢(VPN就很慢,因为它的预测是递归的,预测下一个时刻,之后再利用预测下一时刻的去预测下下一时刻,比较耗时)。
6. 总结

这一块就不多说了,总结起来还是提出了一种新的端到端的结构PredRNN, 设计出新的LSTM结构ST-LSTM作为PredRNN的关键部分,在时空序列预测数据集上得到了很好的效果。
这时候你可能会说,这种结构应该perfect了吧, 其实,没有最好,只有更好。 这种结构也存在问题,就是梯度消失的问题,尤其是那个之字形流动的那个,层数一多,时间一长,就容易梯度消失,没法更新了。针对这个问题,后面又有了更加强大的结构PredRNN++, 这种结构不仅获得了更强的空间相关性和短期动态的建模能力,而且还有效的解决了梯度消失的问题, 下一篇会具体描述。
今天的这篇文章到此结束,这篇文章有自己的理解,也参考了车哥的一些总结.,感谢车哥一下。
突然发现这个结构GitHub上也有开源,目前自己没有尝试,后期会努力复现这个结构,用到其他的任务上。
