文章目录
官方文档
http://spark.apache.org/docs/2.2.0/streaming-flume-integration.html
Push方式整合之概述
在集群中选择一台这样的机器
- 启动Flume + Spark流媒体应用程序时,必须在该机器上运行其中一个Spark处理程序。
- Flume 可以配置为将数据推送到机器上的端口。
由于采用了推送模型,streaming应用程序需要先启动,接收端被调度并监听所选端口,以便Flume能够推送数据。
Push方式整合之Flume Agent配置开发
Flume Agent的编写: flume_push_streaming.conf
simple-agent.sources = netcat-source
simple-agent.sinks = avro-sink
simple-agent.channels = memory-channel
simple-agent.sources.netcat-source.type = netcat
simple-agent.sources.netcat-source.bind = hadoop000
simple-agent.sources.netcat-source.port = 44444
simple-agent.sinks.avro-sink.type = avro
simple-agent.sinks.avro-sink.hostname = hadoop000
simple-agent.sinks.avro-sink.port = 41414
simple-agent.channels.memory-channel.type = memory
simple-agent.sources.netcat-source.channels = memory-channel
simple-agent.sinks.avro-sink.channel = memory-channel
Push方式整合之Spark Streaming应用开发
添加
<!-- Spark Streaming整合Flume 依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-flume_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
import org.apache.spark.SparkConf
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Spark Streaming整合Flume的第一种方式
*/
object FlumePushWordCount {
def main(args: Array[String]): Unit = {
if(args.length != 2) {
System.err.println("Usage: FlumePushWordCount <hostname> <port>")
System.exit(1)
}
val Array(hostname, port) = args
val sparkConf = new SparkConf() //.setMaster("local[2]").setAppName("FlumePushWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
//TODO... 如何使用SparkStreaming整合Flume
val flumeStream = FlumeUtils.createStream(ssc, hostname, port.toInt)
flumeStream.map(x=> new String(x.event.getBody.array()).trim)
.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()
ssc.start()
ssc.awaitTermination()
}
}
Push方式整合之本地IDEA环境联调
注意此时flume中的simple-agent.sinks.avro-sink.hostname一行应该为
simple-agent.sinks.avro-sink.hostname = 192.168.199.203(IDEA所在机器的ip)
1、运行本地IEDA代码
加上参数本地ip和41414端口
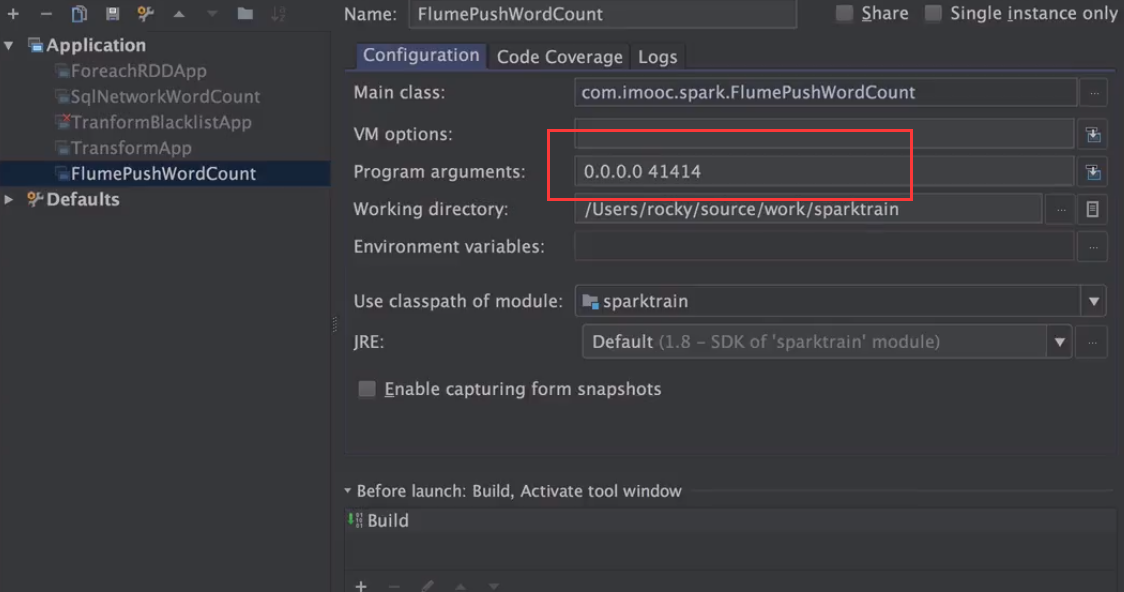
2、运行flume
flume-ng agent \
--name simple-agent \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/flume_push_streaming.conf \
-Dflume.root.logger=INFO,console
3、通过在hadoop000机器上telnet输入数据,观察本地IDEA控制台的输出
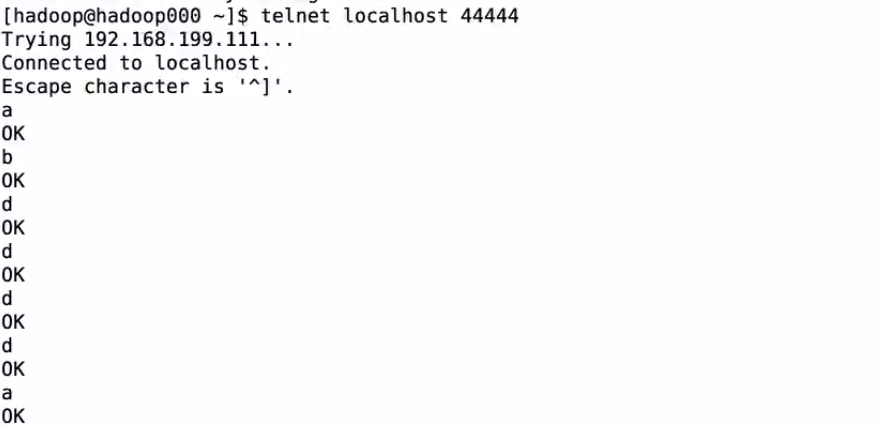
本地测试总结
1)启动sparkstreaming作业
2) 启动flume agent
3) 通过telnet输入数据,观察IDEA控制台的输出
Push方式整合之服务器环境联调
1、使用mvn clean package -DskipTests将本地代码打包上传到生产服务器
2、使用spark-submit提交
注意:–packages org.apache.spark:spark-streaming-flume_2.11:2.2.0将使用的jar包包含进来
–packages是需要在网上下载东西的。
spark-submit \
--class com.imooc.spark.FlumePushWordCount \
--master local[2] \
--packages org.apache.spark:spark-streaming-flume_2.11:2.2.0 \
/home/hadoop/lib/sparktrain-1.0.jar \
hadoop000 41414
3、启动fulme
注意:注意此时flume中的simple-agent.sinks.avro-sink.hostname一行应该为
simple-agent.sinks.avro-sink.hostname = hadoop000
测试步骤和本地IEDA方式一样。
Pull方式整合之概述(推荐)
与直接将数据推送到Sparkstreaming不同,这种方法运行一个自定义的flume,允许以下操作。
- 水槽将数据推入水槽,数据保持缓冲状态。
- Sparkstreaming使用一个可靠的flume接收器和事务从接收器提取数据。只有在通过Sparkstreaming接收和复制数据之后,事务才会成功。
这确保了比前一种方法更强的可靠性和容错保证。但是,这需要配置Flume来运行自定义接收器。
Flume Agent的编写: flume_pull_streaming.conf
simple-agent.sources = netcat-source
simple-agent.sinks = spark-sink
simple-agent.channels = memory-channel
simple-agent.sources.netcat-source.type = netcat
simple-agent.sources.netcat-source.bind = hadoop000
simple-agent.sources.netcat-source.port = 44444
simple-agent.sinks.spark-sink.type = org.apache.spark.streaming.flume.sink.SparkSink
simple-agent.sinks.spark-sink.hostname = hadoop000
simple-agent.sinks.spark-sink.port = 41414
simple-agent.channels.memory-channel.type = memory
simple-agent.sources.netcat-source.channels = memory-channel
simple-agent.sinks.spark-sink.channel = memory-channel
Pull方式整合之Spark Streaming应用开发
pom文件依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-flume-sink_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.5</version>
</dependency>
import org.apache.spark.SparkConf
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Spark Streaming整合Flume的第二种方式
*/
object FlumePullWordCount {
def main(args: Array[String]): Unit = {
if(args.length != 2) {
System.err.println("Usage: FlumePullWordCount <hostname> <port>")
System.exit(1)
}
val Array(hostname, port) = args
val sparkConf = new SparkConf() //.setMaster("local[2]").setAppName("FlumePullWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(5))
//TODO... 如何使用SparkStreaming整合Flume
val flumeStream = FlumeUtils.createPollingStream(ssc, hostname, port.toInt)
flumeStream.map(x=> new String(x.event.getBody.array()).trim)
.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()
ssc.start()
ssc.awaitTermination()
}
}
Pull方式整合之本地IDEA环境联调
注意点:先启动flume 后启动Spark Streaming应用程序
1、启动flume
flume-ng agent \
--name simple-agent \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/conf/flume_pull_streaming.conf \
-Dflume.root.logger=INFO,console
2、启动IEDA的应用程序
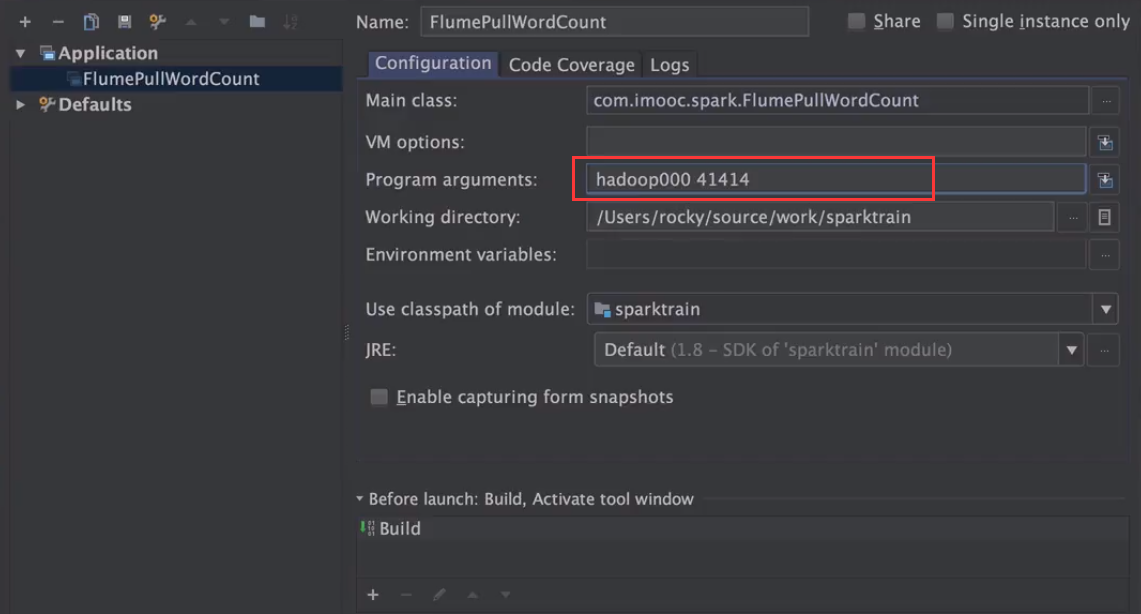
3、测试输入数据
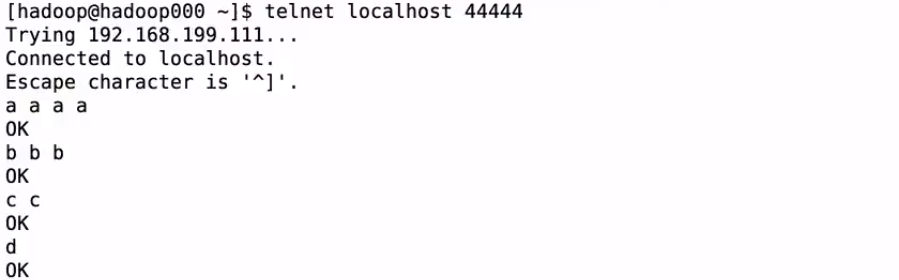
4、查看IDEA控制台会有结果输出
Pull方式整合之服务器环境联调
1、打包IDEA应用程序(方式和push一样)
2、启动flume
3、提交到spark上运行
spark-submit \
--class com.imooc.spark.FlumePullWordCount \
--master local[2] \
--packages org.apache.spark:spark-streaming-flume_2.11:2.2.0 \
/home/hadoop/lib/sparktrain-1.0.jar \
hadoop000 41414
4、使用telnet输入测试数据观察spark-submit的输出