mate learning = learn to learn

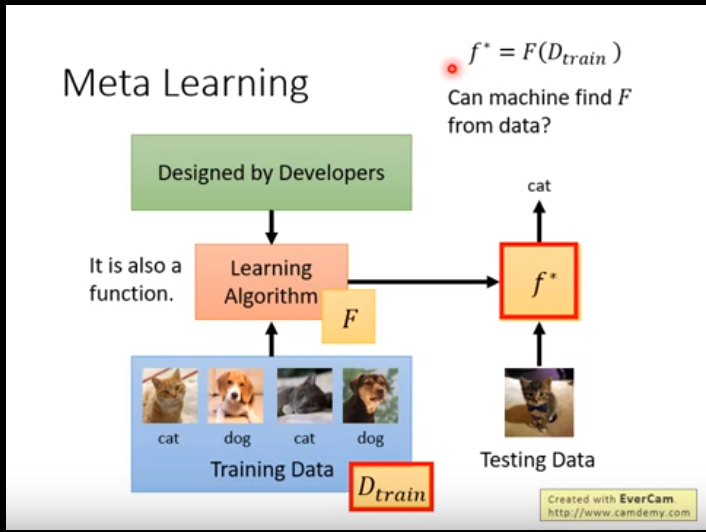
如下图所示,mate learning就是 输入训练资料到 F,输出的是一个可以用来识别图像的 f*。
F(training data) = f (一个神经网络)
而与其他的机器学习模型不同的是,机器学习是训练出来一个模型F,用F来去识别图像。
f(图片 猫)= “cat”
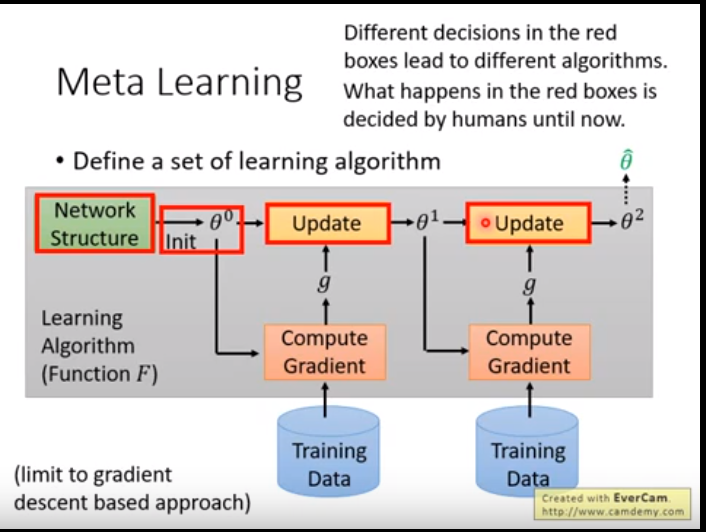
如下图所示,machine learning 的过程是这样的,红色标注的部分都是人为设定的,对于不同的初始化 theta 就会获得不同是训练模型。
思考,如何让初始化参数自己学习出来,而不需要人为的设定?
如何评价F 的好坏,每次从训练集中选取一部分数据用做训练 并对学习出来的f1 做测试 测试结果为l1 这为一个task,然后有很多这样的task
把所有的li 求和 就是对 F 的评价结果,L(F) = Σ(l) 结果小就表示F 效果好,反之。

下图是 对训练数据的划分方式,整体的数据集叫做training set 而每一个task中的数据集叫做 support set 和query set

损失函数

实现mate learning 的两种方法

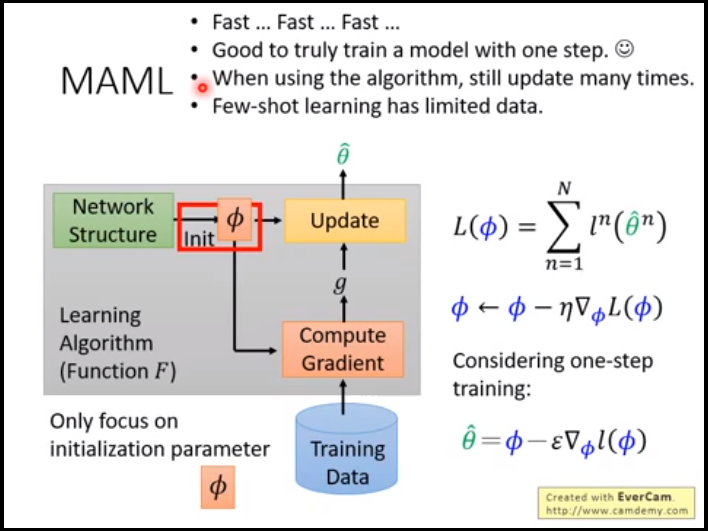
MAML 过程

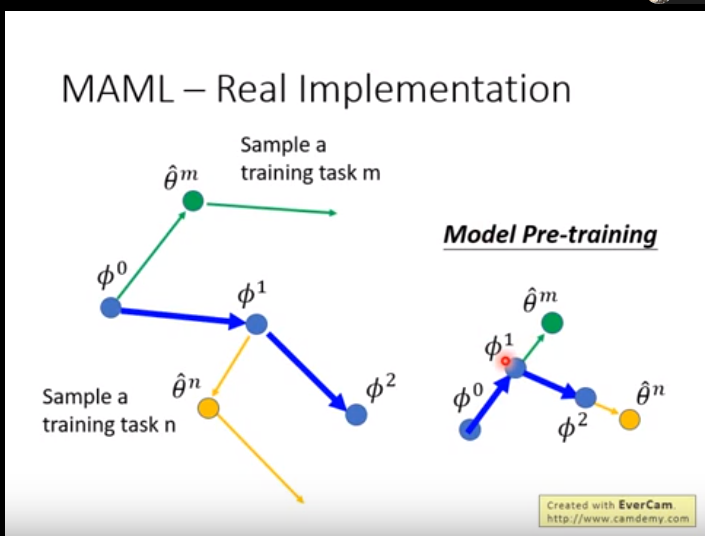
maml 如何求出Φ使用梯度下降;对比预训练和maml之间的区别 可以看出maml是 对每一个task中训练好的模型中的θ求和(绿色符合) 然后求求出F 模型的Φ(蓝色)
而pre_training 是 当前模型的在当前test集合上的Φ 求得。

举例说明这两者的区别,我们不在意Φ在task上是否表现的很好,我们在意的是Φ是否可以训练出好的θ,如下图所示。
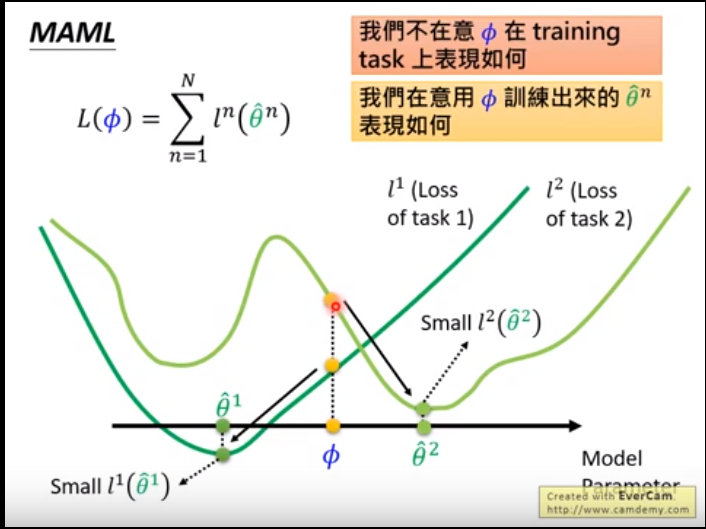
而对于pre-training ,Φ可能在l2上表现的很好,但是放到l1上,它有可能陷入局部最优。
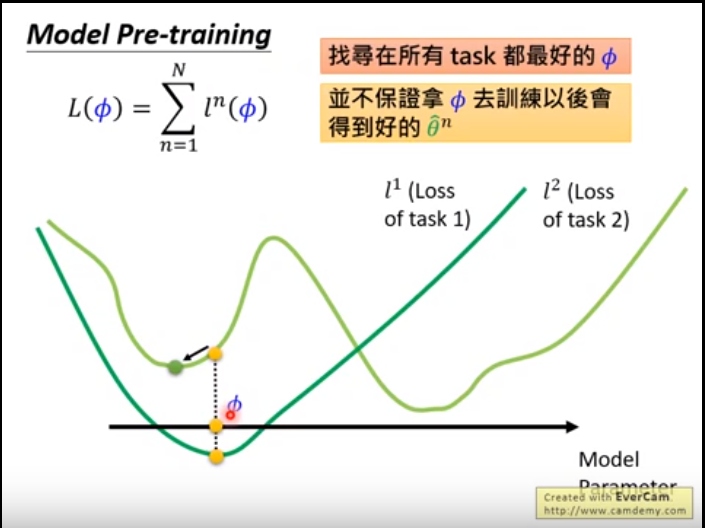
所以总结是:
maml ——> Φ 是看训练后可能达到最好的潜力
pre_train ——> Φ 关注它在当前模型上表现最好
maml 在训练的时候只需要update一次
pre-train 和 maml 比较
数学推导公式


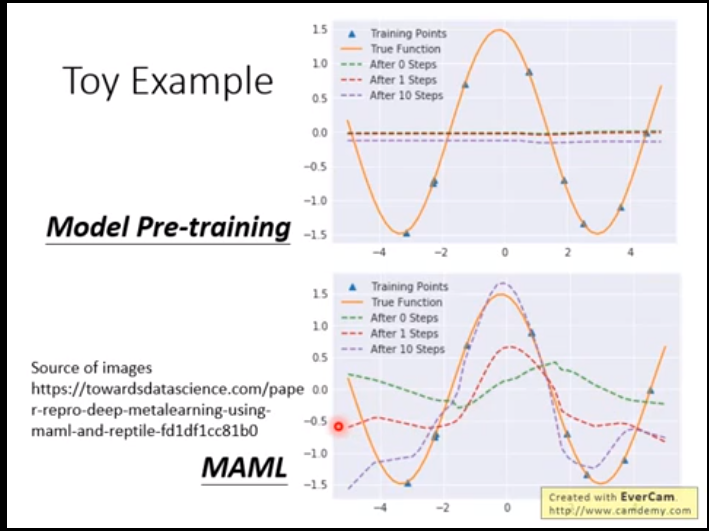
可视化对比两者
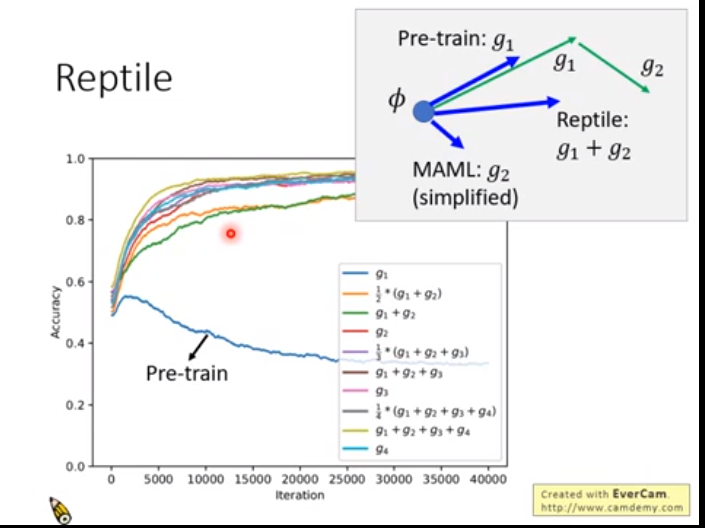
pre-train maml reptile 三者比较
maml 的问题
一开始依然需要初始化 初始化 参数的参数
完!