1. 写在前面
今天分享的这篇文章2019年发表在ICLR上一篇论文,是时空序列预测系列的第四篇论文, 这篇论文从一个新的视角看待时空预测学习,提出了一个新的时空序列预测模型Eidetic 3D LSTM(E3D-LSTM),Eidetic意思是具有逼真记忆,强调网络的强记忆能力。该模型将3D卷积集成于LSTM,并改变了LSTM的门更新操作,使LSTM不仅能在时间层面,也能在空间层面上进行短期依赖的表象特征和运动特征的抽取,从而在更深的机制层面实现两种网络的结合。此外,在LSTM中引入自注意力(self-attention)机制,进一步强化了LSTM的长时记忆能力,使其对长距离信息作用具有更好的感知力,并且能够捕捉输入在时间维度的关联。 So This model is more powerful! 最后的时候,我们也来梳理一下用于时空序列预测四种模型ConvLSTM,PredRNN,PredRNN++和E3D-LSTM的一个逻辑发展关系。
亮点如下:
- 提出了一种新的时空序列学习的网络结构E3D-LSTM,该结构加入了self-Attention机制,把当前单元的状态记忆特征与前面某段时间的状态进行了一种关联,并让网络自己学习前面某段时间状态对当前的影响权重,这样,拓展了时间维度,可以更好捕捉长期的帧交互,使得长期表征学习成为可能。即使在长时间的干扰之后,也可以通过多个时间戳来回忆所存储的记忆。
- 为了达到对学习短期依赖和长期表征的一个均衡控制,改变了LSTM的更新门操作,引入了一种RECALL机制来改善记忆状态的递归转移函数,即当前的记忆状态更新取决于当前的输入和前一步的隐态,还取决于前一步记忆和过去某段时间的记忆的融合
- 提出了自我监督的辅助性学习,就是把帧预测和行为识别的任务合成一块,因为行为识别的任务需要记住更多过去的细节,而帧预测正好是记住了过去的细节去预测未来,所以后者可以作为前者的一种辅助,并且采用了迭代衰减系数来保证两个任务之间完成转移。
论文下载地址:https://openreview.net/pdf?id=B1lKS2AqtX

分享大纲如下:
- PART ONE : Abstract
- PART TWO:Introduction
- PART THREE: E3D-LSTM
- PART FROE: Experiments And Results
- PART FIVE: Conclusion
2. Abstract
摘要部分主要是对全篇论文的整体把握,提了三个事情, 第一个就是时空序列预测学习很难, 其原因是短期帧依赖和长期高层关系的良好表征难以学习。
然后提出了一种新的模型,Eidetic 3D LSTM(E3D-LSTM), 将3D卷积引入到了LSTM中,使得记忆单元更好的存储短期的特征, 对于长期的关联,更改了LSTM的更新门操作,通过一个Recall门控的自我注意模块使当前的记忆状态与它的历史记录相互作用,这种结构即使在长时间的干扰之后,也可以通过多个时间戳来回忆所存储的记忆。
最后,在多个数据集上进行试验,表现出了很好的性能,尤其是在强干扰下(Copy test).
3. Introduction
首先,作者说了时空预测学习目前用到的结构依然是RNN系列,由于其特有的门结构设计,对时间序列特征具有强大的抽取能力,因此被广泛应用于预测问题并取得了良好的成果,但是RNN并不能很好的学习到原始特征的高阶表示和长期关联性。这不利于对空间信息的提取。
空间建模则当属卷积神经网络(CNN),其具有强大的空间特征抽取能力,其中3D-CNN又能将卷积核可控范围扩大到时域上,相对于2D卷积灵活性更高,能学习到更多的运动信息(motion信息),相对于RNN则更有利于学习到信息的高级表示(层数越深,信息越高级),是目前动作识别领域的流行方法。当然3D卷积的时间特征抽取能力并不能和RNN媲美。
得益于3D卷积和RNN在各自领域的成功,如何进一步将二者结合起来使用也成为了研究热点,常见的简单方法是将二者串联堆叠或者并联结合(在图卷积网络出现之前,动作识别领域的最优方法就是将CNN和RNN并联),但测试发现这么做并不能带来太大的提升,这是因为二者的工作机制差距太大,简单的结合并不能很好的实现优势互补。
所以作者提出了一种结构,可以进行这两种结构的有效结合:

然后有说了一些研究背景,什么ConvLSTM, VPN等等这些结构,作者对比了新提出的这种结构和前面这些结构的不同以及优势:

简单的说就是之前的这些结构通过顺序更新记忆状态去预测未来,一旦记忆单元更新了,旧的记忆就没法保留下来了。 但是这样的后果就是后面我推理的时候,只能依靠前面时间的最新记忆。而E3D-LSTM则不一样,它借鉴了Attention的一种思想,
考虑了当前时刻某个单元的状态是否和过去某段时间有关,并赋予某段时间不同时刻不同的权重来关联当前时刻的状态,这样的好处就是每个时间步的记忆都能记录下来了。从而有助于更好的推理。

另一个不同就是使用了3维卷积作为E3D-LSTM的基础操作, 这样,拓展了时间维度,可以更好捕捉长期的帧交互,使得长期表征学习成为可能。

然后对比了之前提出的ST-LSTM, 借用了这里面的之字形记忆的更新曲线。
下面看看这个网络的架构。
3. EIDETIC 3D LSTM

3.1 3D CONVOLUTIONS IN RECURENT NETWORK

图中每个颜色的模块都代表了多层相应的网络。图(a)和图(b)是两种3D卷积和LSTM结合的基线方法,3D卷积和LSTM线性叠加,主要起到了编码(解码器)的作用,并没有和RNN有机制上的结合。图(a)中3D卷积作为编码器,输入是一段视频帧,图(b)中作为解码器,得到每个单元的最终输出。这两个方法中的绿色模块使用的是时空长短时记忆网络(ST-LSTM)[1],这种LSTM独立的维护两个记忆状态M和C,但由于记忆状态C的遗忘门过于响应具有短期依赖的特征,因此容易忽略长时依赖信息,因此E3D-LSTM在ST-LSTM的基础添加了自注意力机制和3D卷积操作,在一定程度上解决了这个问题。下面是作者描述的E3D-LSTM的简单过程:

图(c)是E3D-LSTM网络的结构,3D卷积作为编码-解码器(蓝色模块),同时和LSTM结合(橙色模块)。E3D-LSTM既可用于分类任务,也可用于预测任务。分类时将所有LSTM单元的输出结合,预测时则利用3D卷积解码器的输出作为预测值。
下面就来看看E3D-LSTM的具体细节。
3.2 EIDETIC MEMORY TRANSITION
提出的E3D-LSTM的单元结构如下图所示:

首先是这个单元的四个输入:

然后和ST-LSTM相比,主要有以下改进:
- 输入数据是的四维张量,对应时刻的连续帧序列,因此现在每个单元时间步都对应一段视频,而不是单帧视频。
- 针对帧序列数据额外添加了一个召回门(recall gate)以及相关结构,用于实现长时依赖学习,也就是自注意力机制。这部分对应网络名称中的Eidetic。
- 由于输入数据变成了四维张量,因此在更新公式中采用3D卷积操作而不是2D卷积。
大部分门结构的更新公式和ST-LSTM相同,额外添加了召回门更新公式:

这里的卷积 * 表示的三维卷积操作。

下面我们就看看这个公式里面的
是怎么进行更新的,现在与三个项有关了
- 当前的状态gt, It门进行控制
- 可以看做是一个来自前面记忆单元的短期连接,能够在相邻的时间戳中捕获短期的改变
- RECALL函数作为一个注意力模块,捕捉当前的记忆状态与过去某段时刻的关联性,Rt门控制位置和内容。
更新的时候,就是既考虑是否需要记忆当前的状态信息,也要综合考虑过去时间内的记忆对当前记忆的一个综合影响,softmax会给予过去时间的记忆一个影响权重来描述影响的程度。而Rt扮演的角色就是控制需要考虑过去的哪段时间哪些记忆可以保留下来。这个地方感觉还是人家的英语说得好一些:

正则化的作用无非就是减少协变移位,稳定训练过程。
当然,作者将这种机制也用在了不同层同一时间步的连接(M记忆单元的更新),但效果并不好,这是因为不同层在同一时刻学习到的信息并没有太好的依赖性。所以M的更新和原来一样,不过换成了三维的卷积操作。

作者最后说了自己提出的这个Attention机制的运用与借鉴论文里面的不同之处:注意机制不是应用于输出状态,而是应用于记忆转换期间。它是用来唤起过去的记忆,从遥远的时间戳,以记忆和提取被感知到的有用的信息。我们发现学习注意过去的记忆状态有助于回忆长期的历史背景。

3.3 SELF-SUPERVISED AUXILIARY LEARNING(基于E3D-LSTM的半监督辅助学习)
在许多监督学习任务,例如视频动作识别中,没有足够的监督信息和标注信息来帮助训练一个令人满意的RNN,因此可以将视频预测作为一个辅助的表征学习方法,来帮助网络更好的理解视频特征,并提高时间域上的监督性。
具体的,让视频预测和动作识别任务共享相同的主干网络(图1),只不过损失函数不同
-
在视频预测任务中,目标函数为:
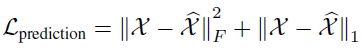
带上标的X表示预测值,不带上标的表示真值,F表示Frobenius归一化。 -
在动作识别任务中,目标函数为:
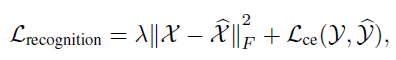
其中Y和是预测值和帧值,这样通过将预测任务的损失函数嵌入到识别任务中,以及主干网络的共享,能在一定程度上帮助识别任务学习到更多的时序信息。为了保证任务的过渡平滑,额外添加了一个权重因子,会随着迭代次数的增加而线性衰减:
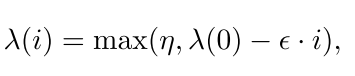
作者将这种方法称为半监督辅助学习。
4. EXPERIMENTS
4.1 MOVING MNIST
这里依然是使用了手写数字识别数据集, 这个在前面论文都有具体描述了,这里只说一下结果:

可以看到E3D_LSTM的效果是最好的。
下面, 为了证明E3D-LSTM模型能够更好地处理跨多个时间戳的有用历史表示,作者做了一个Copy Test,是在较长的输入序列中,当出现周期性干扰时,让网络记忆有用的信息。

看右边那个图,这个测试是这样做的,训练的时候有三段输入,seq1和seq2, 然后还有个Prior context先输入到网络,这个prior context和seq2是一样的,即预期的输出作为先前的输入,训练的时候,目标是2个,预测seq1的未来10帧,预测seq2的未来10帧,而测试的时候,只预测seq2的未来10帧,这样,seq1的预测在训练中就是一种比较强的干扰,就是为了看看E3DLSTM的这种网络抗干扰的效果。
结果所有的基线模型都受到Seq 2中不相关帧的影响,并逐渐忘记了之前情景中的显著信息,然而,由于eidetic 3D记忆,E3D-LSTM模型能够捕获长期的视频帧交互,并且在这两个指标上都表现良好,所以作者说:

最后,作者的Ablation Study

可以看到不管是添加3D卷积还是自注意力机制,网络性能相对于基线方法都有提升。
4.2 KTH ACTION
这个数据集也不过多的描述,可以参考前面的PredRNN++的那篇描述,下面也是直接上结果:

这个也做了copy test

作者得出结论:

4.3 其他任务
接下来在一个实际视频预测任务:交通流预测中,与其他方法进行了对比:

动作识别任务,在Something-Something数据集上进行了测试:

以及不同的半监督辅助学习策略带来的性能提升:

5. Conclusion

简单的说提出了基于3D卷积递归单元的E3D-LSTM模型。在该模型中,将3D-Convs集成到状态转换中来感知短期运动,并设计了一个由递归门控制的记忆Attention模块来捕获长期的视频帧交互。
最后,可以梳理一下这些网络之间发展关系了,开始的时候,时空序列预测任务是普通的LSTM, 但是这种结构对于空间特征的捕捉不好,所以在2015年的时候提出了一种ConvLSTM的结构来改进,这种结构可以捕捉空间和时间特征。 但是这种结构存在的问题是层与层之间没有记忆的传递,所以2017年提出了一种PredRNN的结构,提出了一种新的ST-LSTM单元,把时空记忆融合在一块,保证了记忆流既能水平传递也可以垂直传递,但带来的问题是梯度消失现象,所以2018年又提出了一种PredRNN++的结构,把时空记忆变成了级联的操作提出一种CasualLSTM单元,并且用了一种GHU的结构来解决梯度消失现象。虽然这三篇都在改进,但是考虑的记忆更新都是单纯的考虑某个单元的影响,并没有考虑到多个记忆单元之间的这种关联关系和影响。
2019年本篇提出的这个E3D-LSTM结构换了一个视角考虑时空预测学习的问题,借鉴了Attention的思想,考虑是否我当前的记忆单元与某去某段记忆有一定的关联,通过3D卷积操作把这种关联给表示了出来,使得历史的记忆也得以保留,从而更好的完成未来的推理预测。
如果想更了解这个发展过程,可以先从ConvLSTM的论文读起,然后是PredRNN, 然后是PredRNN++,这三篇你会发现一个循序渐进的过程, 然后你可以读读2017年的Attention is all you need这篇文章, 这里面详细介绍了Attention的思想,最后再回味本文就会有这个脉络的感觉了。 哈哈,巧了,我正好前面整理了这四篇。
