公式输入请参考: 在线Latex公式
Generative Models
就是致力于让机器自主学习的一些方法,

比较有名的有下面几种:
PixelRNN
Variational Autoencoder(VAE)
Generative Adversarial Network(GAN)
下面大概各自讲一下这些方法的原理
PixelRNN
Ref: Aaron van den Oord, Nal Kalchbrenner, Koray PixelRNN Kavukcuoglu, Pixel Recurrent Neural Networks, arXiv preprint,2016
· To create an image, generating a pixel each time. E.g.3x3 images
先随机弄一个点

然后让模型去预测下一个点是啥。

变成了:



那个绿色的应该是一个RNN,RNN是可以处理变长的输入的模型。

最后是这样:

Can be trained just with a large collection of images without any annotation
这个模型是非监督的。怎么玩?先给一张狗狗的图

然后盖住一半

用这个方法补全下半身:

这个方法除了在图像处理方面的应用之外,还有声音和视频的应用。
Audio:Aaron van den Oord,Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner,Andrew Senior, Koray Kavukcuoglu, WaveNet:A Generative Model for Raw Audio,arXiv preprint,2016
Video:Nal Kalchbrenner,Aaron van den Oord,Karen Simonyan,lvo Danihelka,Oriol Vinyals,Alex Graves,Koray Kavukcuoglu,Video Pixel Networks, arXiv preprint,2016.
二次元高能预警。。。。
为了练习这个模型,老师提出了这个项目。
Pokemon Creation
从792张原有的宝可梦图片学习创建新的宝可梦角色。
口号:Don’t catch them!Create them!
· Source of image: 点我直达
完全没有版权问题
Original image is 40×40,有点大
Making them into 20×20
提示:
之前的输入输出的像素是用一个rgb的向量来表示的,例如:
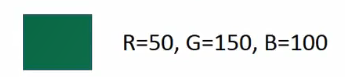
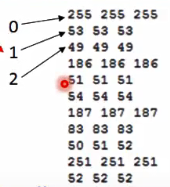
这样有一些问题,当激活函数是sigmoid的时候,输出的值不会是那种极端的0或者1,基本都是在0.5附近,这样图片就是都差不多都是灰色的。
所以把像素使用独热编码表示:

但是颜色太多怎么办,把类似颜色合并:

最后总共可以有167种颜色。
老师贴心的做好了预处理工作。
Original image(40×40):
http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Pokemon_creation/image.rar
Pixels (20×20):
http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Pokemon_creation/pixeIcolor.txt
· Each line corresponds to an image, and each number corresponds to a pixel,独热编码与颜色的对应关系在这里:
http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML_2016/Pokemon_creation/colormap.txt
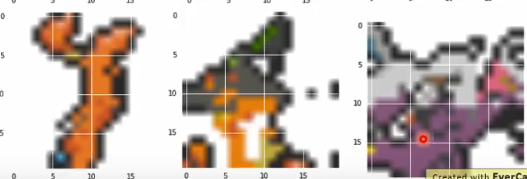
老师的实验结果:
先是盖住一半的宝可梦,valid data,机器没学过的。


Cover 75%

如果全部叫机器自己画会咋样?如果都是机器画,每次的算法模型都一样,画出来的东西也是一样的,所以要加一些随机的东西在里面,本来是去下一个出现几率最大的颜色,但是加上随机变量,取不同颜色,就有了下面的杰作:

Variational Auto Encoder(VAE)
上节刚刚讲完Auto Encoder
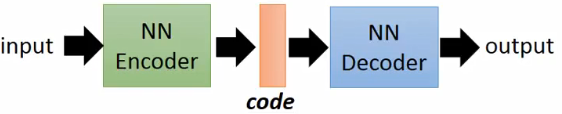
他的生成结果不太好,于是有了VAE。

除了输入输出的误差要最小化之外还要满足一个目标:
为什么要弄这个东西后面会有解释,先来看看VAE在CIFAR-10上做的结果:

https://github.com/openai/iaf
没看出来有什么特别的地方?其实不然,VAE可以让我们控制图片生成的因素,虽然是什么因素还不知道。接下来还是以创造宝可梦项目为例进行说明。

假设这个模型中设定的code是10维的,训练后之后把code和decoder拿出来进行宝可梦生成。
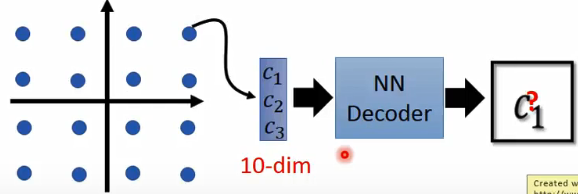
这个过程中我们可以把code中的其中8个维度控制住,然后剩下的两个维度用如图所示的输入逐个输入,然后就可以观察输出的变换。

然后可以从结果中观察出这两维对生成图像的影响。下面是另外两维的生成结果:

Writing Poetry
Ref: http://www.wired.co.uk/article/google-artificial-intelligence-poetry
出自谷歌AI实验室
Samuel R. Bowman, Luke Vilnis, Oriol Vinyals, Andrew M. Dai, Rafal Jozefowicz, Samy Bengio, Generating Sentences from a Continuous Space, arXiv prepring,2015
把输入输出从图片改成句子就可以得到新的应用。

先给定两个句子,然后用模型将句子映射为code,如下图:

然后把两个点连起来,然后等间隔的取若干点,当然了,这些点也是code。

然后把这些code点从模型中reconstruction回句子:

就是论文中所提到的效果,在blog中就是一种形式的诗歌。
