翻译原始链接: http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
这个教程包含 训练word2vec的 skip-gram 模型。通过这个教程,我希望跳过常规Word2Vec 的介绍和抽象理解, 而是去讨论一些细节。特别是skip gram的网络结构。
模型
skipgram model 常常让人惊讶于它的简单结构。我认为基本没啥弯路,或者需要复杂的模型解释。
让我们从高层语义开始。Word2Vec 使用了一个小trick,你可能在其他machine learning问题中见过。我们训练一个简单的网络来执行一个任务,但是最乎我们实际上并没有用这个网络 来预测 test中的任务。而是,利用这个任务(目标)去学习网络中的权重W。我们将看到这些学出来的权重W就是我们所要的词向量(word vectors)。
你可能会见到这个trick,的另一个地方是 auto-encoder。 auto-encoder 常常用来压缩一个输入,然后再把压缩后的结果解压回去。在训练完成之后,你可以把解压的网络扔掉,只使用压缩的网络。这就是一个trick来获得 无监督下 好的图像特征。- 1
假任务
那现在我们来讨论一下我们所要建立网络的训练任务(假任务)。然后我们再来讨论为什么这个任务可以间接地学习到想要的word vector。
给定句子中一个特定的词(input word),随机选它附近的一个词。网络的目标是预测 我们选到这个附近词的概率。
实际上这个“附近“,是一个窗口。一个常用的窗口大小为5,意味着 输入词前方的5个词,后方的5个词。- 1
输出的概率实际上关系到周围的每一个词。比如,如果你给出一个词苏联(Soviet),那么概率很高的输出 应该是 联合(Union)和俄罗斯(Russia)而不是西瓜或者袋鼠。
我们通过给网络 输入我们在训练文本中 找到的词对,来训练网络。下面这个例子展示了从“The quick brown fox jumps over the lazy dog.“ 中找到的一些词对. 我使用了window size=2,而蓝色标出的词为输入词。 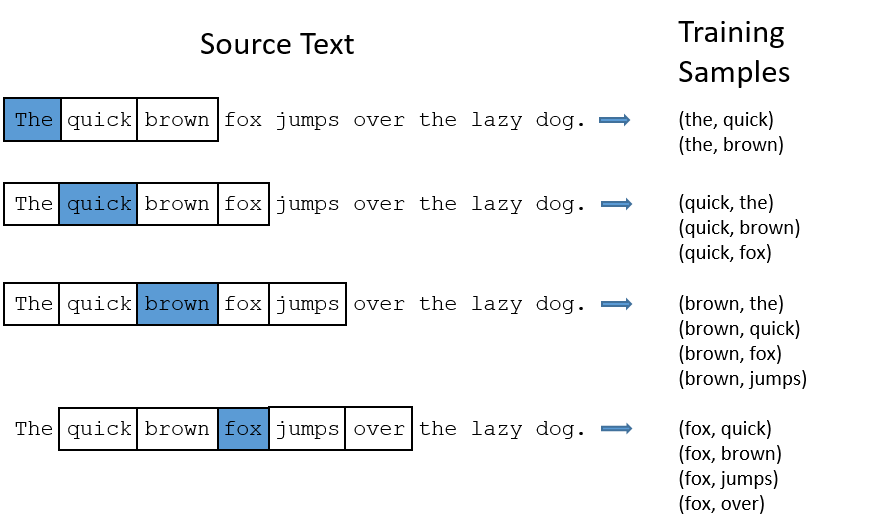
网络将会去学这些pair出现的统计概率。举个例子来说,网络会得到很多 (苏联,联合)的概率多过(苏联,大脚怪)。所以当训练完成的时候,当你输入了苏联这个词,联合会得到比大脚怪更高的预测概率。
模型细节
首先,你不能把word变成一个string输入给网络,所以我们要找另外一个形式。所以我们首先建立一个word的词典,比如我们有10,000个不同的词,那么我们就建立一个10,000的词典。
“ants“就可以变成一个10,000维的向量。这个向量每一维代表一个词,我们把代表“ants“的那一维置为1,其他维置为0。
而网络的输出也是一样也是一个 10,000维的向量,代表每个词预测的概率。
网络结构如下图: 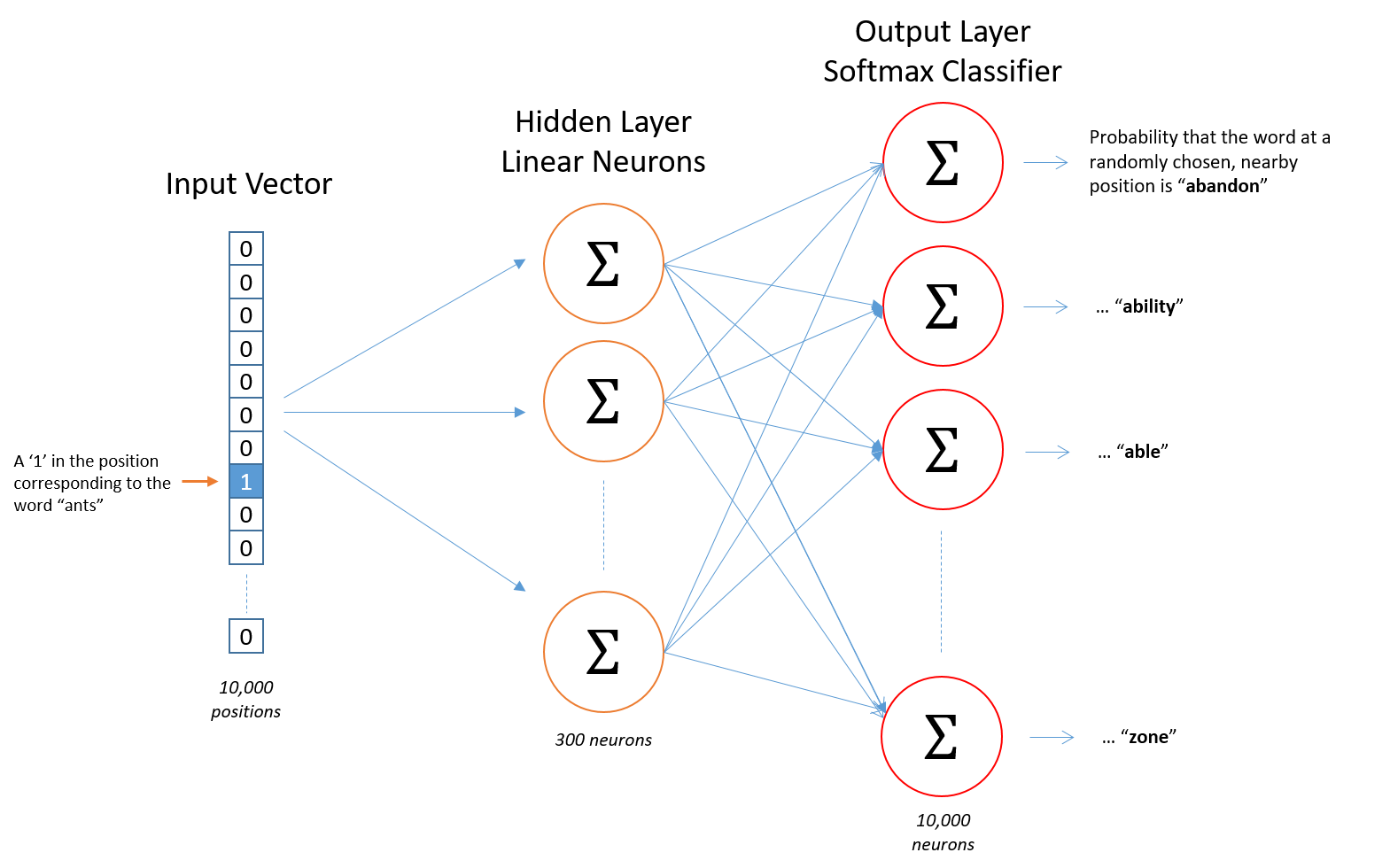
网络中没有激活函数,输出使用的是softmax。我们等下再回来讨论。
当使用这个网络来训练词pair的时候,训练的输入是one-hot向量 训练的目标输出也是一个one-hot向量。但实际test这个网络的时候,输出会是一个概率分布。
(译者按:打个比方,苏联只 和 联合/俄罗斯 有交集,所以会收敛到 50%, 50% 的分布。而不是 联合就是100%。 当然test的时候也可以找最高概率的结果,那也是one-hot。)
隐层
我们需要学习300维的word vector。所以我们使用的隐层将是 10,000行 (词典中词的数量)和 300列的 (每个隐层神经元)。
300 是Google公布出来在Google news 上训练使用的维数,你可以通过这个链接([https://code.google.com/archive/p/word2vec/]) 下载(需翻墙)。这书300是个超参,可以按你的实际需求修改。- 1
如果你从行的角度看,这个隐层的W实际上就是我们要的word vector。 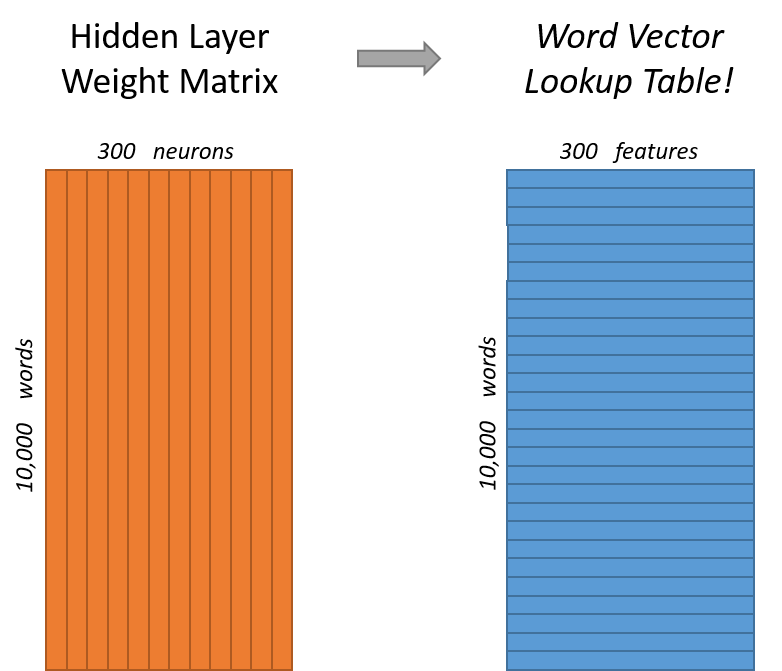
所以最终目标就是 让网络学习 隐层中的权重。当我们训练完成的时候,我们就可以把后半部分 output层给去掉了。
好,让我们回到之前的模型的定义。
现在你可能在问自己,one-hot向量就是基本全是0,只有一个是1的向量,那么这会产生什么结果呢? 当你用 1×10,0001×10,000 乘 10,000×30010,000×300 的矩阵,他相当于只选择了那一行‘1‘的。下面是一个简单的例子: 
这意味着这个网络的隐层实际上就是像一个 查找表(lookup table)一样。输出的300维就是这个词的word vector。
输出层
‘ant‘的1×3001×300 的word vector 然后传到了输出层。输出层是一个softmax 的分类器(译者按:我认为不是regression,就是classification吧)主旨就是把每个输出normal到0~1之间,并且这些输出的和为1。
更具体的来说,每个word vector(1×3001×300)将会乘一个W(300×10,000300×10,000)再次映射到 10,000维,每一维代表临近词的概率。而这些概率做一个softmax的normal(就是图中的expexp 的函数,来归一化)。 下面是一张说明图。 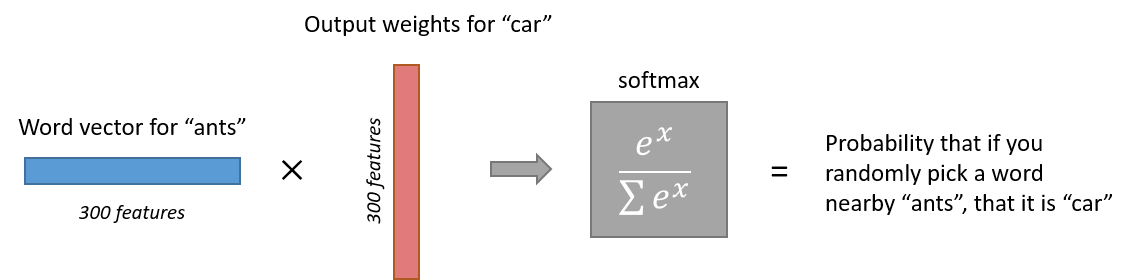
需要注意的是,神经网络彬不知道输出词对于输入词的位置。输出词常常在输入词的前面还是后面。举个例子来说,虽然York 100%是跟在 New的后面,但是训练出来的网络 用York 作为输入,New 并不是100%的,还可能是其词。- 1
直觉
让我们对这个网络做一个直觉上的感受。
如果两个不同的词有相同的上下文,那么我们的模型会需要预测类似的输出。那么网络为了输出类似的预测,他就会使这两个不同词的word vector尽可能相似。所以,如果两个词有相同的上下文,我们就可以得到比较接近的word vector。
那么什么词有相同的上下文? 比如一些近义词 smart 和intelligent 再比如 一些相关的词 engine 和 transmission。
这也可以帮你处理一些形式变化。比如 ant 和ants 因为他们应该有类似的上下文。
下一步
你可能注意到 skip-gram 有很多权重需要学习。 举个例子说,300维特征,10,000的词表, 3MB×23MB×2 的权重需要去学习,输入输出层各一个。
所以如果在一个更大的词典上学习,word2vec的作者引入了一些trick 让训练更可行。这将会在下一章中介绍。(我也做了翻译,欢迎大家继续看~)