日志收集框架Flume
概览
Apache Flume是一个分布式,可靠且可用的系统,用于有效地收集,聚合大量日志数据并将其从许多不同的源移动到集中式数据存储中。Apache Flume的使用不仅限于日志数据聚合。由于数据源是可定制的,因此Flume可用于传输大量事件数据,包括但不限于网络流量数据,社交媒体生成的数据,电子邮件消息以及几乎所有可能的数据源。
数据流模型
Flume事件定义为具有字节有效负载和可选字符串属性集的数据流单位。Flume代理是一个(JVM)进程,承载了组件,事件通过这些组件从外部源流到下一个目标(hop)。
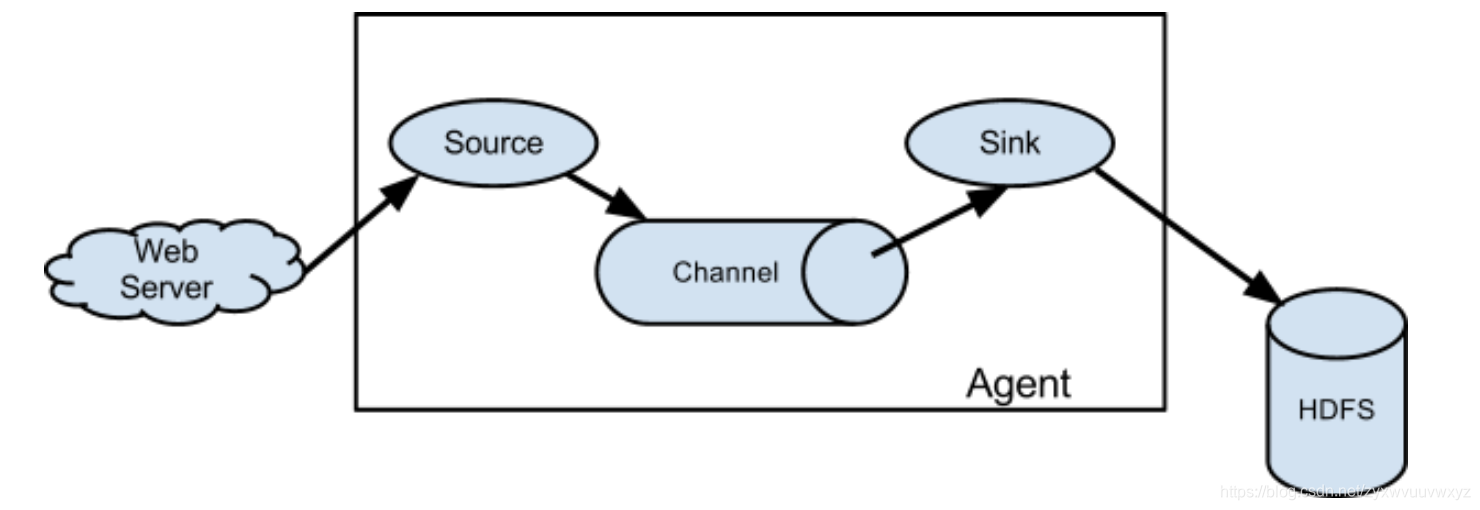
Flume源使用由外部源(如Web服务器)传递给它的事件。外部源以目标Flume源可以识别的格式将事件发送到Flume。当Flume源收到事件时,它将事件存储到一个或多个通道中。通道是被动存储,可保留事件直到被Flume Sink消耗掉为止。接收器从通道中删除事件,并将其放入HDFS之类的外部存储库(通过Flume HDFS接收器),或将其转发到流中下一个Flume代理(下一跳)的Flume源。给定代理中的源和接收器与通道中上演的事件异步运行。
Flume允许用户建立多跳流程,其中事件在到达最终目的地之前会通过多个代理传播。即下一个Source的源可能是上一个sink的输出
设置代理Agent
Flume代理配置存储在本地配置文件中。这是遵循Java属性文件格式的文本文件。可以在同一配置文件中指定一个或多个代理的配置。配置文件包括代理中每个源,接收器和通道的属性,以及它们如何连接在一起以形成数据流。
设置单个组件
流中的每个组件(源,接收器或通道)都有一个名称,类型和特定于该类型和实例化的属性集。例如,Avro源需要一个主机名(或IP地址)和一个接收数据的端口号。一个内存通道可以具有最大队列大小(“容量”),并且HDFS接收器需要知道文件系统URI,创建文件的路径,文件旋转的频率(“ hdfs.rollInterval”)等。组件的所有此类属性都需要在托管Flume代理的属性文件中设置。
核心组件
- Source 收集
- Channel 聚集
- Sink 输出
Flume Source
-
Avro source
侦听Avro端口并从外部Avro客户端流接收事件。与另一个(以前的跃点)Flume代理上的内置Avro Sink配对时,它可以创建分层的集合拓扑
-
Thrift source
监听Thrift端口并接收来自外部Thrift客户端流的事件。与另一个(以前的跃点)Flume代理上的内置ThriftSink配对时,它可以创建分层的集合拓扑。可通过启用kerberos身份验证将节俭源配置为以安全模式启动。 agent-principal和agent-keytab是Thrift源用来验证kerberos KDC的属性
-
Exec source
Exec源代码在启动时运行给定的Unix命令,并期望该过程在标准输出上连续产生数据(除非将属性logStdErr设置为true,否则将直接丢弃stderr)。如果该过程由于某种原因而退出,则源也将退出,并且将不再产生任何数据。这意味着诸如cat [命名管道]或tail -F [file]之类的配置将产生期望的结果,而日期可能不会-前两个命令产生数据流,而后者则产生单个事件并退出。
-
JMS Source
JMS源从JMS目的地(如队列或主题)读取消息。作为一个JMS应用程序,它应该可以与任何JMS提供者一起工作,但是只在ActiveMQ中测试过
-
Kafka source
Kafka Source是Apache Kafka使用者,可从Kafka主题读取消息。如果您有多个运行的Kafka源,则可以为它们配置相同的使用者组,以便每个源都可以读取主题的唯一一组分区。当前支持Kafka服务器0.10.1.0或更高版本。测试已完成至2.0.1,这是发行时的最高可用版本
-
NetCat TCP Source
类似于netcat的源,它在给定的端口上侦听并将文本的每一行转换为一个事件。行为类似于nc -k -l [host] [port]。换句话说,它打开一个指定的端口并监听数据。期望提供的数据是换行符分隔的文本。每行文本都会变成Flume事件,并通过连接的通道发送
-
Http Source
一个通过HTTP POST和GET接受Flume事件的源。GET应该只用于实验。HTTP请求通过一个可插拔的“处理程序”转换为flume事件,该“处理程序”必须实现HTTPSourceHandler接口。这个处理程序接受一个HttpServletRequest并返回一个flume事件列表。通过一个Http请求处理的所有事件都在一个事务中提交给通道,从而提高了通道(如文件通道)的效率。如果处理程序抛出异常,此源将返回HTTP状态400。如果通道已满,或者源无法将事件追加到通道,则源将返回HTTP 503—暂时不可用状态。
在一个post请求中发送的所有事件都被认为是一个批处理,并在一个事务中插入到通道中。
Flume sink
-
HDFS Sink
此接收器将事件写入Hadoop分布式文件系统(HDFS)。它目前支持创建文本和序列文件。它支持这两种文件类型的压缩。可以根据经过的时间、数据的大小或事件的数量周期性地滚动文件(关闭当前文件并创建一个新文件)。它还根据事件起源的属性(如时间戳或机器)存储/分区数据。HDFS目录路径可能包含格式化转义序列,这些转义序列将被HDFS接收器替换,以生成一个目录/文件名来存储事件。使用这个接收器需要安装hadoop,以便Flume可以使用hadoop jar与HDFS集群通信。注意,需要一个支持sync()调用的Hadoop版本。
-
Hive Sink
此接收器将包含分隔文本或JSON数据的事件直接流到Hive表或分区中。事件是使用Hive事务编写的。只要将一组事件提交到Hive,它们就会立即对Hive查询可见。flume将流向的分区可以预先创建,也可以在分区缺失的情况下创建。来自传入事件数据的字段被映射到Hive表中相应的列
-
Logger Sink
记录信息级别的事件。通常用于测试/调试。所需属性以粗体显示。这个接收器是唯一不需要额外配置的例外,这在日志原始数据部分有解释。
-
avro sink
这个接收器构成了Flume分层收集支持的一半。发送到此接收器的Flume事件被转换为Avro事件并发送到配置的主机名/端口对。事件以配置的批大小批量从配置的通道中获取
-
Thrift sink
这个接收器构成了Flume分层收集支持的一半。发送到此接收器的Flume事件被转换为Thrift事件并发送到配置的主机名/端口对。事件以配置的批大小批量从配置的通道中获取。
可以通过启用kerberos身份验证将Thrift sink配置为以安全模式启动。要与在安全模式下启动的勤俭资源通信,勤俭接收器也应该在安全模式下运行。客户机-principal和客户机-keytab是Thrift sink用来验证kerberos KDC的属性。server-principal表示此接收器配置为以安全模式连接的勤俭资源的主体
-
File Roll Sink
将事件存储在本地文件系统上
-
Null sink
放弃从频道收到的所有事件
-
HBase Sink
这个接收器将数据写入HBase。Hbase配置是从类路径中遇到的第一个Hbase -site.xml获得的。由配置指定的实现HbaseEventSerializer的类用于将事件转换为HBase put和/或增量。然后将这些put和增量写入HBase。这个接收器提供了与HBase相同的一致性保证,HBase目前是行原子性。如果Hbase不能写入某些事件,接收器将重播该事务中的所有事件。
HBaseSink支持写数据来保护HBase。要写以保护HBase,代理运行的用户必须具有对接收器配置为写的表的写权限。可以在配置中指定用于根据KDC进行身份验证的主体和keytab。Flume代理的类路径中的HBase -site.xml必须将身份验证设置为kerberos(有关如何进行身份验证的详细信息,请参阅HBase文档)。
为了方便,两个序列化器提供了水槽。SimpleHbaseEventSerializer (org.apache.flume.sink.hbase.SimpleHbaseEventSerializer)按原样将事件体写入HBase,并可选择在HBase中增加一列。这主要是一个示例实现。RegexHbaseEventSerializer (org.apache.flume.sink.hbase.RegexHbaseEventSerializer)根据给定的regex分解事件体,并将每个部分写到不同的列中。
FQCN的类型是: org.apache.flume.sink.hbase.HBaseSink。
-
Elasticsearch Sink
此接收器将数据写入到elasticsearch集群。默认情况下,事件将被写入,以便Kibana图形界面可以显示它们——就像logstash编写它们一样。
环境所需的elasticsearch和lucene-core jar必须放在Apache Flume安装的lib目录中。Elasticsearch要求客户机JAR的主版本与服务器的主版本匹配,并且两者都运行相同的JVM的次版本。如果不正确,将出现serializationexception。要选择所需的版本,首先要确定elasticsearch的版本和目标集群正在运行的JVM版本。然后选择一个与主版本匹配的elasticsearch客户端库。0.19。x客户端可以与0.19对话。x集群;0.20。x可以和0。20通话。0.90 x和。x可以是0。90。确定了elasticsearch版本之后,读取pom.xml文件以确定要使用的正确的lucene-core JAR版本。运行ElasticSearchSink的Flume代理也应该与目标集群运行到次要版本的JVM匹配。
事件将每天写入一个新索引。名称将是-yyyy-MM-dd,其中是indexName参数。接收器将在UTC午夜开始写入新索引。
默认情况下,ElasticSearchLogStashEventSerializer会为elasticsearch序列化事件。可以使用序列化器参数覆盖此行为。该参数接受org.apache.flume.sin .elasticsearch的实现。ElasticSearchEventSerializer或org.apache.flume.sink.elasticsearch.ElasticSearchIndexRequestBuilderFactory。实现ElasticSearchEventSerializer是不赞成的,支持更强大的ElasticSearchIndexRequestBuilderFactory。
类型是FQCN: org.apache.flume.sink.elasticsearch.ElasticSearchSink
-
KafKa Sink
这是一个可以将数据发布到Kafka主题的水槽实现。目标之一是将水槽与Kafka集成,这样基于拉的处理系统可以处理来自不同水槽源的数据。
这目前支持Kafka服务器版本0.10.1.0或更高。测试完成到2.0.1,这是在发布时最高的可用版本。
Flume Channels
- Memory Channel
- JDBC Channel
- KafKa Channel
- File Channel
- …
环境部署
安装前置条件
- Java Runtime Environment - Java 1.8 or later
- Memory - Sufficient memory for configurations used by sources, channels or sinks
- Disk Space - Sufficient disk space for configurations used by channels or sinks
- Directory Permissions - Read/Write permissions for directories used by agent
-
安装jdk1.8
解压开 配置环境变量即可
-
安装Flume
同样以cdh5.7.0为例,所以Flume版本http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.7.0.tar.gz
解压开 配置环境变量即可
# 进入$FLUME_HOME/conf下
cp flume-env.sh.template flume-env.sh
## 将JAVA_HOME配置到 flume-env.sh中
## 检验Flume是否安装成功
## 进入$FLUME_HOME/bin下 执行
./flume-ng -version
Flume实战
- 需求:从指定网络端口采集数据输出到控制台
使用Flume的关键就是写配置文件
- 配置Source
- 配置Channel
- 配置Sink
- 把以上三个组件串起来
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
# 将source、channel、sink绑定起来
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
其中,此配置定义了一个名为a1的代理。 a1具有侦听端口44444上的数据的源,在内存中缓冲事件数据的通道以及将事件数据记录到控制台的接收器。配置文件为各个组件命名,然后描述它们的类型和配置参数。给定的配置文件可能会定义几个命名的代理。当启动给定的Flume进程时,会传递一个标志,告诉它要显示哪个命名的代理。
a1: agent的名称
r1:source的名称
k1:sink的名称
c1: Channel的名称
一个source可以对应多个channel,但是一个channel只能对应一个sink
配置文件好了之后(命名为example.conf),可以将其放在$Flume_Home/conf下
bin/flume-ng agent \
-n a1 \ ## -n 即name,agent的名称
-c $Flume_Home/conf \ # 配置文件所在的文件夹
-f $Flume_Home/conf/example.conf \ ##指定一个配置文件
-Dflume.root.logger=INFO,console #将日志文件打出来
注意:命令行中指定的agent名称要与配置文件中的对应
Event是Flume数据传输的基本单元,如Event: { headers:{} body: 6E 69 68 61 6F 20 77 6F 6A 69 75 73 68 69 77 6F nihao wojiushiwo }
Event=可选的header+byte array
测试:
使用telnet进行测试(因为Flume监听的是44444端口):telnet hadoop000 44444
telnet通之后 输入的内容会被flume收集到
-
需求:监控一个文件实时采集新增的数据输出到控制台
a1.sources=exec-source a1.sinks=logger-sink a1.channels=memory-channel a1.sources.exec-source.type=exec a1.sources.exec-source.command=tail -F ~/home/data/console.log a1.sources.exec-source.shell=/bin/bash -c a1.sinks.logger-sink.type=logger a1.channels.memory-channel.type=memory a1.sources.exec-source.channels=memory-channel a1.sinks.logger-sink.channel=memory-channel可去官网查找 适合场景的source/memory/sink
-
需求:将A服务器上的日志实时采集到B服务器
日志收集过程:
- 机器A上监控一个文件。当我们访问主站时会有用户行为日志记录到access.log中
- avro sink把新产生的日志输出到对应的avro source指定的hostname和port上
- 通过avro source对应的agent将我们的日志输出到控制台或kafka
根据需求,我们需要两个配置文件,分别在服务器A上和服务器B上,服务器A上是发送信息,服务器B是接收消息
服务器A 采用exec-memory-avro模型
a1.sources=exec-source a1.channels=memory-channel a1.sinks=avro-sink a1.sources.exec-source.type=exec a1.sources.exec-source.command =tail -F ~/data/data.log a1.sources.exec-source.shell=/bin/bash -c a1.channels.memory-channel.type=memory a1.sinks.avro-sink.type=avro a1.sinks.avro-sink.hostname=hadoop000 a1.sinks.avro-sink.port=44444 a1.sources.exec-source.channels=memory-channel a1.sinks.avro-sink.channel-memory0-channel服务器B接收消息,采用avro-memory-logger模型
a2.sources=avro-source a2.channels=memory-channel a2.sinks=logger-sink a2.sources.avro-source.type=avro a2.sources.avro-source.bind =hadoop000 a2.sources.avro-source.port=44444 a2.channels.memory-channel.type=memory a2.sinks.logger-sink.type=logger a2.sources.avro-source.channels=memory-channel a2.sinks.logger-sink.channel-memory0-channel启动flume时,先启动接收消息端,再启动发送消息端,否则会出现消息已发送,而没被接收的情况
../bin/flume-ng agent \ --name a2 \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/conf/avro-memory-logger.conf../bin/flume-ng agent \ --name a1 \ --conf $FLUME_HOME/conf \ --conf-file $FLUME_HOME/conf/exec-memory-avro.conf \ -Dflume.root.logger=INFO,console
