skip-gram模型中,我们需要抽取上下文和目标词配对来构造监督学习问题。
而目标词不一定总在上下文之前,所以我们随机选一个词作为上下文。当然随机也是在限定一个范围内。比如正负五个词。

我们使用这个模型并不是为了解决这个监督学习问题本身,而是想要得到一个好的词嵌入模型。
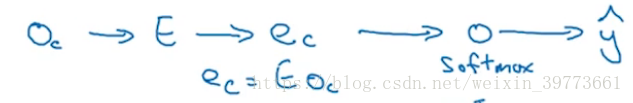
该方法主要是,使用嵌入向量,将其投入softmax来预测与该上下文单词有一定距离的单词。skip,跳过指隔了几个单词。
这个算法有问题。
首要问题是计算速度。10000个单词的词典的速都很慢不用说更大的词典了。
解决方案:使用分级softmax树

不用一下子就确定属于10000个单词中的哪一个。而是逐级寻找。类似二分算法。
首先确定单词是属于词典前5000个单词还是后5000个,然后是前2500还是后2500等等。
当然,把最常用的单词放在最上面最好找的位置来加快寻找速度。
怎样对上下文c进行采样?
目标单词可能在c的上下十个单词之内。
一种方法是对语料库均匀且随机采样。
word2vec的另一个版本是CBOW,它使用两边的单词来预测中间的单词。
softmax的计算成本非常高,有一种替代方法,即负采样。