文章目录
公式输入请参考: 在线Latex公式
词嵌入的由来:
1-of-N Encoding
apple=[1 0 0 0 0]
bag=[0 1 0 0 0]
cat=[0 0 1 0 0]
dog=[0 0 0 1 0]
elephant=[0 0 0 0 1]
这种词表示方式缺点很明显:
维度大
稀疏
各个词之间关系完全被忽略
Word Class
这个是上节课的Dimension Reduction的方法,化繁为简。
| Class1 | Class2 | Class3 |
|---|---|---|
| dog cat bird | ran jumped walk | flower tree apple |
但是这个方法也没有办法表示Class之间的关系,例如第二个class是第一个class可以做的事情。
Word Embedding
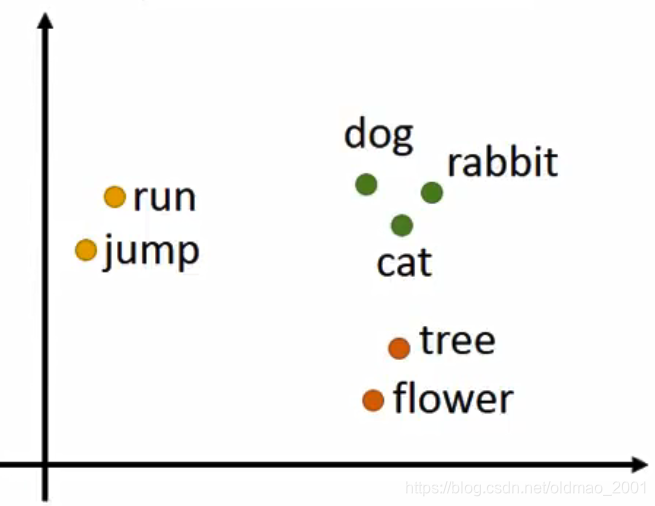
一看就知道这个方法维度比1-of-N Encoding要少很多很多。
Word Embedding咋做
Word Embedding是一种非监督的机器学习方法(Generating Word Vector is unsupervised)。做法很简单,就是让Machine 阅读很多的文章,自然会知道词的Embedding是什么样子。
Machine learn the meaning of words from reading a lot of documents without supervision
它的输入是一个词,输出是一个词对应的向量。
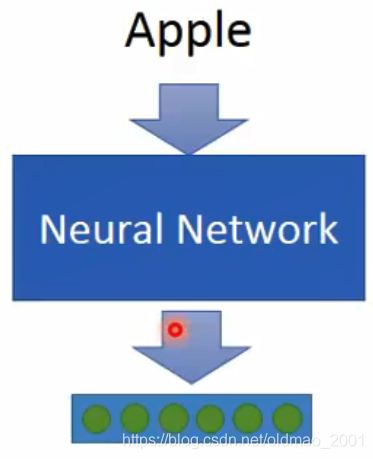
在训练的过程中,我们只知道输入,不知道输入对应的输出是什么,那如何找到这个function呢?
A word can be understood by its context
You shall know a word by the company it keeps
就是要根据上下文去理解词的含义。
例如,让机器学习:

蔡英文、马英九are something very similar
如何找出词的含义有两个方法:
·Count based
If two words
and
frequently co-occur,
and
would be close to each other.
常见的算法是斯坦福的:Glove Vector:
其中心思想是
左边是
的内积,右边是同一个文档中
和
同时出现的次数。
左边和右边越接近越好。
·Perdition based
根据前i-1个词,预测第i个词。
这个算法的输入是:1-of-N Encoding
输出是每一个词作为下一个词出现的概率。
如果有10W个词,那么输出就是10W维。
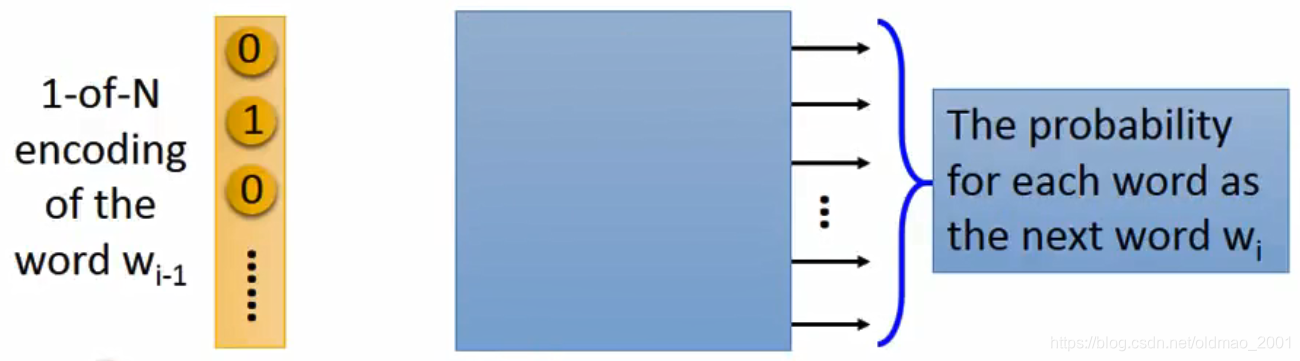
由于输入每个一个词的表示都不一样,所以可以把隐藏层的第一层隐藏层的输入,也就是词嵌入:
Take out the input of the neurons in the first layer. Use it to represent a word
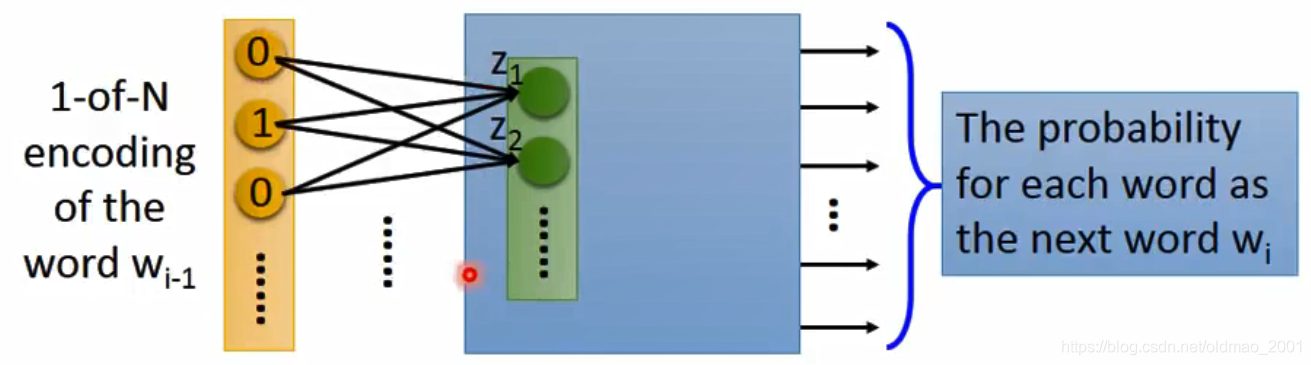
如上图所示,隐藏层的第一层
,
就是词嵌入。咋整的?
例如有两段训练语料:

当无论蔡英文、马英九作为输入的时候,我们都希望模型的输出中,宣誓就职应该有最大的概率是下一个词。那么蔡英文、马英九应该有相似的词嵌入(如下图),才会有这个结果:
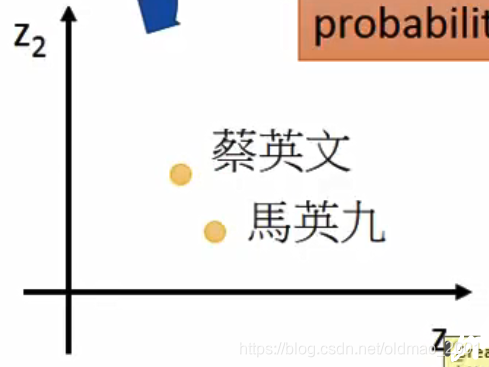
也就是说当一个模型在考虑下一个词的概率的过程中,就自动的把词嵌入给学到了。
扩展
但是只看
,然后预测
,貌似非常困难啊,一个词后面可能出现的词的可能性太多种了,于是对这个算法进行了扩展,例如考虑
和
然后预测
。
模型就变成了这样(把
和
接到一起作为输入):
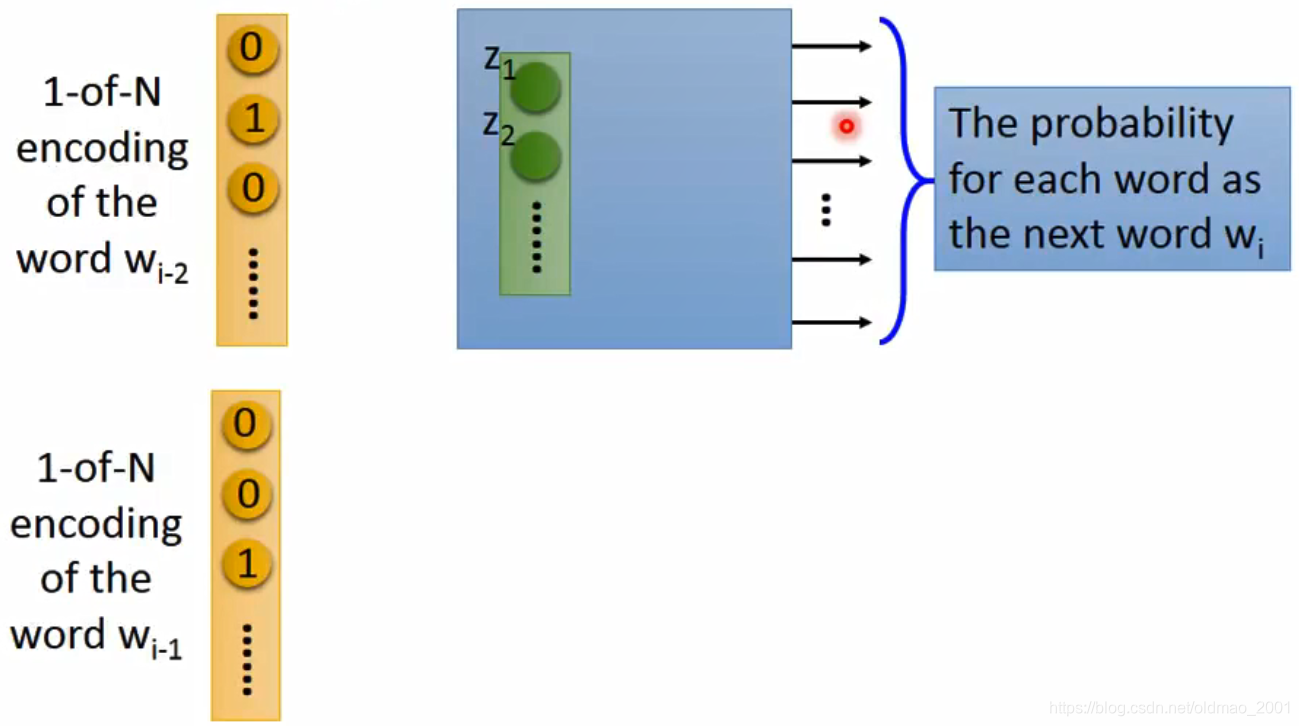
这里需要注意的是,训练的时候,
和
两个向量的第一个位置同时对应隐藏层的
,
,注意看下图的箭头颜色
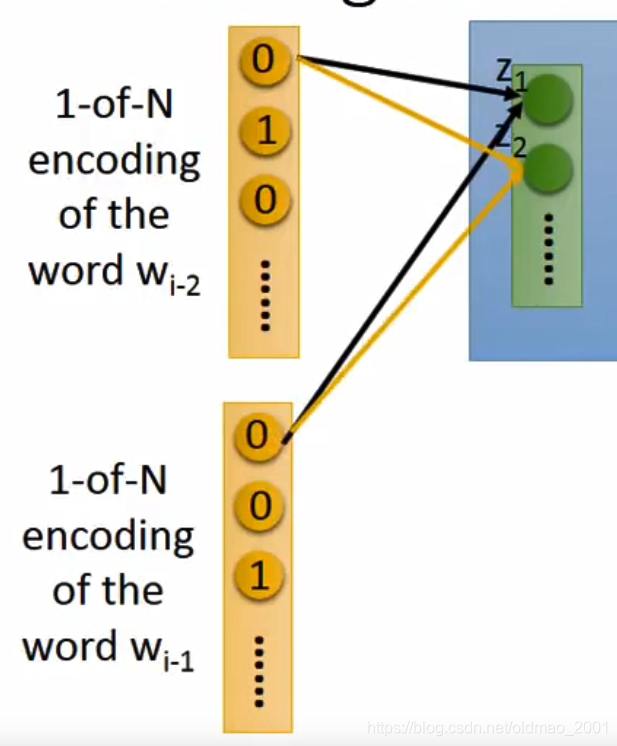
以此类推:
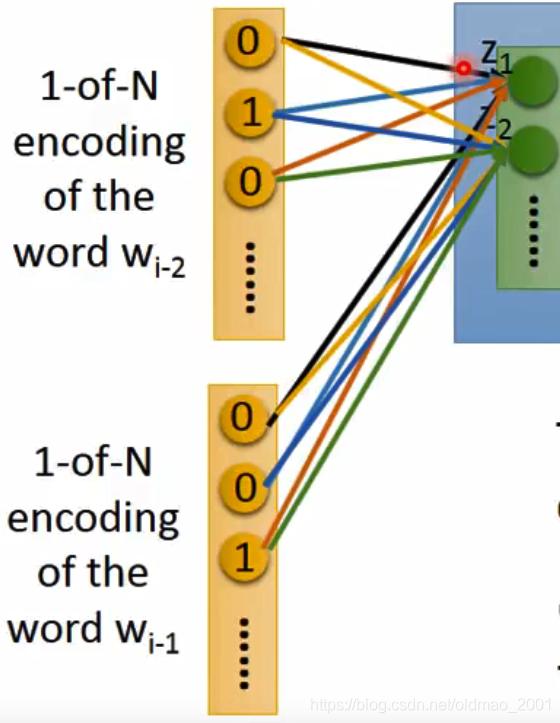
这样做有两个好处:
1、共享参数,减少计算量;
2、一个词对应一个词嵌入,否则会有多个词嵌入。
数学表达
用
表示
,用
表示
,隐藏层的输入用
表示
和
的长度都是
的长度是
他们的关系如下:
其中,权重矩阵
,
的大小都是
这里,我们强制:
现在就是如何使得
原ppt中用的字母有点歧义,我这里先说下,下面的
不是指词,而是指词
对应的参数。
同样
是指词
对应的参数,如下图所示:
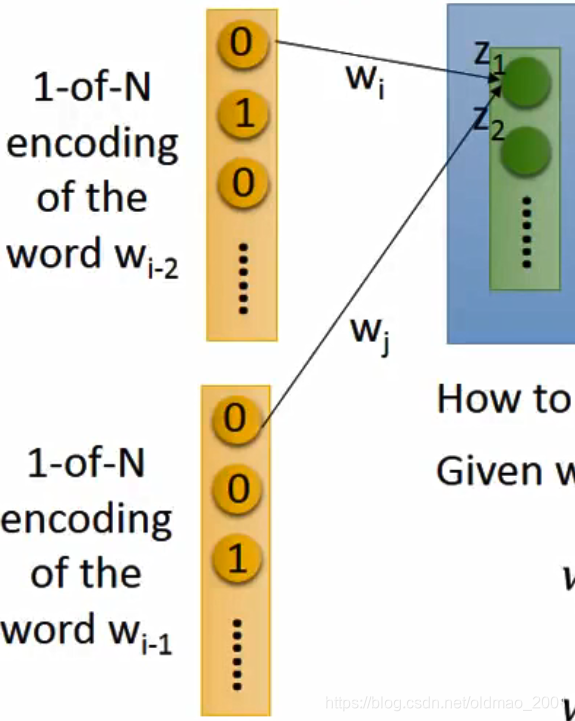
如果要使得
,需要两个步骤:
1、为
和
初始化相同的值
2、在反向传播更新参数采用的公式如下:
训练
首先搜集数据,例如:

然后训练:

红色箭头是代表Minimizing cross entropy关系。
Various Architectures
·Continuous bag of word(CBOW)model
上下文预测中间的词(predicting the word given its context)

·Skip-gram
根据给定词预测上下文(predicting the context given a word)

上面的NN其实只用一层就可以了,这样速度会很快,可以做很多个epoch。
词嵌入的可视化效果
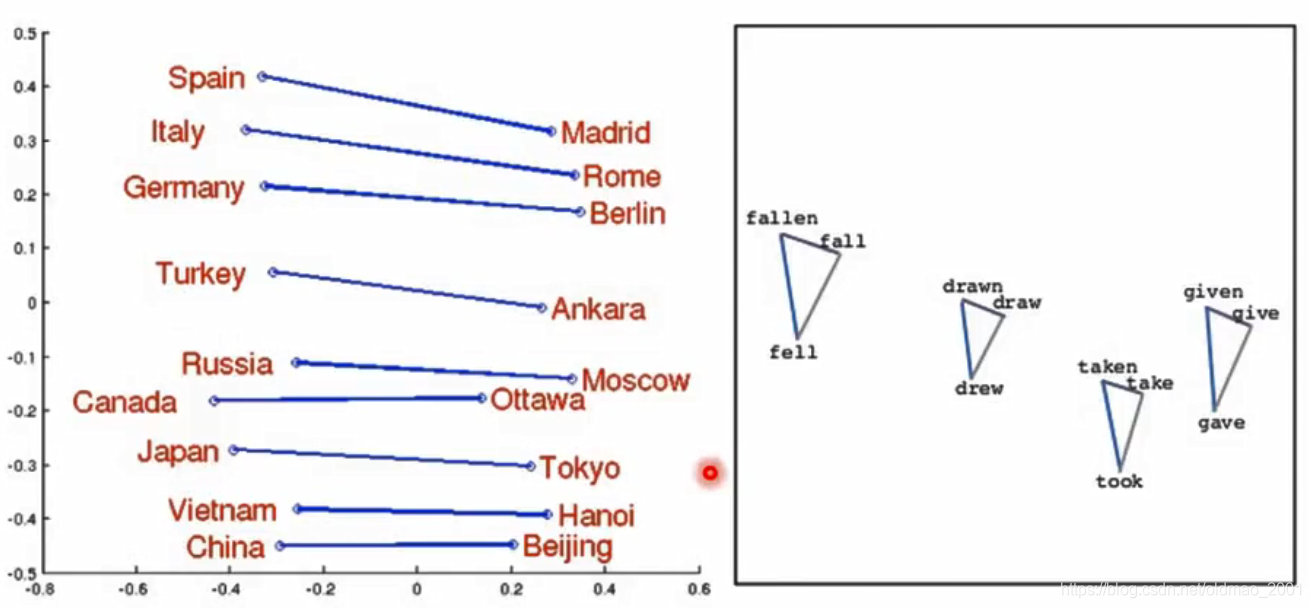
上图是国家和首都的关系,动词的三个时态的关系可视化。
Fu, Ruiji, et al."Learning semantic hierarchies via word embeddings."Proceedings of the 52th Annual Meeting of the Association for Computational Linguistics: Long Papers. Vol.1.2014.
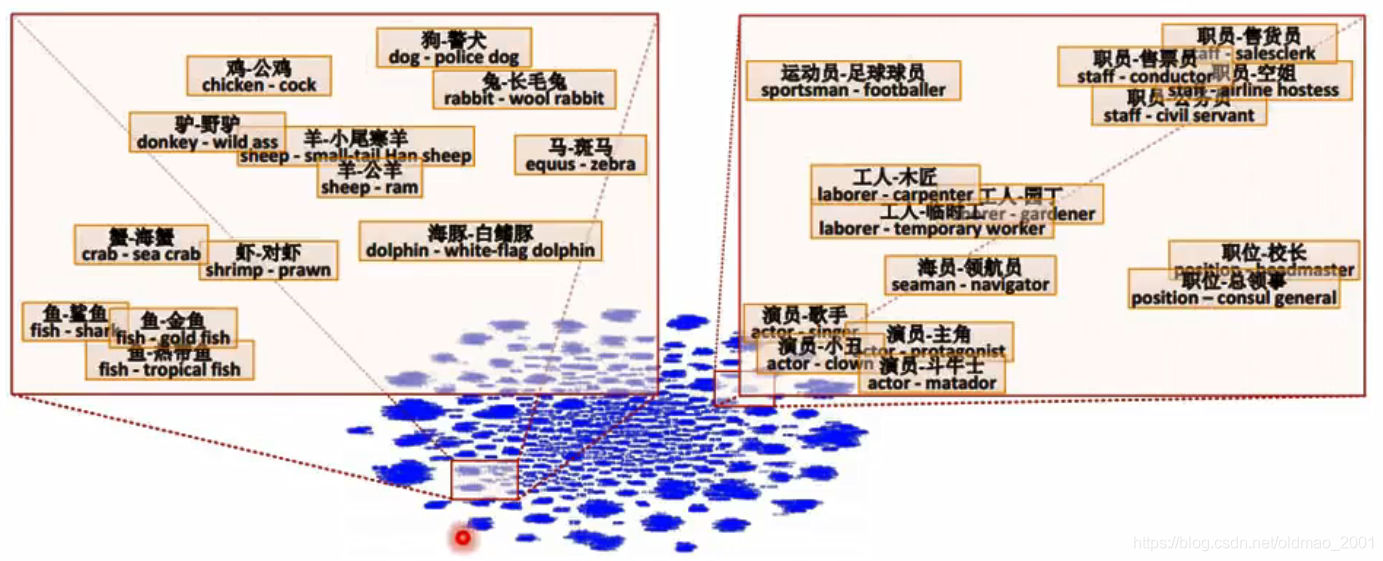
多语言词嵌入
Bilingual Word Embeddings for Phrase-Based Machine Translation, Will Zou, Richard Socher, Daniel Cer and Christopher Manning, EMNLP, 2011

多领域嵌入
Richard Socher, Milind Ganjoo, Hamsa Sridhar, Osbert Bastani, Christopher D.Manning, Andrew Y. Ng, Zero-Shot Learning Through Cross-Modal Transfer, NIPS, 2013

Document Embedding
·word sequences with different lengths ->the vector with the same length

之前把文档转成词袋,然后进行嵌入的方法是有缺陷的:

Reference: Hinton, Geoffrey E., and Ruslan R.Salakhutdinov."Reducing the dimensionality of data with neural networks."Science 313.5786 (2006):504-507
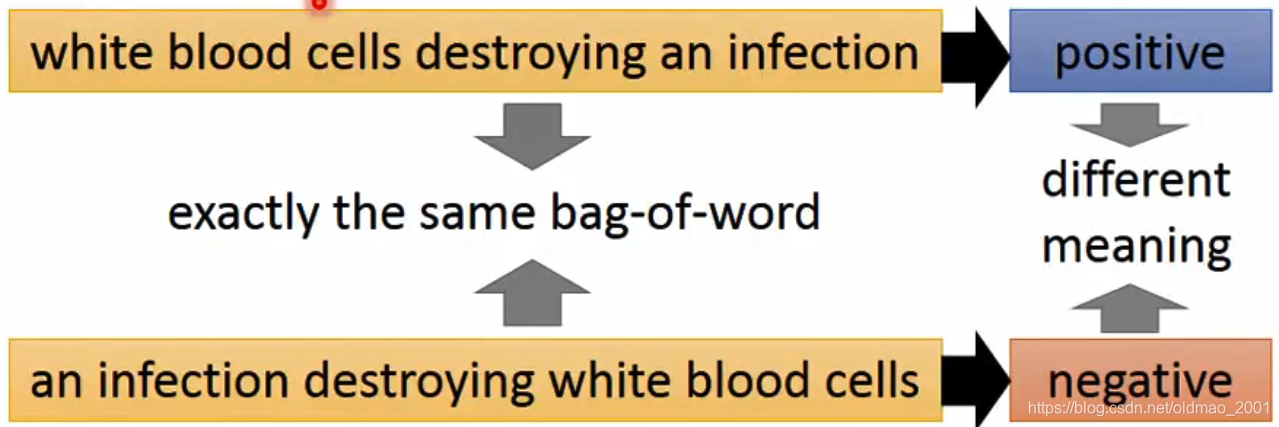
缺点是词袋模型缺乏词的位置信息,这样会有问题,例如:
white blood cells destroying an infection
an infection destroying white blood cells
这两句话用词袋表示的话是一样的
如何解决这个问题老师直接给参考文献,基本在paper带读里面有
· Paragraph Vector: Le, Quoc, and Tomas Mikolov."Distributed Representations of Sentences and Documents."ICML,2014
· Seq2seq Auto-encoder: Li, Jiwei, Minh-Thang Luong, and Dan Jurafsky."A hierarchical neural autoencoder for paragraphs and documents."arXiv preprint, 2015
· Skip Thought:Ryan Kiros, Yukun Zhu, Ruslan Salakhutdinov, Richard S.Zemel, Antonio Torralba, Raquel Urtasun, Sanja Fidler,“Skip-Thought Vectors” arXiv preprint,2015.
以上是无监督的方式
下面是监督的方式
· Huang, Po-Sen, et al."Learning deep structured semantic models for web search using clickthrough data."ACM,2013.
· Shen, Yelong, et al."A latent semantic model with convolutional-pooling structure for information retrieval."ACM,2014.
· Socher, Richard, et al."Recursive deep models for semantic compositionality over a sentiment treebank."EMNLP,2013.
· Tai, Kai Sheng, Richard Socher, and Christopher D. Manning."Improved semantic representations from tree-structured long short-term memory networks."arXiv preprint,2015.
