论文:https://arxiv.org/pdf/1611.06612.pdf
代码:https://github.com/guosheng/refinenet [MatConvNet]
参考文献:https://blog.csdn.net/u010067397/article/details/78836173
https://blog.csdn.net/melpancake/article/details/54143319
1. Introduction
语义分割的在这儿任务是给每个像素点分配一个标签,这也被认为是密集分类问题(dense classification problem)。相关的问题如被称为目标解译可以被转换为语义分割。最近的CNN网络,如VGG,ResNet等在识别中变现很好,但这些方法存在明显的限制当解决密集预测任务如语义分割时,下采样操作使得最终的图像信息损失很大。
一种方式是利用反卷积上采样信息,但这种方式无法恢复底层损失的信息。因此它不能生成准确的高层预测结果。底层信息是准确预测边界和细节的基础。DeepLab提出dilated卷积来在不下采样的基础上扩大感受野。但这种策略有两个限制。第一,需要计算大量的卷积特征图在高纬上而引起(computational expensive)+(huge GPU memory resources)。这限制了计算高层特征和输出尺度只能为输入的1/8。第二,dilate卷积引起粗糙下采样特征,这潜在导致重要细节的损失。
另外的方法融合中层特征和高层特征。这种方法基于中层特征保持了空间信息。这种方法尽管补充了特征如边界、角落等,但缺乏强大的空间信息。
所有层的信息对于语义分割都是有帮助的。高层的信息识别图像区域的类别,底层特征参数轮廓、细节边界信息。如何结合这些特征任然是一个开放问题。为了这个目的我们提出RefineNet网络, 主要贡献:
1、我们提出多路径Redinement网络,融合多层特征。
2、使用残差级联的方法组织网络。这样梯度可以短路传播。
3、我们提出链式残差池化来从一张大图区域中捕获背景信息。它通过多窗口尺寸池化特征,再通过残差链接和学习权重方式融合这些特征。
4、使用残差网络作为提取特征。
2. Background
ResNet -> FCN -> RefineNet
特别地,我们设置步长为2,这使得一个块到另一个块特征图减小一半,这样一系列的下采样有两个影响:
- 增加了更深层的感受野,使得过滤器能捕捉到更多的全局信息,这对于高质量的分类是有必要的。
- 使得训练有效、有迹可循因为每个层组合大量的过滤器,使得输出层有合适数量的通道。
尤其最后一层是输入的1/32大小,这样小的尺寸损失了大量的信息,这是CNN基础方法的普遍限制。
一种可选的方法是 dilate卷积。下采样操作被移除(stride=1),使用dilate卷积。这增加了内存消耗。
3. Proposed Method
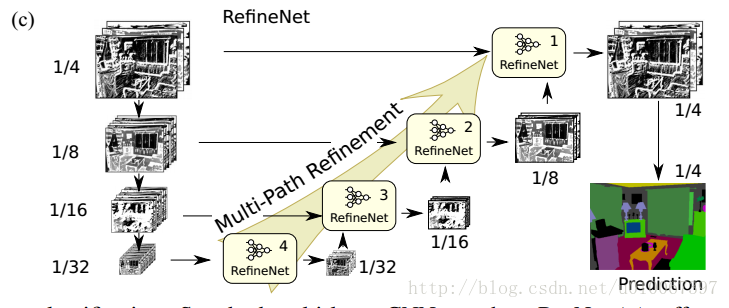
我们使用长残差连接探索多层特征为高分辨预测。RefineNet提供了一个融合高分辨语义特征和良好获得的低分辨语义特征来生成高分辨分割图。这种设计重要的一个方面是确保梯度可以无效的
接下来仔细看一下RefineNet block,可以看到主要组成部分是Residual convolution unit, Multi-resolution fusion, Chained residual pooling, Output convolutions. 切记这个block作用是融合多个level的feature map输出单个level的feature map,但具体的实现应该是和输入个数、shape无关的。

- Residual convolution unit就是普通的去除了BN的residual unit;
- Multi-resolution fusion是先对多输入的feature map都用一个卷积层进行adaptation(都化到最小的feature map的shape),再上采样再做element-wise的相加。注意如果是像RefineNet-4那样的单输入block这一部分就直接pass了;
- Chained residual pooling 卷积层作为之后加权求和的权重,relu 对接下来池化的有效性很重要,而且使得模型对学习率的变化没这么敏感。这个链式结构能从很大范围区域上获取背景context。另外,这个结构中大量使用了identity mapping 这样的连接,无论长距离或者短距离的,这样的结构允许梯度从一个block 直接向其他任一block 传播。
- Output convolutions就是输出前再加一个RCU。
思考
论文框架最主要的创新点是始终贯彻作者认为“所有特征都是有用的”这一个观点。从研究方法上说,作者还是考虑将不同层的特征都能融合起来,而不是在下采样的时候就丢失掉,丢失的既是局部细节特征,也影响预测结构的分辨率。从特征抽取的角度看,作者又新增一个中间层特征的抽取过程。在网络框架中,RCU 相当于是抽取低层特征,并且这些低层特征是从不同尺度的图像中抽取的;多分辨率融合模块,相当于是抽取中间层特征,除了refine-net4 以外,也起到融合多尺度的特征的作用,这样可以保留因为下采样导致的信息丢失的缺陷;最后的链式残差池化,相当于是抽取高层特征,这个模块里面不同池化相当于不同大小的窗口,还是在整合不同尺度特征,然后通过卷积加权加在一起,从而捕获背景上下文信息。
另一个值得关注的问题是,作者网络结构的细化部分基本都是按照残差网络的思想来的,一方面是因为残差网络的提出,就是为了适应更深层次的神经网络,既然需要使用深层次的网络结构,就离不开残差网络的结构,而且残差网络都是使用的identity mapping,即恒等映射。