版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012292754/article/details/83345529
1 flume 配置文件
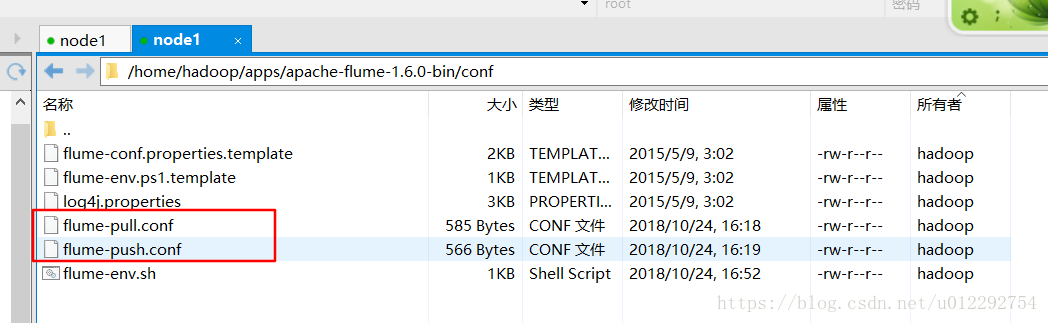
在 flume-env.sh 里配置 JAVA_HOME
1.1 flume-pull.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /export/data/flume
a1.sources.r1.fileHeader = true
# Describe the sink
a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink
a1.sinks.k1.hostname = node1
a1.sinks.k1.port = 8888
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
1.2 flume-push.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /export/data/flume
a1.sources.r1.fileHeader = true
# Describe the sink
a1.sinks.k1.type = avro
#这是接收方
a1.sinks.k1.hostname = 192.168.30.1
a1.sinks.k1.port = 8888
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2 push 案例
2.1 pom
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-flume_2.10</artifactId>
<version>1.6.3</version>
</dependency>
2.2 源码
package streamingAndflume
import mystreaming.LoggerLevels
import org.apache.spark.SparkConf
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object FlumePushCount {
def main(args: Array[String]): Unit = {
LoggerLevels.setStreamingLogLevels()
val conf = new SparkConf().setAppName("FlumePush").setMaster("local[2]")
val ssc = new StreamingContext(conf,Seconds(5))
//flume 向 spark 发送信息,此处IP地址是本机电脑IP
val flumeStream = FlumeUtils.createStream(ssc,"192.168.30.1",8888)
//flume 中的数据通过event.getBody()才能拿到真正的内容
val words = flumeStream.flatMap(x=>new String(x.event.getBody().array()).split(" ")).map((_,1))
val results = words.reduceByKey(_+_)
results.print()
ssc.start()
ssc.awaitTermination()
}
}
2.3 启动 flume
在 /export/data/flume 放一些 数据
[hadoop@node1 apache-flume-1.6.0-bin]$ bin/flume-ng agent -n a1 -c conf -f conf/flume-push.conf
3 poll 方式
需要为在flume lib 下添加相应的 jar 包
参考链接https://spark.apache.org/docs/latest/streaming-flume-integration.html
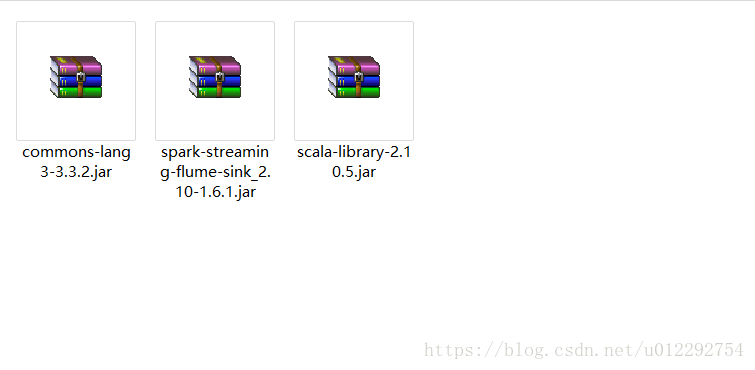
3.1 poll源码
package streamingAndflume
import java.net.InetSocketAddress
import mystreaming.LoggerLevels
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object FlumePollCount {
def main(args: Array[String]): Unit = {
LoggerLevels.setStreamingLogLevels()
val conf = new SparkConf().setAppName("FlumePush").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(5))
//从 flume 中拉取数据,flume的地址,这里可以传很多地址
val address = Seq(new InetSocketAddress("node1",8888))
val flumeStream = FlumeUtils.createPollingStream(ssc,address,StorageLevel.MEMORY_AND_DISK)
val words = flumeStream.flatMap(x=>new String(x.event.getBody().array()).split(" ")).map((_,1))
val results = words.reduceByKey(_+_)
results.print()
ssc.start()
ssc.awaitTermination()
}
}
3.2 先启动flume,再启动程序
[hadoop@node1 apache-flume-1.6.0-bin]$ bin/flume-ng agent -n a1 -c conf -f conf/flume-pull.conf
4 pull 方式在集群中运行
启动 Spark 集群[hadoop@node1 apache-flume-1.6.0-bin]$ /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/sbin/start-all.sh
4.1 源码
源码用 maven 打包
package streamingAndflume
import mystreaming.LoggerLevels
import org.apache.spark.SparkConf
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object FlumePushCount {
def main(args: Array[String]): Unit = {
LoggerLevels.setStreamingLogLevels()
val host = args(0)
val port = args(1).toInt
val conf = new SparkConf().setAppName("FlumePush")
val ssc = new StreamingContext(conf,Seconds(5))
//flume 向 spark 发送信息,此处IP地址是本机电脑IP
val flumeStream = FlumeUtils.createStream(ssc,host,port)
//flume 中的数据通过event.getBody()才能拿到真正的内容
val words = flumeStream.flatMap(x=>new String(x.event.getBody().array()).split(" ")).map((_,1))
val results = words.reduceByKey(_+_)
results.print()
ssc.start()
ssc.awaitTermination()
}
}
4.2 启动 jar
修改 flume-push.conf
a1.sinks.k1.hostname = node2
[hadoop@node1 ~]$ /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/bin/spark-submit --master spark://node1:7077 --class streamingAndflume.FlumePushCount /home/hadoop/push.jar node2 8888
4.3 启动 flume
[hadoop@node1 apache-flume-1.6.0-bin]$ bin/flume-ng agent -n a1 -c conf -f conf/flume-pull.conf