Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型,它被大量地用在自然语言处理(NLP)中。Word2Vec模型中,主要有Skip-Gram和CBOW两种模型,本文将详细介绍这两种模型。
CBOW
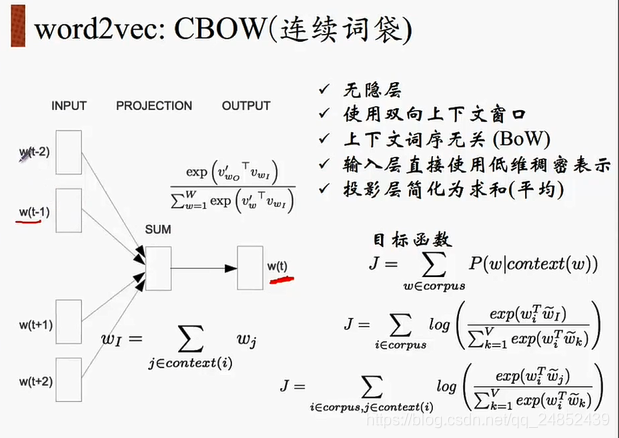
CBOW全称是Continuous Bag of Words Model,即连续词袋模型,模型如下图(图为七月在线NLP课程截图)
由图可看出,CBOW的输入是上下文,输出是中间词,即是通过上下文内容来预测中间词。
接下来我们来看看如何训练我们的神经网络。假如我们有一个句子“The dog barked at the mailman”。
定义两个参数batch_size和bag_window,batch_size定义了batch个数,bag_window定义了上下文长度,假设我们设置batch_size为4,bag_window为1,那么我们得到的batch为:[['The', 'barked'], ['dog', 'at'], ['barked', 'the'], ['at,'mailman']],对应的labels为['dog', 'barked', 'at', 'the']将batch作为x,label作为y喂入构造的网络中就可以生成一个概率分布
定义batch的代码可参考以下代码:
data_index = 0
def cbow_batch(batch_size, bag_window):
global data_index
batch = np.ndarray(shape=(batch_size,bag_window*2), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * bag_window + 1 # [ bag_window target bag_window ]
buffer = collections.deque(maxlen=span)
for _ in range(span):
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
for i in range(batch_size):
batch[i] = list(buffer)[:bag_window] + list(buffer)[bag_window+1:]
labels[i] = buffer[bag_window]
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
return batch, labels
对于CBOW还有以下一些改进模型:


Skip-Gram
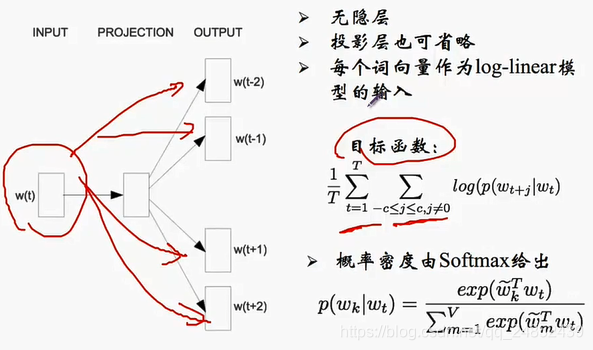
Skip-Gram与CBOW的输入输出正好相反,Skip-Gram是以中心词作为输入,上下文作为输出,具体模型如下:
接下来我们来看看如何训练我们的神经网络。假如我们有一个句子“The dog barked at the mailman”。
定义两个参数,一个叫做skip_window的参数,它代表着我们从当前input word的一侧(左边或右边)选取词的数量,另一个参数叫num_skips,它代表着我们从整个窗口中选取多少个不同的词作为我们的output word。假设当batch_size=4,skip_window=2,num_skips=2时,得到batch为
['barked', 'barked', 'at', 'at'],labels为['dog', 'at', 'barked', 'the']其中label和batch不是一一对应的,假设以中心词’barked’为例,因为num_skips=2,所以label是从’The’, ‘dog’, ‘at’, 'the’四个词中随机调出的两个。
神经网络基于这些训练数据将会输出一个概率分布,这个概率代表着我们的词典中的每个词是output word的可能性。
定义batch的代码可参考以下代码:
def generate_batch(batch_size, num_skips, skip_window):
global data_index
assert batch_size % num_skips == 0
assert num_skips <= 2 * skip_window
# x y
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * skip_window + 1 # context word context
# deque是一个左右都可以增加元素的结构
buffer = collections.deque(maxlen=span)
# 滑动窗口大小,取上下文
for _ in range(span):
buffer.append(data[data_index])
# print(buffer)
# print(data_index)
# 循环使用
data_index = (data_index + 1) % len(data)
# i表示batch中中心词的个数
for i in range(batch_size // num_skips):
target = skip_window #
targets_to_avoid = [ skip_window ]
# j表示一个中心词取多少个上下文
for j in range(num_skips):
# print(target)
# print(targets_to_avoid)
# 随机从span个词中出num_skips个
while target in targets_to_avoid:
target = random.randint(0, span - 1)
targets_to_avoid.append(target)
batch[i * num_skips + j] = buffer[skip_window]
labels[i * num_skips + j, 0] = buffer[target]
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
return batch, labels
参考:https://blog.csdn.net/qq_24003917/article/details/80389976
