1. 词向量
词向量就是用来将语言中的词进行数学化的一种方式,顾名思义,词向量 就是把一个词表示成一个向量。这样做的初衷就是机器只认识0 1 符号。所以,词向量是自然语言到机器语言的转换。
Word2Vec其实就是通过学习文本来用词向量的方式表征词的语义信息,即通过一个嵌入空间使得语义上相似的单词在该空间内距离很近。Embedding其实就是一个映射,将单词从原先所属的空间映射到新的多维空间中,也就是把原先词所在空间嵌入到一个新的空间中去。
1.1 one-hot representation
一种最简单的词向量是one-hot represention,就是用一个很长的向量表示一个词,向量的长度为词典D的大小N,向量的分量只有一个1,其他都是0,1的位置对应该词在字典中的索引;也就是向量中每一个元素都关联着词库中的一个单词,指定词的向量表示为:其在向量中对应的元素设置为1,其他的元素设置为0。
例如
“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …]
“麦克”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]
优点: 如果使用稀疏方式存储,非常简洁,实现时就可以用0,1,2,3,…来表示词语进行计算,这样“话筒”就为3,“麦克”为8.
缺点:
1.容易受维数灾难的困扰,尤其是将其用于 Deep Learning 的一些算法时;
2.任何两个词都是孤立的,存在语义鸿沟词(任意两个词之间都是孤立的,不能体现词和词之间的关系)
1.2 Distributioned representation
为了克服one-hot representation的缺点, Hinton在 1986 年提出了Distributioned
Representation,可以解决“词汇鸿沟”问题,可以通过计算向量之间的距离(欧式距离、余弦距离等)来体现词与词的相似性。
Distributioned Representation,其基本思想是:通过训练将某种语言中的每一个词映射成一个固定长度的短向量(当然这里的“短”是相对于one-hot representation的“长”而言的)。所有这些向量构成一个词向量空间,而每一个向量则可视为该空间的一个点,在空间中引入“距离”,就可以根据词之间的距离来判断他们之间的相似性。word2vec 中采用的就是这种Distributioned Representation的词向量。
2. 语言模型:
2.1 传统语言模型
传统的语言模型中词的表示是原始的、面向字符串的。两个语义相似的词的字符串可能完全不同,比如“番茄”和“西红柿”。这给所有NLP任务都带来了挑战——字符串本身无法储存语义信息。该挑战突出表现在模型的平滑问题上:标注语料是有限的,而语言整体是无限的,传统模型无法借力未标注的海量语料,只能靠人工设计平滑算法,而这些算法往往效果甚微。
2.2 N-gram
N-gram就是最简单的一种语言模型。N-gram的数学模型非常简单,就是一条数学表达式:
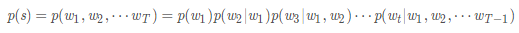
上面概率公式的意义为:第一次词确定后,看后面的词在前面次出现的情况下出现的概率。
例如,有个句子“大家喜欢吃苹果”,一共四个词”大家,喜欢,吃,苹果”
P(大家,喜欢,吃,苹果)=p(大家)p(喜欢|大家)p(吃|大家,喜欢)p(苹果|大家,喜欢,吃)
p(大家)表示“大家”这个词在语料库里面出现的概率;
p(喜欢|大家)表示“喜欢”这个词出现在“大家”后面的概率;
p(吃|大家,喜欢)表示“吃”这个词出现在“大家喜欢”后面的概率;
p(苹果|大家,喜欢,吃)表示“苹果”这个词出现在“大家喜欢吃”后面的概率。
把这些概率连乘起来,得到的就是这句话平时出现的概率。
为了表示简单,上面的公式用下面的方式表示
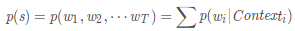
其中,如果Context_i是空的话,就是它自己p(w),另外如“吃”的Context就是“大家”、“喜欢”,其余的对号入座。
但是如何计算p(w_i∣Context_i) 呢? 上面看的是跟据这句话前面的所有词来计算,这样计算就很复杂,像上面那个例子得扫描四次语料库,这样一句话有多少个词就得扫描多少趟。语料库一般都比较大,越大的语料库越能提供准确的判断。这样计算开销太大。
N-gram的精髓
为了解决这个问题,N-gram假设一句话中,一个字只跟这个字之前的几个字相关(一般为2或3),这本身就是马尔科夫模型的思想。因此,上式的计算变成:

2.3 神经网络概率模型
神经概率语言模型(Neural Probabilistic Language Model)中词的表示是向量形式、面向语义的。两个语义相似的词对应的向量也是相似的,具体反映在夹角或距离上。甚至一些语义相似的二元词组中的词语对应的向量做线性减法之后得到的向量依然是相似的。词的向量表示可以显著提高传统NLP任务的性能,例如《基于神经网络的高性能依存句法分析器》中介绍的词、词性、依存关系的向量化对正确率的提升等。
3. word2vec
word2vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包,它简单、高效,因此引起了很多人的关注。
word2vec通过训练一个神经网络,得到网络的权重矩阵,作为输入的词向量。常用的word2vec模型是:CBOW,Skip-gram。框架图如下:

CBOW,Skip-gram两者的差别在于:CBOW通过上下文预测中心词概率,而Skip-gram模型则通过中心词预测上下文的概率。
什么意思呢?举个例子,对于一句话:社会主义就是好,对于CBOW,如果要预测“主义”,则输入就是“社会”,“就是”,“好”;对于Skip-gram,输入则是“主义”,输出是剩下的几个字。
但它们的相同点在于,这两个算法训练的目标都是最大限度的观察实际输出词(焦点词)在给定输入上下文且考虑权重的条件概率。比如在上段的例子里,通过输入“社会”,“就是”,“好”之后,算法的目标就是训练出一个网络,在输出层,能最大概率的得到“主义”的条件概率。
3.1 CBOW
CBOW 是 Continuous Bag-of-Words Model 的缩写,是一种根据上下文的词语预测当前词语的出现概率的模型。其架构如下图所示:


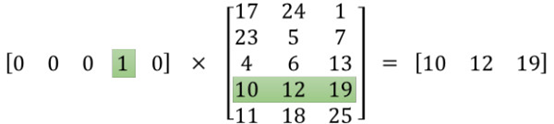
举个例子就知道了。如果输入是100001的one-hot向量,而隐含层神经元是300,则可见,权重矩阵(输入层-隐含层)为10000300。而这时,权重矩阵的每一行就是一个词的词向量。为什么?我们来看看这个乘法:
3.2 Skip-gram
Skip-gram只是逆转了CBOW的因果关系而已,即已知当前词语,预测上下文。
其网络结构如下图所示:

参考资料:
1、一文详解 Word2vec 之 Skip-Gram 模型(结构篇)
2、word2vec 中的数学原理详解
3、word2vec词向量训练及gensim的使用
4、word2vec源码
