本文就R-CNN论文精读中 的预测框回归(Bounding box regression)问题进行详细讨论。
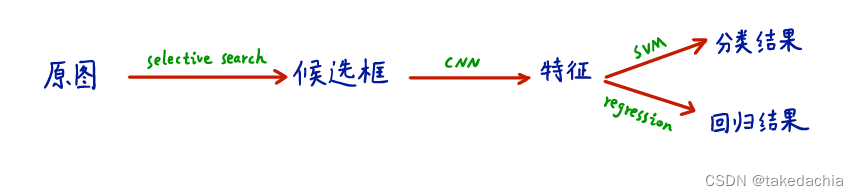
R-CNN将候选框提取出来的特征向量,进行分类+偏移预测的并行处理。
偏移预测即预测框回归(Bounding box regression)问题,我们需要将生成的候选框进行位置、大小的微调。
(图摘自b站up“同济子豪兄”的R-CNN论文解读)
我们需要思考这样一个问题:为什么加入这一个Regression就能修正定位不准的问题呢?
候选框偏移量的预测问题(Bounding box Regression)
因为selective search生成的候选框不可避免地会产生定位误差,所以我们可以对生成的候选框进行偏移修正。
Bounding box regression是延续了DPM算法中(同一个作者)的设计,它通过训练一个线性回归模型,给予一组特征(CNN提取的特征),来预测一个新的检测框,这个新框的偏移量是这个Regression预测的目标。
这个偏移量是相对于正确位置(如Ground Truth框完整地框中某个目标)的偏移量,偏移量通过一组偏移系数计算得到,而偏移系数则是学出来的。
下面结合论文和我的思考细讲一下Bounding box Regression干了一件什么事。
①为什么一个Regression能解决定位不准的问题?
个人觉得这个通过建模来预测候选框的偏移量是一个非常好的思想。在第一遍读论文时,我一直在思考这样的问题:为什么加入这一个Regression就能解决定位不准的问题呢?
试想在训练中,我们设正样本为Ground Truth框,其描述了一只完整的cat的特征;我们的某个候选框和GT框部分重叠,其描述了一只不完整的cat的特征。那么不完整的cat框相对于完整的cat框需要进行一个偏移矫正。比如下图,需要将红框修正到蓝框位置。

我们假设一个候选框的特征向量可以推理出针对某个目标的相对位置信息,举个例子:上图中的红框,没有完全框中猫的尾巴和四肢,那么从红框的特征向量应该可以推断出这只猫的尾巴或者四肢的特征是相对残缺的,那就需要往该特征所在的位置将框扩展,以求特征完整。在这个例子中红框就需要往右上方扩展以追求框中完整的尾巴,同时也需要往下方扩展以追求框中完整的四肢。
注意,该扩展只基于当前红框的特征进行1次偏移预判,当偏移到蓝框后,在该算法中不会就蓝框再进行一次判断是否还需要偏移。文中作者也指出1次偏移调整就够了,多次调整不提升性能。
②对偏移量建模
基于上面的思考,我们就可以将一个候选框提取出的特征向量转化成一个偏移量,来指导当前的候选框进行大小和位置的调整。
一个候选框的定位一般需要4个参数,常用的便是框中心的坐标 ( x , y ) (x, y) (x,y)和框的高宽 ( w , h ) (w, h) (w,h)。那么偏移量为 Δ x , Δ y , Δ w , Δ h Δx, Δy, Δw, Δh Δx,Δy,Δw,Δh。
即: f e a t u r e (如 4096 维向量) → Δ x , Δ y , Δ w , Δ h feature(如4096维向量)→ Δx, Δy, Δw, Δh feature(如4096维向量)→Δx,Δy,Δw,Δh
文中作者使用了相对偏移量,具体为:
设Ground Truth框 G G G的位置信息、候选框 P P P的位置信息为:
G = ( G x , G y , G w , G h ) P = ( P x , P y , P w , P h ) \begin{gathered} G=\left(G_{x}, G_{y}, G_{w}, G_{h}\right) \\ P=\left(P_{x}, P_{y}, P_{w}, P_{h}\right) \end{gathered} G=(Gx,Gy,Gw,Gh)P=(Px,Py,Pw,Ph)
我们的目标就是建立 G G G和 P P P之间的关系。
文中建立了4个偏移系数 t x , t y , t w , t h t_{x}, t_{y}, t_{w}, t_{h} tx,ty,tw,th,作为相对偏移量:
G x = P w t x + P x G y = P h t y + P y G w = P w exp ( t w ) G h = P h exp ( t h ) . \begin{aligned} {G}_{x} &=P_{w} t_{x}+P_{x} \\ {G}_{y} &=P_{h} t_{y}+P_{y} \\ {G}_{w} &=P_{w} \exp \left(t_{w}\right) \\ {G}_{h} &=P_{h} \exp \left(t_{h}\right) . \end{aligned} GxGyGwGh=Pwtx+Px=Phty+Py=Pwexp(tw)=Phexp(th).
而届时在预测时,这个系数 t x , t y , t w , t h t_{x}, t_{y}, t_{w}, t_{h} tx,ty,tw,th应当由候选框 P P P推断出来,那么我们的就应当建立从候选框 P P P抽到的特征 f e a t u r e ( P ) feature(P) feature(P)和 ( t x , t y , t w , t h ) (t_{x}, t_{y}, t_{w}, t_{h}) (tx,ty,tw,th)的关系。
③建立回归模型
我们假设 f e a t u r e ( P ) feature(P) feature(P)和 ( t x , t y , t w , t h ) (t_{x}, t_{y}, t_{w}, t_{h}) (tx,ty,tw,th)存在线性关系,就可以设一个权重 w w w,这样可以建立回归方程:
( t ^ x , t ^ y , t ^ w , t ^ h ) = w ∗ f e a t u r e ( P ) (\hat{t}_{x}, \hat{t}_{y}, \hat{t}_{w}, \hat{t}_{h})=w*feature(P) (t^x,t^y,t^w,t^h)=w∗feature(P)
关于这个回归方程:
- 向量 ( t ^ x , t ^ y , t ^ w , t ^ h ) (\hat{t}_{x}, \hat{t}_{y}, \hat{t}_{w}, \hat{t}_{h}) (t^x,t^y,t^w,t^h)是我们想要预测的4个偏移系数,权重 w w w是我们想要学习的参数。
- 通过②中偏移量的建模,已知一对GT框和候选框的位置信息 ( G , P ) (G, P) (G,P)可解方程算得对应的 ( t x , t y , t w , t h ) (t_{x}, t_{y}, t_{w}, t_{h}) (tx,ty,tw,th),文中设为 t ⋆ t_{\star} t⋆ 。
这样我们就得到了大量 t ⋆ t_{\star} t⋆和 f e a t u r e ( P ) feature(P) feature(P)的训练数据,即可拟合出权重 w w w来。 - 论文中 f e a t u r e ( P ) feature(P) feature(P)是用CNN模型的最后一个池化层抽取到的特征作为特征向量,论文中用 ϕ 5 ( P ) {\phi}_{5}(P) ϕ5(P)表示。
- 论文中,用 d x ( P ) , d y ( P ) , d w ( P ) , d h ( P ) d_{x}(P), d_{y}(P), d_{w}(P), d_{h}(P) dx(P),dy(P),dw(P),dh(P)表示 t ^ x , t ^ y , t ^ w , t ^ h \hat{t}_{x}, \hat{t}_{y}, \hat{t}_{w}, \hat{t}_{h} t^x,t^y,t^w,t^h,代表了回归结果可用P的特征向量线性表示。
④回归模型的训练
我们知道对于线性回归模型,损失函数是和方差SSE或均方误差MSE,且求最佳的 w w w是有解析解的。
对于本例,损失函数可表示为:
w ⋆ = argmin w ^ ⋆ ∑ i N ( t ⋆ i − w ^ ⋆ T ϕ 5 ( P i ) ) 2 \mathbf{w}_{\star}=\underset{\hat{\mathbf{w}}_{\star}}{\operatorname{argmin}} \sum_{i}^{N}\left(t_{\star}^{i}-\hat{\mathbf{w}}_{\star}^{\mathrm{T}} \boldsymbol{\phi}_{5}\left(P^{i}\right)\right)^{2} w⋆=w^⋆argmini∑N(t⋆i−w^⋆Tϕ5(Pi))2
其中:
- i i i代表每个训练样本, t ⋆ t_{\star} t⋆即为相应类别的GT框和候选框 ( G , P ) (G, P) (G,P)求得的偏移系数向量。
- ϕ 5 ( P ) {\phi}_{5}(P) ϕ5(P)如前所述是候选框 P P P经CNN最后一个池化层抽取的特征(即4096维向量)。
- 每个类别都训练一个回归模型,一共20个。
这里,作者为损失函数添加了L2正则项提升模型性能,防止过拟合。作者在文中指出,这个正则化项非常重要,他将 λ \lambda λ设为了1000。
(在统计学中,这也是一个岭回归问题)
最终的待优化函数为:
w ⋆ = argmin w ^ ⋆ ∑ i N ( t ⋆ i − w ^ ⋆ T ϕ 5 ( P i ) ) 2 + λ ∥ w ^ ⋆ ∥ 2 \mathbf{w}_{\star}=\underset{\hat{\mathbf{w}}_{\star}}{\operatorname{argmin}} \sum_{i}^{N}\left(t_{\star}^{i}-\hat{\mathbf{w}}_{\star}^{\mathrm{T}} \boldsymbol{\phi}_{5}\left(P^{i}\right)\right)^{2}+\lambda\left\|\hat{\mathbf{w}}_{\star}\right\|^{2} w⋆=w^⋆argmini∑N(t⋆i−w^⋆Tϕ5(Pi))2+λ∥w^⋆∥2
我们就可以用最小二乘法求得回归系数 w w w的解析解。
训练出 w w w就可以进行偏移的回归预测了
⑤Bounding box Regression的适用条件和注意事项
我们在上面建立的回归模型是基于特征向量和偏移系数存在线性关系这一假设的。线性问题是一个简单问题,有它自己的适用范围。
并且,我们这个回归问题解决的是候选框向GT的微调。如果候选框中特征丢失得太多,也就很难调整过来了。
这决定了在实际的训练中,候选框不能离GT框太远。
作者指出了IoU必须大于0.6的候选框才能用来训练回归器。
此外,在①中已提到,只对候选框进行1次回归,当调整完毕后,不会就调整后的框再进行一次回归。因为作者发现多次微调不提升模型精确度。
最后如下图所示,在推理阶段,这个回归头与前面的SVM头是并行的,同时计算,得出最终检测框的分类和(微调后的)定位。